Exkurs: Item Response Modell für Items mit Visueller Analog Skala als Gemischtes lineares Modell in lme4
Veröffentlichungsdatum
22. Oktober 2024
In der Vorlesung haben wir Gemischte lineare Modelle (LMMs) mit Level-1 Prädiktoren behandelt. Diese Modelle sind sehr flexiblel einsetzbar. Auch einige Modelle der Probabilistischen Testtheorie (synonym: Item Response Modelle) lassen sich im LMM Framework darstellen und deren Parameter somit mit dem lme4 Paket schätzen.
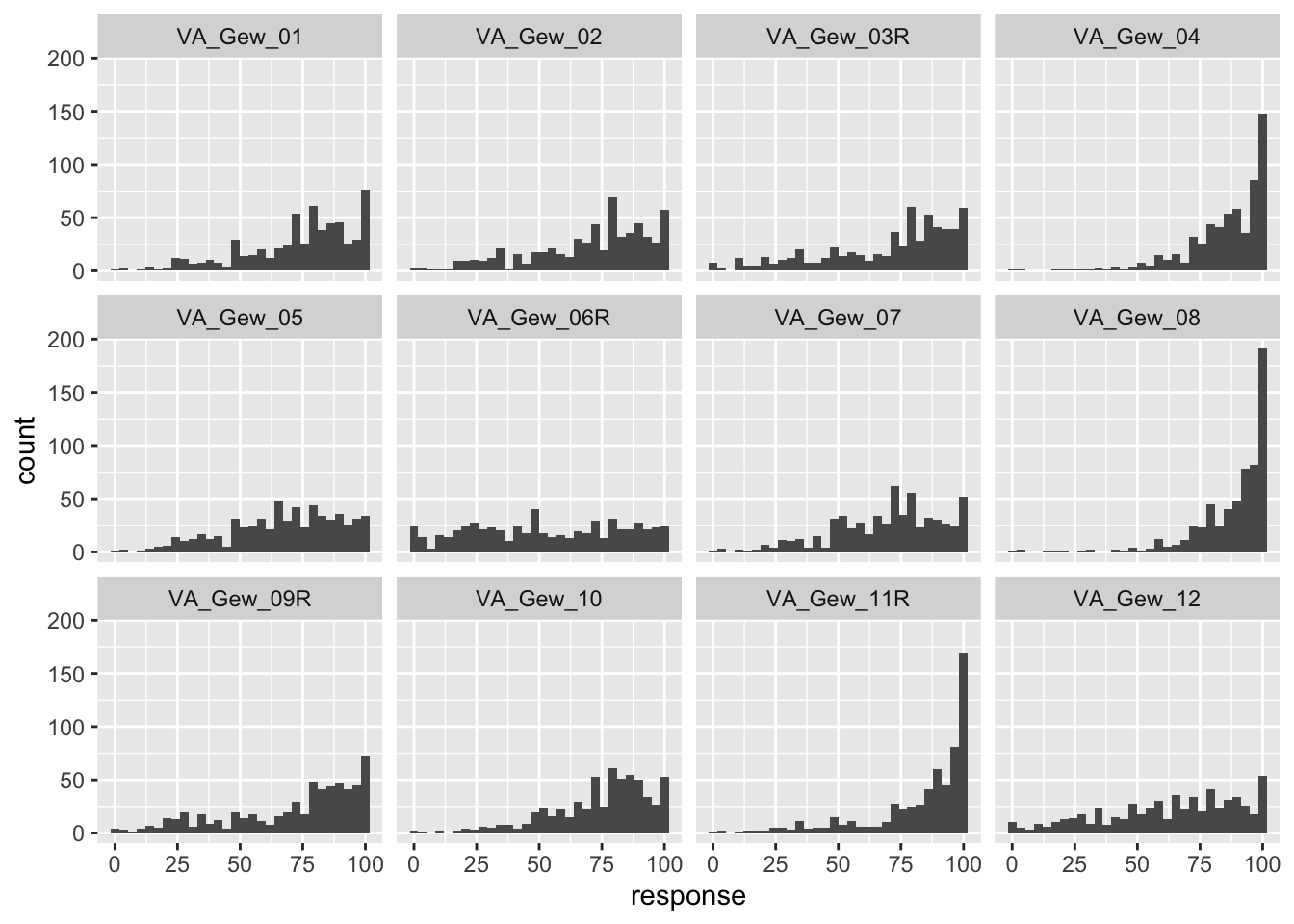
In diesem Exkurs schätzen wir ein eindimensionales Item Response Modell für einen Gewissenhaftigkeitsfragebogen: 12 Items der Skala Gewissenhaftigkeit aus dem NEO-FFI (Borkenau und Ostendorf 1993). Der hier analysierte Datensatz ist ein Ausschnitt (nur Personen die angegeben haben, dass sie den Fragebogen ernsthaft beantwortet haben; nur Personen mit vollständigen Antworten auf der Gewissenhaftigkeitsskala), der Daten in Kuhlmann u. a. (2017). Der komplette Datensatz ist frei verfügbar im OSF(Kuhlmann 2016). Anders als in der Originalversion des Fragebogens wurden die Items in dieser Studie auf einer Visuellen Analogskala von 0 bis 100 mit den beiden Ankern starke Ablehnung und starke Zustimmung beantwortet (siehe Screenshot in Kuhlmann u. a. 2017).
