Sie wollen untersuchen, ob die Farbe des Klausurpapiers (rot, grün, gelb oder blau) einen Einfluss auf die (stetige) Prüfungsleistung von Studentinnen hat.
Was ist die abhängige Variable? Was ist die unabhängige Variable? Was ist der Faktor?
TippLösung
UV = Faktor: Farbe des Klausurpapiers
AV: Prüfungsleistung
Wie viele Faktorstufen gibt es? Nennen Sie diese.
TippLösung
Es gibt vier Faktorstufen: rot, grün, gelb und blau.
Geben Sie alle Parameter des einfaktoriellen varianzanalytischen Modells für dieses Beispiel an. Interpretieren Sie diese inhaltlich.
TippLösung
\(\mu_{rot}\): Mittelwert der Prüfungsleistung in der Population der Studentinnen mit rotem Klausurpapier.
\(\mu_{grün}\): Mittelwert der Prüfungsleistung in der Population der Studentinnen mit grünem Klausurpapier.
\(\mu_{gelb}\): Mittelwert der Prüfungsleistung in der Population der Studentinnen mit gelbem Klausurpapier.
\(\mu_{blau}\): Mittelwert der Prüfungsleistung in der Population der Studentinnen mit blauem Klausurpapier.
\(\sigma^{2}\): empirische Varianz der Prüfungsleistung innerhalb der Populationen.
Stellen Sie die statistischen Hypothesen für den Omnibustest des einfaktoriellen varianzanalytischen Modells auf.
TippLösung
\(H_{0}:\ \mu_{rot} = \mu_{grün} = \mu_{gelb} = \mu_{blau}\) \(H_{1}:\ \mu_{j} \neq \mu_{k}\) für mindestens ein Paar \(jk\ \)mit \(j,k\ = \ rot,\ grün,\ gelb,\ blau\) und \(j\ \neq \ k\)
Laden Sie den Datensatz herunter und lesen Sie diesen in R ein. Speichern Sie das Objekt unter dem Namen Daten ab. Für die Berechnung des Omnibus-Tests verwenden Sie zuerst die Funktion aov(AV ~ UV, data = Daten). Weisen Sie dem Objekt den Namen Daten_anova zu. Danach wenden Sie die Funktion summary() auf das Objekt Daten_anova an. In welchem Wert realisiert sich die Teststatistik T?
Df Sum Sq Mean Sq F value Pr(>F)
Farbe 3 2971 990.3 8.728 1.84e-05 ***
Residuals 196 22238 113.5
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Die Teststatistik \(T\) realisiert sich in dem Wert \(t\ \)= 8.73.
Welche Testentscheidung treffen Sie bei einem Signifikanzniveau von \(\alpha = 0.005\)? Begründen Sie.
TippLösung
Wegen \(p = 0.0000184 < 0.005 = \alpha\) entscheiden wir uns für die \(H_{1}\). Wir entscheiden uns also dafür, dass sich die mittlere Prüfungsleistung in mindestens zwei Studentinnenpopulationen unterscheidet. Wir können nicht sagen, in welchen Populationen.
Bonus: Geben Sie \({qs}_{zw}\), \({qs}_{inn}\), \(m{qs}_{zw}\) und \(m{qs}_{inn}\) an. Was ist der Schätzwert für \(\sigma^{2}\)?
TippLösung
\({qs}_{zw} = 2971\), \({qs}_{inn} = 22238\), \({mqs}_{zw} = 990.3\), \({mqs}_{inn} = 113.5\).
Der Schätzwert für \(\sigma^{2}\) beträgt \(s_{pool}^{2} = {mqs}_{inn} = 113.5\).
Sie wollen mithilfe eines Omnibus-Tests untersuchen, ob die diskrete Variable Alter (jugendlich vs. erwachsen vs. alt) mit der (stetigen) Depressionsschwere von Psychiatriepatientinnen zusammenhängt. Dazu liegen Ihnen folgende Rohdaten vor:
Patient:in
Alter
Schwere der Depression
1
jugendlich
4
2
jugendlich
1
3
jugendlich
2
4
erwachsen
3
5
erwachsen
2
6
erwachsen
1
7
alt
1
8
alt
3
9
alt
2
Die Teststatistik T des Omnibustests realisiert sich im Wert \(t = 0.08\). Für welche Hypothese entscheiden Sie sich bei einem \(\alpha\)-Niveau von 0.005? Treffen Sie Ihre Entscheidung einmal auf der Basis des p-Werts und einmal auf der Basis des kritischen Bereichs. Verwenden Sie zur Bestimmung des p-Werts die Funktion pf() und für die Bestimmung des kritischen Werts die Funktion qf().
