1 - pbinom(17, size = 30, prob = 0.5)[1] 0.1807973Im Modul Diagnostik I testet unser Lehrstuhl im Wintersemester 24/25 zum ersten mal ein Klausurformat, bei dem alle Fragen nur aus Aussagen bestehen, die mit richtig oder falsch beantwortet werden müssen (“Single-Choice” Format). Für jede korrekt beurteilte Aussage bekommt man einen Punkt. Bei 30 Aussagen, schreibt unsere Prüfungsordnung den folgenden Notenschlüssel vor.
| Laut Studienordnung vorgegebene Prozentgrenzen | Punkte | Note |
|---|---|---|
| ≥ 90% („sehr gut“) | 30 | 1,0 |
| 29 | 1,0 | |
| 28 | 1,0 | |
| 27 | 1,3 | |
| 26 | 1,7 | |
| ≥ 80% („gut“) | 25 | 2,0 |
| 24 | 2,3 | |
| 23 | 2,7 | |
| 22 | 3,0 | |
| ≥ 70% („befriedigend“) | 21 | 3,3 |
| 20 | 3,7 | |
| 19 | 3,7 | |
| ≥ 60% („ausreichend“) | 18 | 4,0 |
| < 60% („nicht bestanden“) | < 18 | 5,0 |
1 - pbinom(17, size = 30, prob = 0.5)[1] 0.18079731 - dbinom(0, size = 2,
prob = 1 - pbinom(17, size = 30, prob = 0.5))[1] 0.3289069In der Vorlesung haben wir besprochen, dass der Wert der Verteilungsfunktion einer stetigen Verteilung \(F(x)\), dem Integral über die Dichtefunktion \(f(x)\) von \(-\infty\) bis \(x\) entspricht. Wir wollen uns nun einmal vergewissern, dass dies tatsächlich stimmt.
In R kann man ein Integral numerisch mit der Funktion integrate() approximieren:
integrate(exp, lower = -Inf, upper = 0)1 with absolute error < 5.7e-05pnorm(0)[1] 0.5integrate(dnorm, lower = -Inf, upper = 0)0.5 with absolute error < 4.7e-051 - pnorm(1)[1] 0.1586553integrate(dnorm, lower = 1, upper = Inf)0.1586553 with absolute error < 4.8e-07pnorm(2) - pnorm(-2)[1] 0.9544997integrate(dnorm, lower = -2, upper = 2)0.9544997 with absolute error < 1.8e-11In der Vorlesung haben Sie gelernt, wie man die Parameter \(\mu\) und \(\sigma^2\) einer Normalverteilung schätzen kann. Im Übungsblatt haben Sie sich mit einer einfachen Simulation vergewissert, dass dies tatsächlich funktioniert (zumindest bei einer sehr großen Stichprobe):
set.seed(1)
x <- rnorm(1000000) # sehr große Stichprobe
mean(x) # Schätzwert liegt sehr nahe an mu[1] 4.690776e-05var(x) # Schätzwert liegt sehr nahe an sigma^2[1] 1.000371Eine weitere bekannte (und relativ einfache) Verteilung ist die Exponentialverteilung. Die Exponentialverteilung ist eine stetige Verteilung, die nur für positive Realisationen (\(x > 0\)) definiert ist, sie hat also den Träger \(T_X = \mathbb{R}^+\). Die Exponentialverteilung hat einen Parameter names \(\lambda\). Dichtefunktion lautet:
\[f(x) = \lambda e^{-\lambda x}\]
In R stehen Ihnen die Funktionen rexp(), dexp() und pexp() zur Verfügung. Das Argument rate steht jeweils für den Parameterwert \(\lambda\).