Zuerst laden wir den von uns reduzierten Datensatz VA_Gew_Kuhlmann_et_al.csvhier herunter, lesen die Datei in R ein und verschaffen uns mit der head() Funktion einen kurzen Überblick.
dat <-read.csv2("VA_Gew_Kuhlmann_et_al.csv")head(dat)
Die Items 3, 6, 9 und 11 sind im Datensatz umkodiert, sodass höhere Werte in den Itemantworten für höhere Ausprägungen in Gewissenhaftigkeit sprechen.
Auf Grund der feinen Abstufungen auf der Visuellen Analogskala erscheint es vertretbar, die Itemantworten als kontinuierliche Variablen anzunehmen. Auch wenn die Verteilungen einiger Items (vor allem die Items 4, 8 und 11) sehr schief verteilt sind, werden wir hier die Daten mit einem Gemischten linearen Modell analysieren, welches bekanntermaßen eine Normalverteilung für die Level-1 Fehler annimmt.
Random Intercept Modell ohne Prädiktoren
Wir haben in der Vorlesung Random Intercept Modelle ohne Prädiktoren besprochen. Hier entspräche dies am ehesten einem Modell bei dem nur die Gruppierungsvariable person berücksichtigt wird. Das heißt, die Itemantworten sind geschachtelt in Personen, aber die unterschiedlichen Items werden hier zunächst ignoriert. Damit sieht das Random Intercept Modell ohne Prädiktoren in lme4 folgendermaßen aus:
library(lme4)fit1 <-lmer(response ~1+ (1|person), data = dat)summary(fit1)
Linear mixed model fit by REML ['lmerMod']
Formula: response ~ 1 + (1 | person)
Data: dat
REML criterion at convergence: 66656.8
Scaled residuals:
Min 1Q Median 3Q Max
-3.9116 -0.4880 0.2011 0.6530 2.8285
Random effects:
Groups Name Variance Std.Dev.
person (Intercept) 149.8 12.24
Residual 462.3 21.50
Number of obs: 7320, groups: person, 610
Fixed effects:
Estimate Std. Error t value
(Intercept) 72.5460 0.5556 130.6
Die durchschnittliche Itemantwort (über alle Personen und Items hinweg) beträgt etwa 72.546. Die Varianz für die systematischen Unterschiede zwischen den Personen beträgt etwa 149.807.
Random Intercept Modell mit Items als Prädiktoren
Item Parameter schätzen
Das Random Intercept Modell ohne Prädiktoren ist in diesem Fall wenig informativ. Natürlich wollen wir nicht nur die Personen, sondern auch die Items der Gewissenhaftigkeitsskala getrennt berücksichtigen. Die Personen nehmen wir wie bisher als Random Itercepts ins Modell auf. Das Modell nimmt damit an, dass die systematischen Abweichungen der Personen aus einer Normalverteilung mit Erwartungswert 0 gezogen werden. Diese Annahme ist deshalb sinnvoll, weil die Personen im Datensatz zufällig aus einer Population gezogen wurden. Für die Items könnten wir analog ebenfalls Random Intercepts annehmen. Allerding interessieren wir uns hier eher für die konkreten 12 Gewissenhaftigkeitsitems des NEO-FFIs, die nicht zufällig gezogen sondern immer die gleichen sind. Daher wollen wir die Items vermutlich eher als Fixed Effects aufnehmen, um für jedes konkrete Item einen Schätzwert für die durchschnittliche Itemantwort einer durchschnittlichen Person zu bekommen (ohne Partial Pooling).
