Der Standardfehler von B1 wird größer,...
...je höher die quadrierte Korrelation zwischen x1 und x2 ausfällt, je höher also die beiden Prädiktoren miteinander korrelieren.
...je größer die Fehlervarianz ist.
...je kleiner die Streuung von x1 ist.
...je kleiner die Stichprobe ist.
Analoges gilt für den Standardfehler von B2
Sie haben für den Sommer 2017 in 200 Städten auf der ganzen Welt die Anzahl der gekauften Eiskugeln in Millionen sowie die Anzahl der Fahrradunfälle erhoben. Laden Sie den SPSS-Datensatz herunter, lesen Sie diesen mit der Funktion read.spss() aus dem foreign package in R ein (Hinweis: Bei diesem Befehl sollten Sie das Argument to.data.frame = TRUE benutzen). Führen Sie dann eine einfache lineare Regression mit der Anzahl an Fahrradunfällen als Kriterium und der Anzahl an verkauften Eiskugeln als Prädiktor durch. (Hinweis: Die Modellvoraussetzungen sind gegeben!)
Die plausiblen Werte für die Fahrradunfälle, die pro Million verkaufter Eiskugeln in der Population erwartet werden, liegen zwischen 17.81 und 34.21.
Zusätzlich wurde an jedem Strand die Durchschnittstemperatur in Grad Celsius für den Sommer 2017 erhoben. Geben Sie die Modellgleichung für eine multiple lineare Regression mit der Anzahl an Fahrradunfällen als Kriterium und der Anzahl an verkauften Eiskugeln sowie der Durchschnittstemperatur als Prädiktoren an.
TippLösung
Y: Anzahl Fahrradunfälle, X1: Anzahl verkaufter Eiskugeln in Millionen, X2: Temperatur in Grad Celsius
Wie würden Sie in diesem Modell ein βEis von 0 interpretieren?
TippLösung
Bei konstanter Temperatur erwartet man pro Million verkaufter Eiskugeln durchschnittlich einen Anstieg von 0 Fahrradunfällen. Das heißt, bei konstanter Temperatur hängt die Anzahl der erwarteten Fahrradunfälle nicht mehr von der Anzahl verkaufter Eiskugeln ab.
Testen Sie mit R, ob βEis in der Population 0 beträgt. Dazu müssen Sie die Funktion lm() um einen weiteren Prädiktor erweitern: lm( AV ~ UV1 + UV2, data = Datensatz). Wie interpretieren Sie das Ergebnis des Tests inhaltlich?
TippLösung
fit2 <-lm(Fahrradunfälle ~ Eiskugeln + Temperatur, data = data)summary(fit2)
Call:
lm(formula = Fahrradunfälle ~ Eiskugeln + Temperatur, data = data)
Residuals:
Min 1Q Median 3Q Max
-60.573 -11.940 0.737 12.603 46.418
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 179.393 22.043 8.138 4.46e-14 ***
Eiskugeln -3.460 7.459 -0.464 0.643
Temperatur 5.242 1.125 4.661 5.78e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19.11 on 197 degrees of freedom
Multiple R-squared: 0.2479, Adjusted R-squared: 0.2402
F-statistic: 32.46 on 2 and 197 DF, p-value: 6.534e-13
Bei einem Signifikanzniveau von 0.005 wird die Nullhypothese, dass βEis in der Population 0 beträgt, beibehalten (p > 0.005). Das heißt, die Anzahl der verkauften Eiskugeln scheint über die Temperatur hinaus (bzw. bei konstanter Temperatur) keinen Einfluss auf die durchschnittliche Anzahl der erwarteten Fahrradunfälle zu haben
Professorin Freud predigt ihren Studierenden immer, dass Psychologiestudierende mit einem durchschnittlichen IQ von 100, die mindestens 30 Stunden auf die Psychoanalyseklausur gelernt haben, diese mit hoher Sicherheit (sie wählt ein 0.95-Konfidenzniveau) bestehen. Um diese Aussage nächstes Semester mit empirischen Ergebnissen untermauern zu können, hat sie von 200 zufällig gezogenen Psychologiestudierenden die Punktzahl in der Klausur, den IQ-Wert aus einem Intelligenztest und die Anzahl an Stunden, die die Studierenden auf die Klausur gelernt haben, gesammelt. In jeder Klausur von Professorin Freud benötigt man 40 Punkte, um diese zu bestehen. Laden Sie den SPSS-Datensatz herunter und lesen Sie ihn in R ein. Sprechen die Daten dafür, dass die Aussage von Professorin Freud zutreffend ist?
fit3 <-lm(Klausurpunkte ~ IQ + Lerndauer, data = daten)daten_neu <-data.frame(IQ =100, Lerndauer =30)predict(fit3, daten_neu, interval ="prediction", level =0.95)
fit lwr upr
1 50.21753 40.68859 59.74647
Für einen IQ von 100 und eine Lerndauer von 30 Stunden ergibt sich ein 95%-Vorhersage-Konfidenzintervall von 40.69 bis 59.75 Klausurpunkten. Die Aussage von Professorin Freud ist also insofern zutreffend, als dass man für eine Student*in mit einem IQ von 100 und einer Lerndauer von 30 Stunden mit hoher Sicherheit erwartet, dass diese mehr als 40 Klausurpunkte erreicht, also die Klausur besteht.
Bemerkung: Es sollte jedoch beachtet werden, dass die Ergebnisse aufgrund des nicht- experimentellen Designs der Studie nicht kausal interpretiert werden dürfen! Es ist also nicht sichergestellt, dass eine längere Vorbereitung auf die Klausur wirklich die Wahrscheinlichkeit, die Klausur zu bestehen, erhöht.