Probieren Sie für \(\lambda\) die Werte 2, 5 und 10 aus.
n <- 100000
set.seed(2)
# lambda = 2
x <- rexp(n, rate = 2)
mean(x)[1] 0.4990168# lambda = 5
x <- rexp(n, rate = 5)
mean(x)[1] 0.1994277# lambda = 10
x <- rexp(n, rate = 10)
mean(x)[1] 0.09988586Es sieht so aus (und das stimmt auch so, siehe hier), als ob für den Erwartungswert einer exponentialverteilten Zufallsvariable \(X\) gilt:
\[E(X) = \frac{1}{\lambda}\]
Wegen \(E(X) = \frac{1}{\lambda}\), ergibt sich als intuitive Schätzfunktion:
\[\hat{\lambda} = \frac{1}{\bar{X}}\] Wir vergewissern uns mit einer Simulation in R dass diese Schätzfunktion funktioniert:
n <- 100000 # sehr große Stichprobe
set.seed(3)
# lambda = 2
x <- rexp(n, rate = 2)
1/mean(x)[1] 1.999046# lambda = 5
x <- rexp(n, rate = 5)
1/mean(x)[1] 5.014445# lambda = 10
x <- rexp(n, rate = 10)
1/mean(x)[1] 9.983512\[E(\hat{\lambda}) = \frac{n}{n - 1} \cdot \lambda\]
$$$$
Begründen Sie, ob die Schätzfunktion die Gütekriterien Erwartungstreue und Effizienz erfüllt.
Die Schätzfunktion \(\hat{\lambda} = \frac{1}{\bar{X}}\) für den Parameter \(\lambda\) einer Exponentialverteilung ist nicht erwartungstreu, weil der Erwartungswert der Schätzfunktion nicht dem Parameterwert \(\lambda\) entspricht. Zumindest wird der Bias (also die Abweichung vom wahren \(\lambda\)) aber kleiner, je größer die Stichprobengröße \(n\).
Die Schätzfunktion \(\hat{\lambda} = \frac{1}{\bar{X}}\) für den Parameter \(\lambda\) einer Exponentialverteilung ist nicht effizient, weil das Gütekriterium nur für erwartungstreue Schätzfunktionen definiert ist und \(\hat{\lambda}\) nicht erwartungstreu ist.
Kommentar: Auch wenn wir nicht die genaue Definition besprochen haben, kann man beweisen, dass \(\hat{\lambda} = \frac{1}{\bar{X}}\) eine konsistente Schätzfunktion ist: Die Varianz der Schätzfunktion beträgt \(Var(\hat{\lambda}) = \frac{n^2\lambda^2}{(n-1)^2(n-2)}\) und diese Varianz (und damit auch der Standardfehler) geht gegen 0, wenn die Stichprobengröße gegen \(\infty\) geht. In Kombination damit, dass der Bias mit zunehmender Stichprobengröße ebenfalls abnimmt, bedeutet dies, dass sich die Schätzwerte mit zunehmender Stichprobengröße immer weiter dem wahren \(\lambda\)-Wert annähern.
Eine weitere sehr wichtige Verteilung, wenn es um das Thema Korrelation und Zusammenhänge zwischen Zufallsvariablen geht, ist die Multivariate Normalverteilung. Wir erklären die folgende Schreibweise im (wichtigsten) zweidimensionalen Fall:
\[ \begin{pmatrix} X_1 \\ X_2 \end{pmatrix} \sim MVN\left(\mathbb{\mu}, \mathbb{\Sigma}\right) \] \[ \mathbb{\mu} = \begin{pmatrix} \mu_1 \\ \mu_2 \end{pmatrix} \]
\[ \mathbb{\Sigma} = \begin{pmatrix} \sigma_1^2 & \sigma_{12} \\ \sigma_{12} & \sigma_2^2 \end{pmatrix} \]
Der Vektor von zwei Zufallsvariablen \(X_1\) und \(X_2\) ist multivariat normalverteilt mit den Parametern \(\mathbb{\mu}\) und \(\mathbb{\Sigma}\). Dabei entspricht \(\mu_1\) dem Erwartungswert von \(X_1\), \(\mu_2\) dem Erwartungswert von \(X_2\), \(\sigma_1^2\) der Varianz von \(X_1\), \(\sigma_2^2\) der Varianz von \(X_2\) und \(\sigma_{12}\) der Kovarianz zwischen \(X_2\) und \(X_2\) (man schreibt auch: \(COV(X_1, X_2) = \sigma_{12}\)).