Für die kategoriale Variable item verwenden wir im Modell zunächst Dummy Variablen. Wir definieren dafür die Variable in R als factor (wäre hier nicht unbedingt notwendig, da item Text enthält und character Variablen von lmer automatisch in einen Faktor umgewandelt werden).
dat$item <-factor(dat$item)
Wir schätzen nun das folgende Gemischte lineare Modell mit einem Random Intercept Term für person und dem Level-1 Prädiktor item:
Linear mixed model fit by REML ['lmerMod']
Formula: response ~ 1 + item + (1 | person)
Data: dat
REML criterion at convergence: 65063
Scaled residuals:
Min 1Q Median 3Q Max
-3.9675 -0.4922 0.1235 0.6175 3.9353
Random effects:
Groups Name Variance Std.Dev.
person (Intercept) 157.8 12.56
Residual 366.1 19.13
Number of obs: 7320, groups: person, 610
Fixed effects:
Estimate Std. Error t value
(Intercept) 73.4295 0.9268 79.233
itemVA_Gew_02 -3.2689 1.0956 -2.984
itemVA_Gew_03R -3.6721 1.0956 -3.352
itemVA_Gew_04 11.8639 1.0956 10.829
itemVA_Gew_05 -5.9623 1.0956 -5.442
itemVA_Gew_06R -20.4705 1.0956 -18.685
itemVA_Gew_07 -3.5820 1.0956 -3.269
itemVA_Gew_08 15.2459 1.0956 13.916
itemVA_Gew_09R -2.0934 1.0956 -1.911
itemVA_Gew_10 1.1672 1.0956 1.065
itemVA_Gew_11R 10.1803 1.0956 9.292
itemVA_Gew_12 -10.0098 1.0956 -9.137
Durch die automatische Dummy Kodierung wurde von R das erste Item VA_Gew_01 als Referenzkategorie gewählt. Die durchschnittliche Itemantwort einer durchschnittlichen Person auf Item 1 beträgt also etwa 73.43. Die Koeffizienten der restlichen Items stellen somit immer Abweichungen von Item 1 dar, was für die inhaltliche Interpretation als Itemparameter etwas unpraktisch ist. Wir können stattdessen in der Modellsyntax den allgemeinen Intercept weglassen und bekommen damit für jedes Item einen einfach zu interpretierenden geschätzten Itemparameter:
Linear mixed model fit by REML ['lmerMod']
Formula: response ~ 0 + item + (1 | person)
Data: dat
REML criterion at convergence: 65063
Scaled residuals:
Min 1Q Median 3Q Max
-3.9675 -0.4922 0.1235 0.6175 3.9353
Random effects:
Groups Name Variance Std.Dev.
person (Intercept) 157.8 12.56
Residual 366.1 19.13
Number of obs: 7320, groups: person, 610
Fixed effects:
Estimate Std. Error t value
itemVA_Gew_01 73.4295 0.9268 79.23
itemVA_Gew_02 70.1607 0.9268 75.71
itemVA_Gew_03R 69.7574 0.9268 75.27
itemVA_Gew_04 85.2934 0.9268 92.03
itemVA_Gew_05 67.4672 0.9268 72.80
itemVA_Gew_06R 52.9590 0.9268 57.14
itemVA_Gew_07 69.8475 0.9268 75.37
itemVA_Gew_08 88.6754 0.9268 95.68
itemVA_Gew_09R 71.3361 0.9268 76.97
itemVA_Gew_10 74.5967 0.9268 80.49
itemVA_Gew_11R 83.6098 0.9268 90.22
itemVA_Gew_12 63.4197 0.9268 68.43
Zum Beispiel wird die durchschnittliche Itemantwort einer durchschnittlichen Person auf Item 2 hier auf etwa 70.161 geschätzt. Wir sehen an dieser Interpretation, dass in diesem Modell die Itemparameter keine Schwierigkeitsparameter sondern sozusagen Leichtigkeitsparameter darstellen. Je höher der Parameter, desto höher die durchschnittlichen Antworten einer durchschnittlichen Person auf dem Item (d.h. desto “leichter” ist das Item).