TippLösung
Die Teststatistik \(T\) folgt unter der \(H_{0}\) einer \(F\)-Verteilung mit den Parametern \(\nu_{1} = {df}_{zw} = m - 1 = 2\) und \(\nu_{2} = {df}_{inn} = m \cdot (n - 1) = 6\).
Der p-Wert ist \(p\ = P(T \geq 0.08) = 1 - P(T \leq 0.08) = 1 - \ F(0.08)\):
1-pf(0.08, df1=2, df2=6)
[1] 0.9240843
Kritischer Wert:
qf(0.995, df1=2, df2=6)
[1] 14.54411
Testentscheidung auf der Basis des p-Werts:
Der p-Wert ist \(p\ = \ 0.924\) und somit größer als \(\alpha\ = \ 0.005\). Wir entscheiden uns also für die Nullhypothese, dass sich die Altersgruppen nicht in ihrer mittleren Depressionsschwere unterscheiden.
Testentscheidung auf der Basis des kritischen Bereichs:
Der kritische Wert für \(\alpha\ = \ 0.005\) ist \(t_{krit} = 14.54\). Somit liegt der beobachtete Wert \(t\ = \ 0.0\)8 nicht im kritischen Bereich \(K_{T} = \left\lbrack 14.54;\ \infty \right\lbrack\) und wir entscheiden uns für die Nullhypothese, dass sich die Altersgruppen nicht in ihrer mittleren Depressionsschwere unterscheiden.
Die folgenden Fragen beziehen sich auf die F-Verteilung.
Berechnen Sie in R das 0.80-Quantil einer F-Verteilung mit \(\nu_{1} = 2;\ \nu_{2} = 72\).
TippLösung
qf(0.8, df1=2, df2=72)
[1] 1.645956
Berechnen Sie die Wahrscheinlichkeit, dass sich eine F-verteilte Zufallsvariable mit \(\nu_{1} = 4;\ \nu_{2} = 95\) in einem Wert kleiner oder gleich 1 realisiert.
TippLösung
pf(1, df1=4, df2=95)
[1] 0.5884125
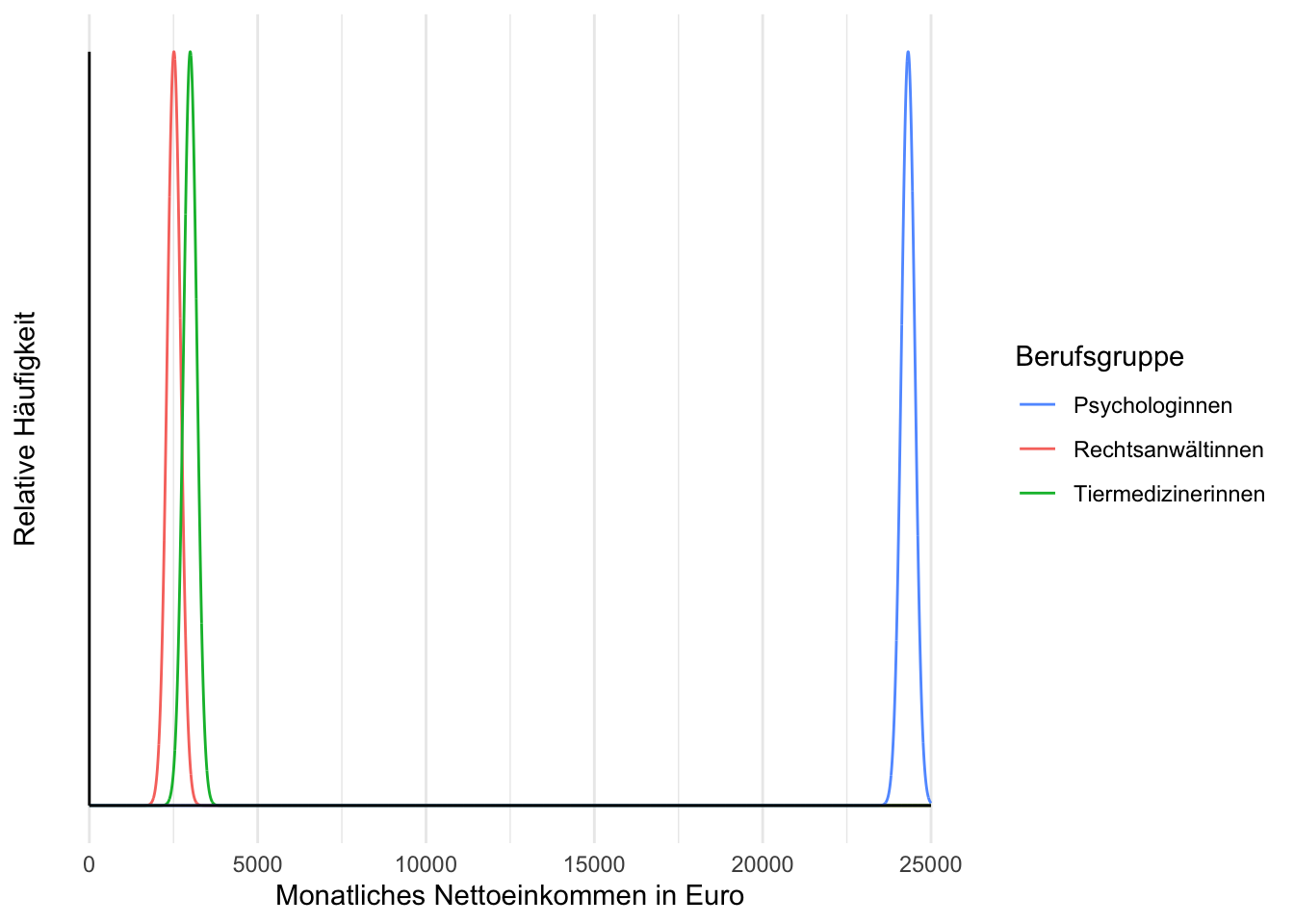
Sie wollen untersuchen, wie stark sich Rechtsanwältinnen (Gruppe 1), Psychologinnen (Gruppe 2) und Tierärztinnen (Gruppe 3) in ihrem durchschnittlichen monatlichen Nettoeinkommen unterscheiden. Dazu ziehen Sie eine balancierte Stichprobe und wählen ein dreistufiges einfaktorielles varianzanalytisches Modell:
\(Y_{ij} = \mu_{j} + \varepsilon_{ij}\) mit \(j = 1,2,3\) und \(\varepsilon_{ij} \stackrel{\text{iid}}{\sim} N(0,\ \sigma^{2})\)
Sie wollen aus den Ihnen vorliegenden Daten die Parameter für \(\mu_{1}\),\(\ \mu_{2}\), \(\mu_{3}\) und \(\sigma^{2}\ \)schätzen. Welche Schätzfunktionen würden Sie für \(\mu_{1}\),\(\ \mu_{2}\), \(\mu_{3}\) und \(\sigma^{2}\) jeweils wählen?