In R können wir multivariat normalverteilte Zufallszahlen mit der Funktion rmvnorm() aus dem {mvtnorm} Paket simulieren.
library(mvtnorm)
n <- 100000
mu <- c(10, 20)
S <- matrix(c(4,2,2,3), ncol=2)
set.seed(4)
x <- rmvnorm(n, mean = mu, sigma = S)
str(x) num [1:100000, 1:2] 10.11 12.05 13.53 7.42 14.64 ...library(tidyverse)
dat <- data.frame(x1 = x[,1], x2 = x[, 2])
ggplot(dat, aes(x = x1)) +
geom_histogram()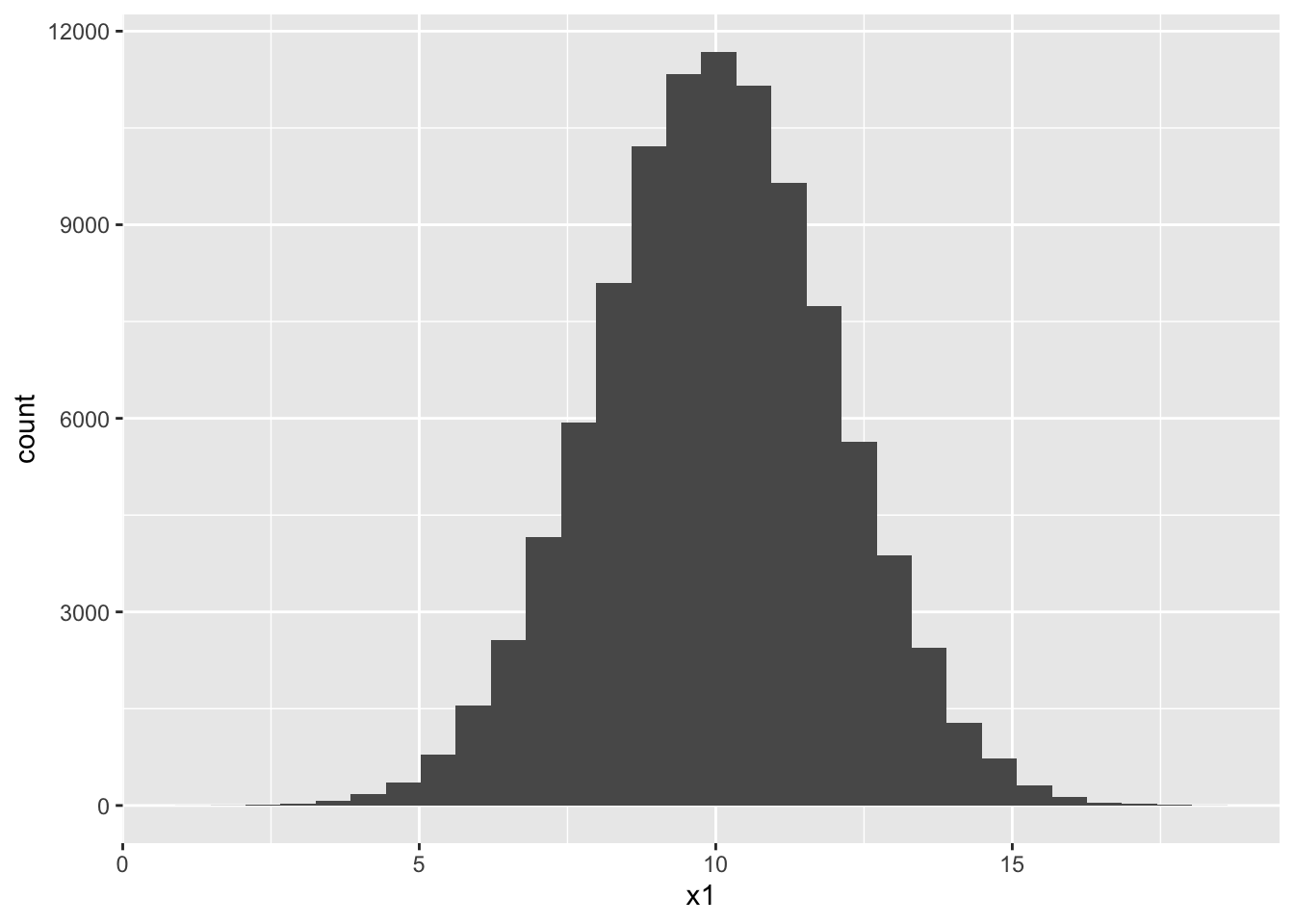
ggplot(dat, aes(x = x2)) +
geom_histogram()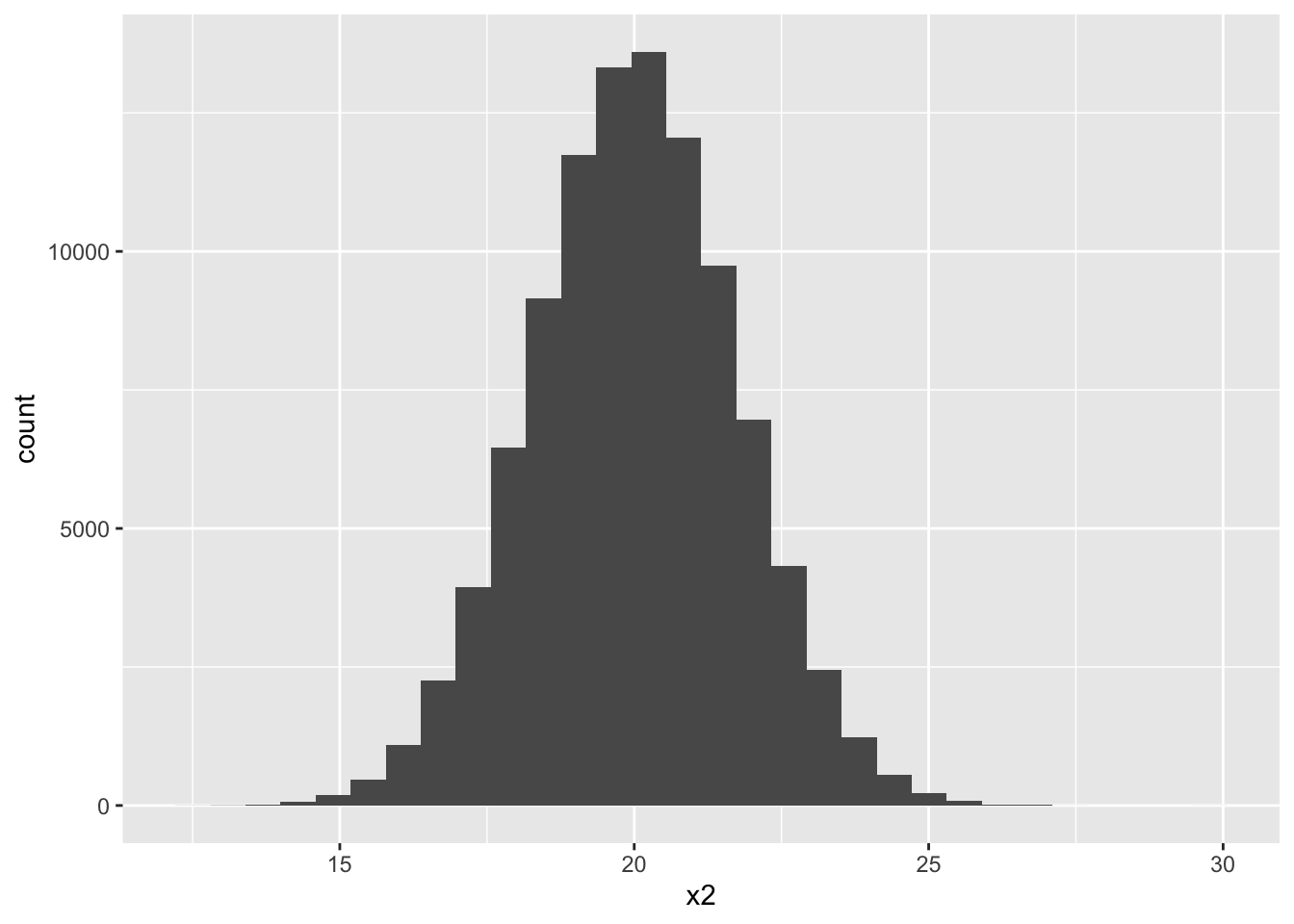
ggplot(dat, aes(x = x1, y = x2)) +
geom_point(alpha = 0.01)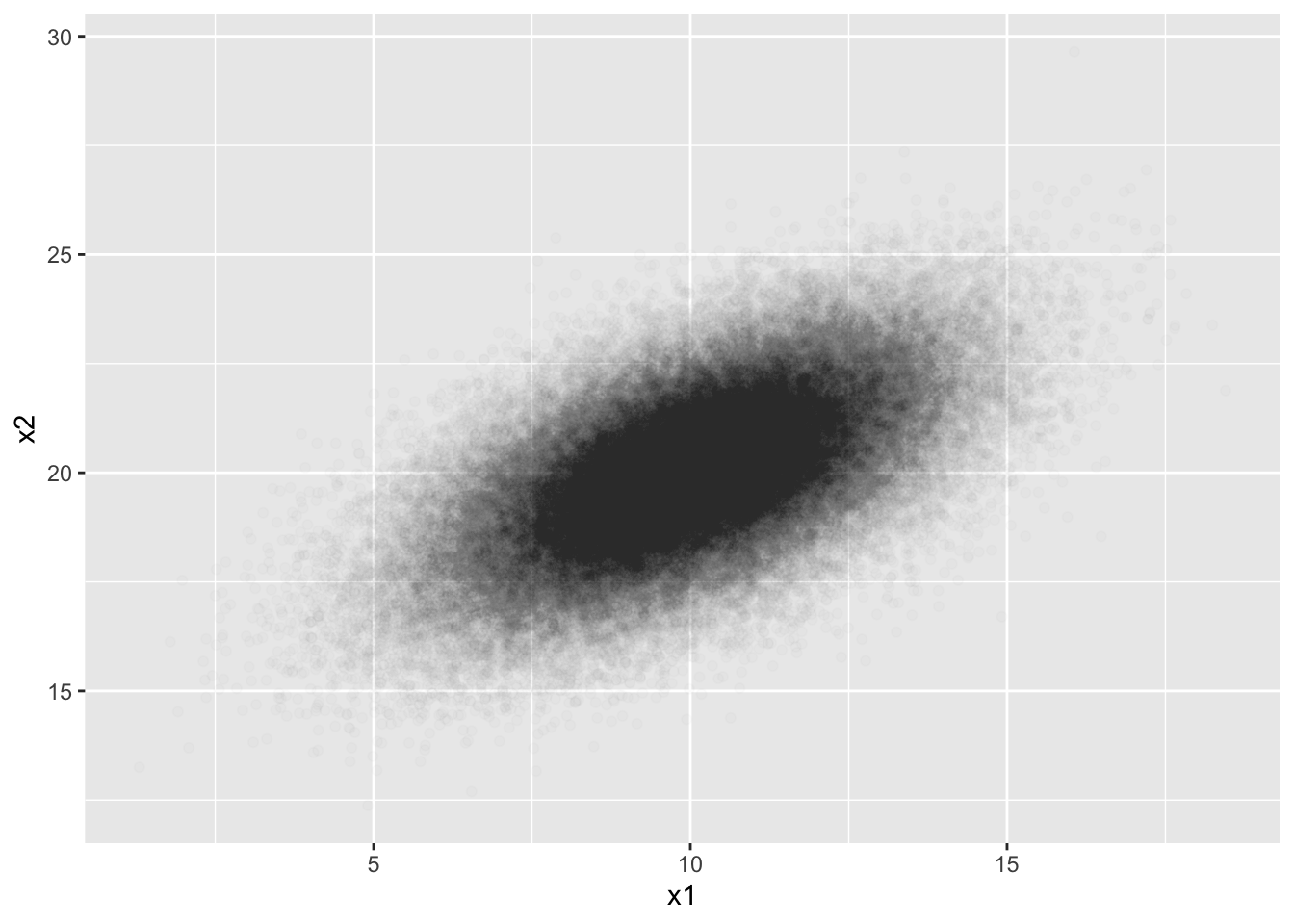
# Load necessary libraries
library(plotly)
library(mvtnorm) # For computing multivariate normal densities
# Define the mean vector and covariance matrix
mu <- c(10, 20) # Mean vector (mean_x = 10, mean_y = 20)
S <- matrix(c(4, 2, # Variance of X and Covariance between X and Y