Das soeben geschätzte Modell kann als ein einfaches eindimensionales Item Response Modell für die Gewissenhaftigkeitsskala des NEO-FFI interpretiert werden. Da wir nur Random Intercepts aber keine Random Slopes für die Items verwendet haben, nehmen wir an, dass alle Items gleich hoch auf die latente Variable laden. Da die Varianz der Level-1 Fehler nicht von den Items abhängt, nehmen wir außerdem an, dass alle Items die gleiche Fehlervarianz aufweisen.
Personenparameter schätzen
Im Kontext der Item Response Theorie interessieren wir uns typischerweise nicht nur für die Itemparameter (hier die Leichtigkeit jedes Items) sondern auch für die Personenparameter (hier die Ausprägung auf der latenten Variable Gewissenhaftigkeit jeder Person).
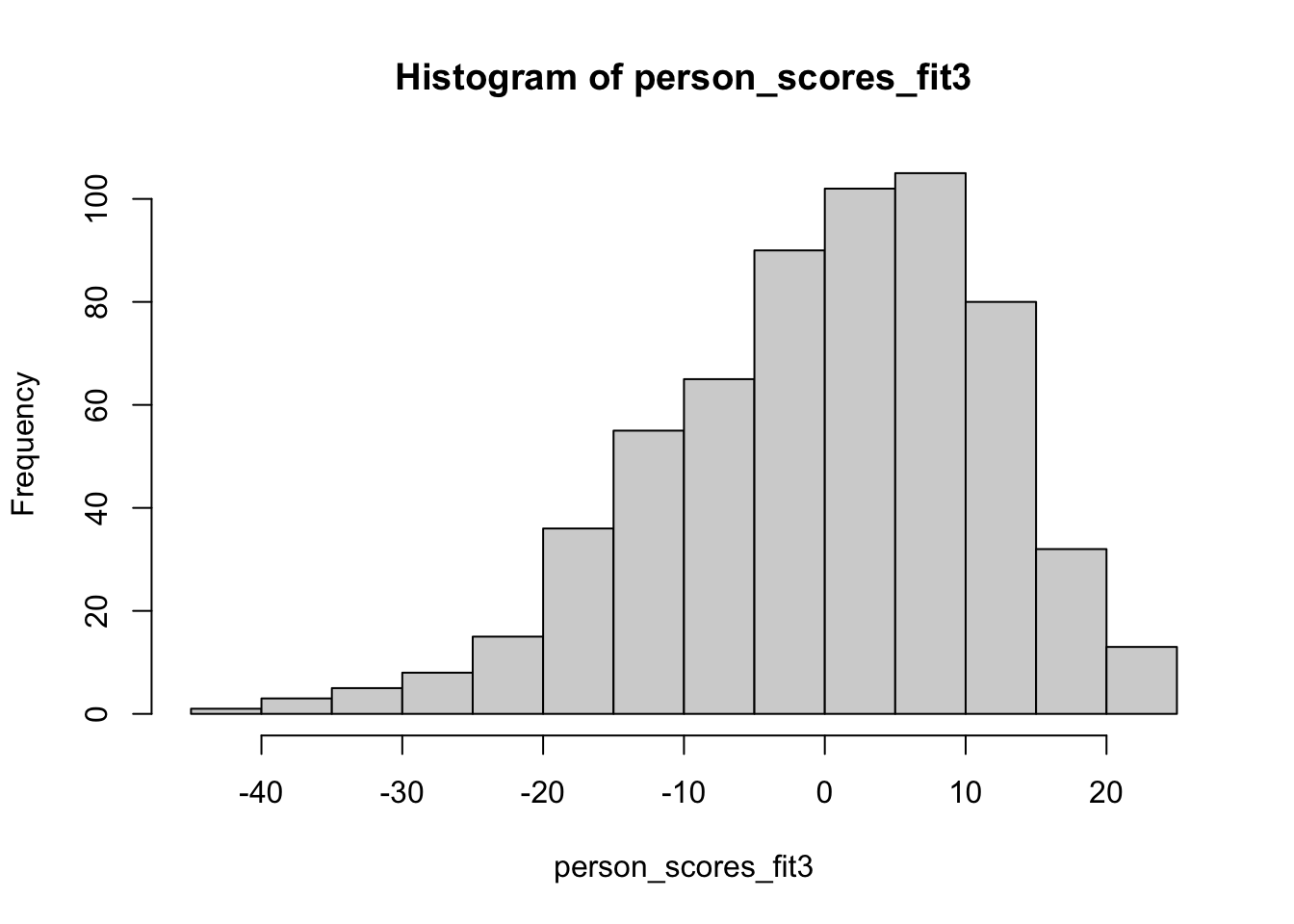
Im von uns zuletzt betrachteten Modell sind die konkreten Random Intercepts der Personen Schätzwerte für deren Ausprägung auf einer latenten Variable Gewissenhaftigkeit und die Varianz dieser Random Intercepts ein Schätzwert für die Varianz der latenten Variable Gewissenhaftigkeit in der Population. Der folgende R Code extrahiert die geschätzten Gewissenhaftigkeitswerte für alle Personen und erstellt aus diesen ein Histogramm.
Im aktuellen Modell sind die Personenparameter zentriert (eine durchschnittliche Gewissenhaftigkeit entspricht dem Wert 0), aber ansonsten sozusagen auf der Originalskala der Itemantworten (siehe den Wertebereich und den davon abhängenden Schätzwert für die Varianz der Random Intercepts).
Wäre der hier verwendete Datensatz die Normstichprobe für den analysierten Fragebogen, wären wir neben den geschätzten Personenparametern typischerweise auch an Prozenträngen interessiert. Prozentränge könnten wir in R wie folgt berechnen.
quantile(person_scores_fit3, probs =seq(from =0, to =1, by =0.1))
