library(MBESS)
library(pwr)
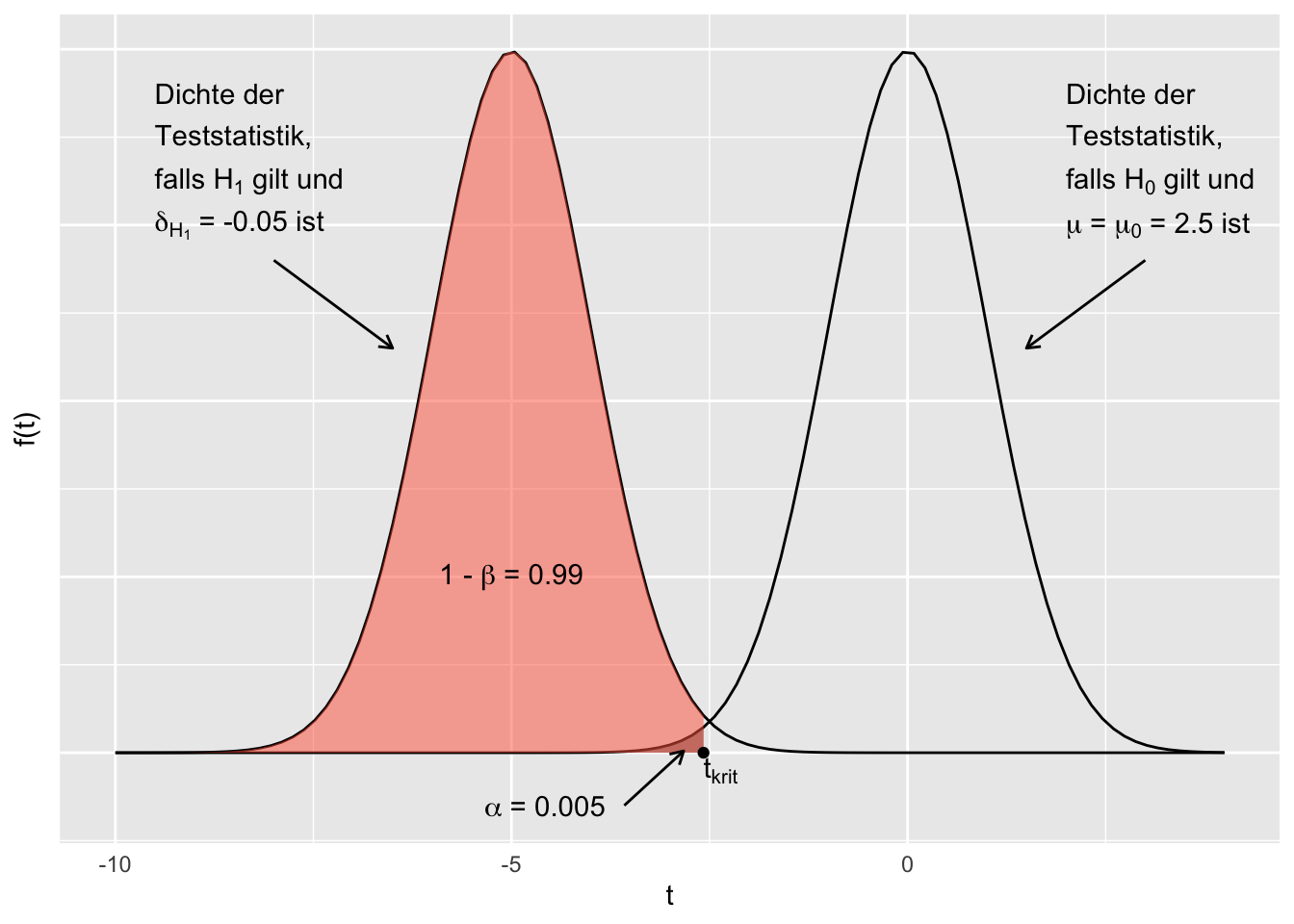
pwr.t.test(n = 10000, d = -0.05, sig.level = 0.005, type = 'one.sample', alternative = 'less')
One-sample t test power calculation
n = 10000
d = -0.05
sig.level = 0.005
power = 0.9923108
alternative = less