2, 3), # Covariance between X and Y and Variance of Y
nrow = 2)
# Define the ranges for x and y based on their means
x_min <- 5 # Minimum x value
x_max <- 15 # Maximum x value
y_min <- 15 # Minimum y value
y_max <- 25 # Maximum y value
# Create sequences of x and y values
x_seq <- seq(x_min, x_max, length.out = 100) # X-axis values
y_seq <- seq(y_min, y_max, length.out = 100) # Y-axis values
# Create a grid of x and y values
grid <- expand.grid(x = x_seq, y = y_seq)
# Compute the density values
z_values <- matrix(dmvnorm(grid, mean = mu, sigma = S),
nrow = length(x_seq), ncol = length(y_seq))
# Find the maximum density value for axis scaling
z_max <- max(z_values)
# Create the 3D plot
p <- plot_ly(x = ~x_seq, y = ~y_seq, z = ~z_values) %>%
add_surface(colorscale = "Viridis") %>%
layout(
title = "3D Plot of Bivariate Normal Distribution",
scene = list(
xaxis = list(title = "x1", range = c(x_min, x_max)),
yaxis = list(title = "x2", range = c(y_min, y_max)),
zaxis = list(title = "f(x)", range = c(0, z_max)),
camera = list(
eye = list(x = 1.2, y = 1.2, z = 0.6)
),
aspectmode = "manual",
aspectratio = list(x = 1, y = 1, z = 0.5)
)
)
# Display the plot
pSinnvolle Schätzfunktionen für die Parameter der (zweidimensionalen) Multivariaten Normalverteilung sind:
\(\hat{\mu}_1 = \bar{X}_1\), \(\hat{\mu}_2 = \bar{X}_2\), \(\hat{\sigma}^2_1 = S^2_{x_1}\), \(\hat{\sigma}^2_2 = S^2_{x_2}\) und \(\hat{\sigma}_{12} = cov(X_1, X_2)\).
library(tidyverse)
dat |>
summarize(mu_1 = mean(x1),
mu_2 = mean(x2),
sigma2_1 = var(x1),
sigma2_2 = var(x2),
sigma_12 = cov(x1, x2)) mu_1 mu_2 sigma2_1 sigma2_2 sigma_12
1 9.996766 19.99922 4.017233 3.013562 2.022279Wie müssen Sie die Parameter \(\mathbb{\mu}\) und \(\mathbb{\Sigma}\) wählen, damit gilt:
\(E(X_1) = 0\), \(E(X_2) = 0\), \(VAR(X_1) = 1\), \(VAR(X_2) = 1\), und \(COR(X_1, X_2) = 0.5\)