Das heißt zum Beispiel, eine Person mit einem geschätzten Personenparameter von 13.593 wäre gewissenhafter als etwa 90% der Normstichprobe.
Ausblick: Weitere Item Response Modelle
Die Item Response Theorie umfasst sehr viele verschiedene Modelle, abhängig unter Anderem von der Komplexität der Modellannahmen sowie dem Antwortformat der erhobenen Itemantworten. Nur wenige dieser Modelle sind mit dem lme4 Paket schätzbar.
Das vermutlich berühmteste Item Response Modell ist das sogenannte eindimensionale Raschmodell (synonym: 1PL-Modell), welches für die Auswertung von Items mit binärem Itemformat (z.b. gelöst vs. nicht gelöst oder Zustimmung vs. Ablehnung) verwendet werden kann.
Das Raschmodell unterscheidet sich von dem hier von uns betrachteten Modell nur durch die angenommene Verteilung der Itemantworten (hier Normalverteilung vs. Bernoulliverteilung im Raschmodell). Damit entspricht das Raschmodell einem Generalisierten gemischten linearen Modell (GLMM) welche in lme4 mit der Funktion glmer geschätzt werden können.
Der lme4 Code für das Raschmodell (für binäre Itemantworten in der Variable response; Annahme fester Items und zufälliger Personen) würde dementsprechend lauten:
glmer(response ~0+ item + (1|person),data = dat, family ="binomial")
Literaturverzeichnis
Borkenau, Peter, und Fritz Ostendorf. 1993. NEO-Fünf-Faktoren-Inventar (NEO-FFI) nach Costa und McCrae: Handanweisung.
Kuhlmann, Tim. 2016. Investigating measurement equivalence of Visual Analogue Scales and Likert-type scales in Internet-based personality questionnaires. OSF. osf.io/gvqjs.
Kuhlmann, Tim, Michael Dantlgraber, und Ulf-Dietrich Reips. 2017. „Investigating measurement equivalence of visual analogue scales and Likert-type scales in Internet-based personality questionnaires“. Behavior research methods 49: 2173–81. https://doi.org/10.3758/s13428-016-0850-x.