Sie erhalten folgende Schätzwerte: \(\hat{\mu}_{1, Wert} = 6512\), \(\hat{\mu}_{2, Wert} = 24321\), \(\hat{\mu}_{3, Wert} = 2997\) und \(\hat{\sigma}^2_{Wert} = 424\). Interpretieren Sie diese inhaltlich und skizzieren Sie die geschätzten empirischen Häufigkeitsverteilungen in der Population.
TippLösung
Rechtsanwältinnen haben ein geschätztes durchschnittliches monatliches Nettoeinkommen von 6512 Euro, Psychologinnen von 24321 Euro und Tierärztinnen von 2997 Euro. Die geschätzte empirische Standardabweichung des durchschnittlichen monatlichen Nettoeinkommens innerhalb der Gruppen beträgt 20.59 Euro.
Welche Annahmen werden im einfaktoriellen varianzanalytischen Modell für unabhängige Stichproben getroffen? Welche von diesen Annahmen können verletzt sein?
TippLösung
\(Y_{ij} = \mu_{j} + \varepsilon_{ij}\). Kann nicht falsch sein.
Die empirischen Häufigkeitsverteilungen der AV in den Populationen können jeweils durch Dichtefunktionen von Normalverteilungen approximiert werden. Kann falsch sein.
Die AV hat in allen Populationen die gleiche Varianz. Kann falsch sein.
Die \(Y_{ij}\) sind unabhängig voneinander. Kann falsch sein. Es ist aber möglich, die Unabhängigkeit durch das Ziehen einer einfachen Zufallsstichprobe aus jeder Population sicherzustellen.
Erläutern Sie, warum die Überprüfung von Modellannahmen auf der Basis von Stichprobendaten problematisch sein kann.
TippLösung
Graphische und deskriptivstatistische Verfahren zur Überprüfung der Annahmen sind sehr subjektiv.
Inferenzstatistische Verfahren zur Überprüfung der Annahmen haben in kleinen Stichproben eine zu geringe Power, um Verletzungen der Annahmen zu erkennen. In großen Stichproben erkennen sie mit einer hohen Wahrscheinlichkeit auch geringfügige Verletzungen. Zudem treffen sie oft selbst weitere Annahmen.
Wichtigster Punkt: Wir müssen sowieso davon ausgehen, dass die Annahmen (zumindest geringfügig) verletzt sind.
Wie ist die Effektgröße \(\eta^{2}\) definiert und wie kann sie inhaltlich interpretiert werden?