Vergewissern Sie sich mit einer Datensimulation, dass Ihre Wahl richtig ist.
Denken Sie an die Formel der Korrelation in VL 3 und überlegen Sie sich, wann die Korrelation der Kovarianz entspricht.
n <- 100000
mu <- c(0, 0)
S <- matrix(c(1,0.5,0.5,1), ncol=2)
set.seed(5)
x <- rmvnorm(n, mean = mu, sigma = S)
dat <- data.frame(x1 = x[,1], x2 = x[, 2])
dat |>
summarize(mu_1 = mean(x1),
mu_2 = mean(x2),
sigma2_1 = var(x1),
sigma2_2 = var(x2),
sigma_12 = cov(x1, x2)) mu_1 mu_2 sigma2_1 sigma2_2 sigma_12
1 -0.00689662 -0.006090934 1.006135 1.004215 0.5023324Aufgrund dieses Sachverhalts kann man auch schreiben:
\[ \begin{pmatrix} X_1 \\ X_2 \end{pmatrix} \sim MVN\left(\begin{pmatrix} 0 \\ 0 \end{pmatrix}, \begin{pmatrix} 1 & \rho \\ \rho & 1 \end{pmatrix}\right) \] Der neue Parameter \(\rho\) entspricht der Korrelation \(COR(X_1, X_2)\). Eine sinnvolle Schätzfunktion für \(\rho\) ist \(r_{X_1 X_2}\).
Die Grundlage für alle Simulationen von Zufallszahlen (z.B. mit rnorm() in R) sind gleichverteilte Pseudo-Zufallszahlen im Wertebereich \([0,1]\). Auch wenn heutzutage deutlich bessere (und damit auch viel kompliziertere) Zufallszahlengeneratoren verwendet werden1, gibt es auch einfache Algorithmen, die in den 70ger Jahren Standard waren und teilweise heute noch in der einen oder anderen Software verwendet werden.
Linear congruential pseudorandom number generators erstellen eine Kette von pseudo-zufälligen positiven ganzen Zahlen \(I_j\) nach der folgenden Vorschrift:
\[I_{j+1} = (a \cdot I_j + c) \mod m\] Wobei die folgenden Konstanten vorher festgelegt werden:
Die so generierten pseudo-zufälligen Zahlen \(I_j\) werden anschließend in Zufallszahlen \(X_j\) im Wertebereich \([0,1]\) transformiert:
\[X_j = \frac{I_j}{m}\]
In der Formel des linear congruential pseudorandom number generators steht “mod” für die Modulus Operation (“Rest nach Division”). In R wird der Modulus mit %% berechnet, z.B.:
6 %% 2[1] 05 %% 4[1] 12 %% 3[1] 2Leider hängt die Qualität der generierten Pseudo-Zufallszahlen eines linear congruential pseudorandom number generators von den konkret gewählen Werten für \(m\), \(a\), und \(c\) ab. Ein berühmtes Beispiel für einen besonders schlechten Zufallszahlengenerator (der jedoch lange weit verbreitet war), ist RANDU. Dieser verwendet die Konstanten:
RANDU, mit den zwei Argumenten n (die gewünschte Anzahl an Pseudo-Zufallszahlen) und seed (der Wert \(I_0\) mit dem die erste Zahl generiert werden soll). Vergewissern Sie sich grafisch, dass RANDU tatsächlich gleichverteilte Zahlen im Wertebereich \([0, 1]\) erzeugt.Ein einfaches Beispiel, wie man mit function(){} eine eigene Funktion erstellen kann:
my_sum <- function(x, y) {
sum <- x + y
sum
}Nachdem die Funktion erstellt wurde, kann sie genauso wie andere Funktionen in R benutzt werden:
my_sum (x = 3, y = 5)[1] 8Verwenden Sie für Ihre Funktion einen sogenannten For-Loop. Siehe dazu das folgende Beispiel:
n <- 5
x <- rep(NA, n)
for (j in 1:n) {
x[j] <- j * 10
}
x[1] 10 20 30 40 50RANDU <- function(n, seed) {
# vector erstellen, in den später die Zufallszahlen gespeichert werden
numbers <- rep(NA, n)
# RANDU Parameter festlegen
a <- 65539
m <- 2^31
for (i in 1:n){
# Zufallszahl generieren und den seed mit der neuen Zahl überschreiben
seed <- (a * seed) %% m
# Zahl in Wertebereich [0,1] umrechnen und abspeichern
numbers[i] <- seed/m
}
# Am Ende des Loops alle Zufallszahlen ausgeben
numbers
}
RANDU(n = 5, seed = 42)[1] 0.001281797 0.007690606 0.034607462 0.138429319 0.519108756n <- 9999
randu_numbers <- RANDU(n, seed = 42)
hist(randu_numbers)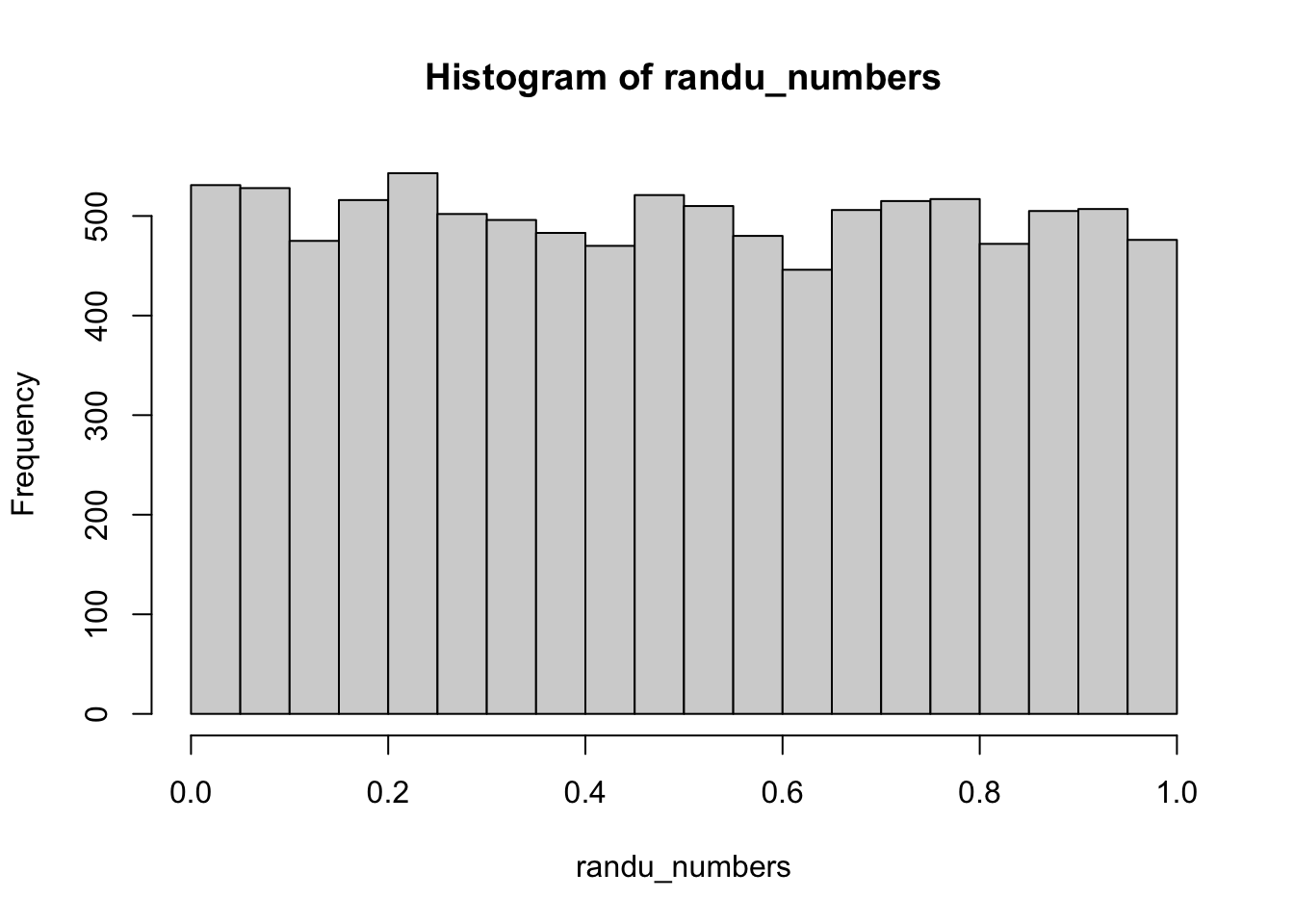
Auf den ersten Blick sehen die von RANDU produzierten Zufallszahlen eigentlich ganz sinnvoll aus. Die schlechte Qualität der Zufallszahlen, zeigt sich jedoch, wenn man die Zufallszahlen im dreidimensionalen Raum darstellt:
# 1., 4., 7., ... Zahl auf der x-Achse
x <- randu_numbers[seq(1, n, 3)]
# 2., 5., 8., ... Zahl auf der y-Achse
y <- randu_numbers[seq(2, n, 3)]
# 3., 6., 9., ... Zahl auf der z-Achse
z <- randu_numbers[seq(3, n, 3)]
# 3D scatterplot mit plotly
library(plotly)
plot_ly(x = x, y = y, z = z, type= "scatter3d",
mode = 'markers', marker = list(size = 3))Hier sehen die Zahlen jetzt gar nicht mehr “zufällig” aus…
Tatsächlich liegen alle Zahlen auf nur 15 Ebenen im 3D-Raum.
Der aktuelle Default Zufallsgenerator ist der sogenannte Mersenne Twister.↩︎