Im Übungsblatt 6 haben Sie mit dem Datensatz “Beziehungen.csv” eine Regressionsanalyse zur Vorhersage der Dauer von Beziehungen aus der Altersdifferenz der beiden Partner*innen durchgeführt. Der Output wurde als Objekt gespeichert, das wir im Folgenden “fit” nennen.
Führen Sie für den Datensatz eine Regressionsdiagnostik durch.
Folgende neue Befehle benötigen Sie hierfür:
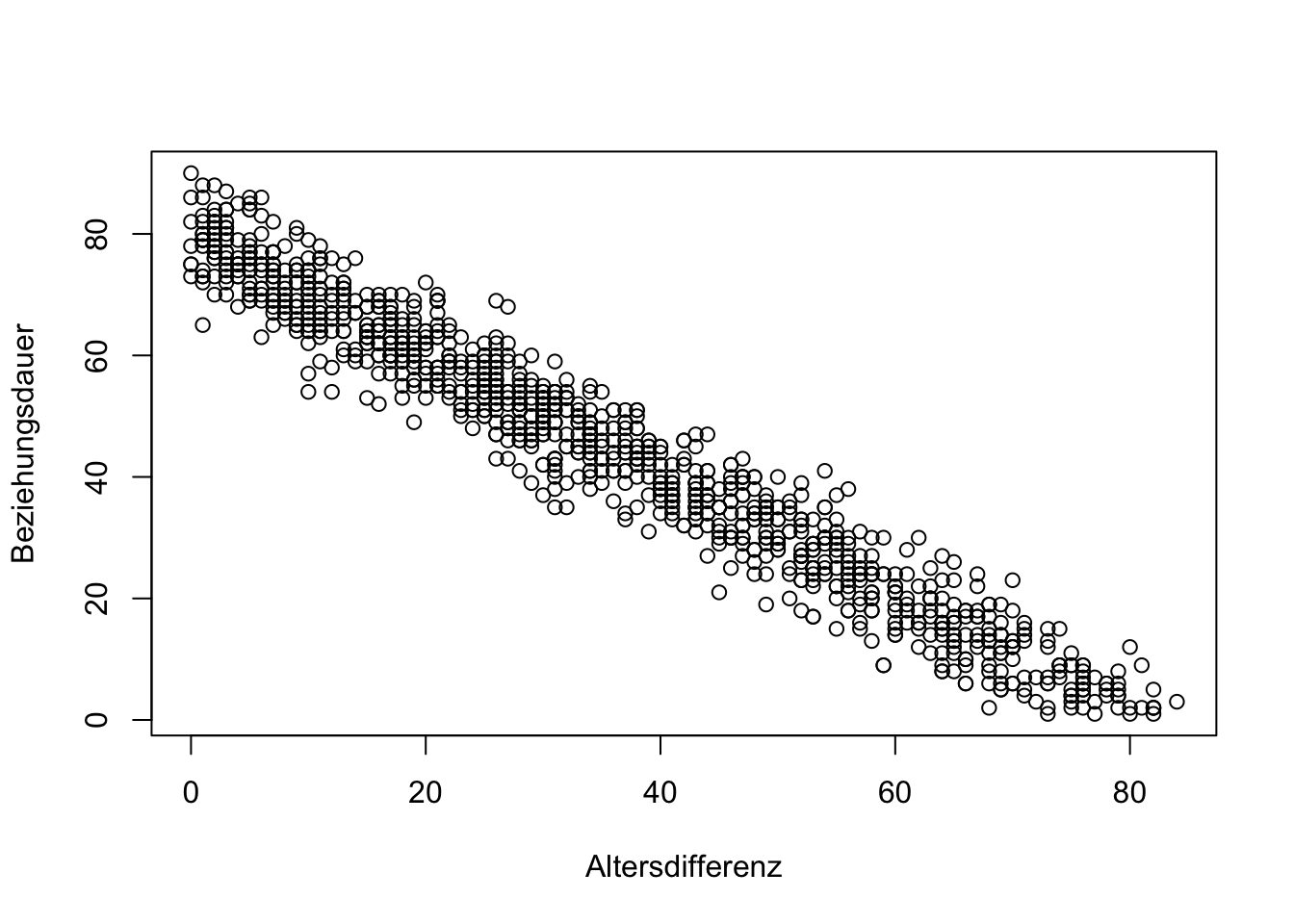
Mit der Funktion plot(AV ~ UV, data = Daten) können Sie das Streudiagramm anzeigen lassen. Die Funktion abline(fit) zeichnet in das Streudiagramm die geschätzte Regressionsgerade ein.
Mit der Funktion rstandard(fit) können Sie die standardisierten Residuen als Objekt, z.B. „res” speichern und für weitere Überprüfungen verwenden.
Mit der Funktion plot(fit$fitted.values, res) können Sie sich die vorhergesagten Werte aus dem Objekt „fit” auf der x-Achse und die Residuen auf der y-Achse in einer Grafik anzeigen lassen.
Mit der Funktion which(cooks.distance(fit) > Cut-Off-Wert) können Sie sich die Personen anzeigen lassen, die einen bestimmten Cut-Off-Wert für die Cook’s Distanz überschreiten. Dieser Wert muss für die vorliegenden Daten noch berechnet und bei „Cut-Off-Wert” eingesetzt werden, ein Beispiel wäre: which(cooks.distance(fit) > 0.022).
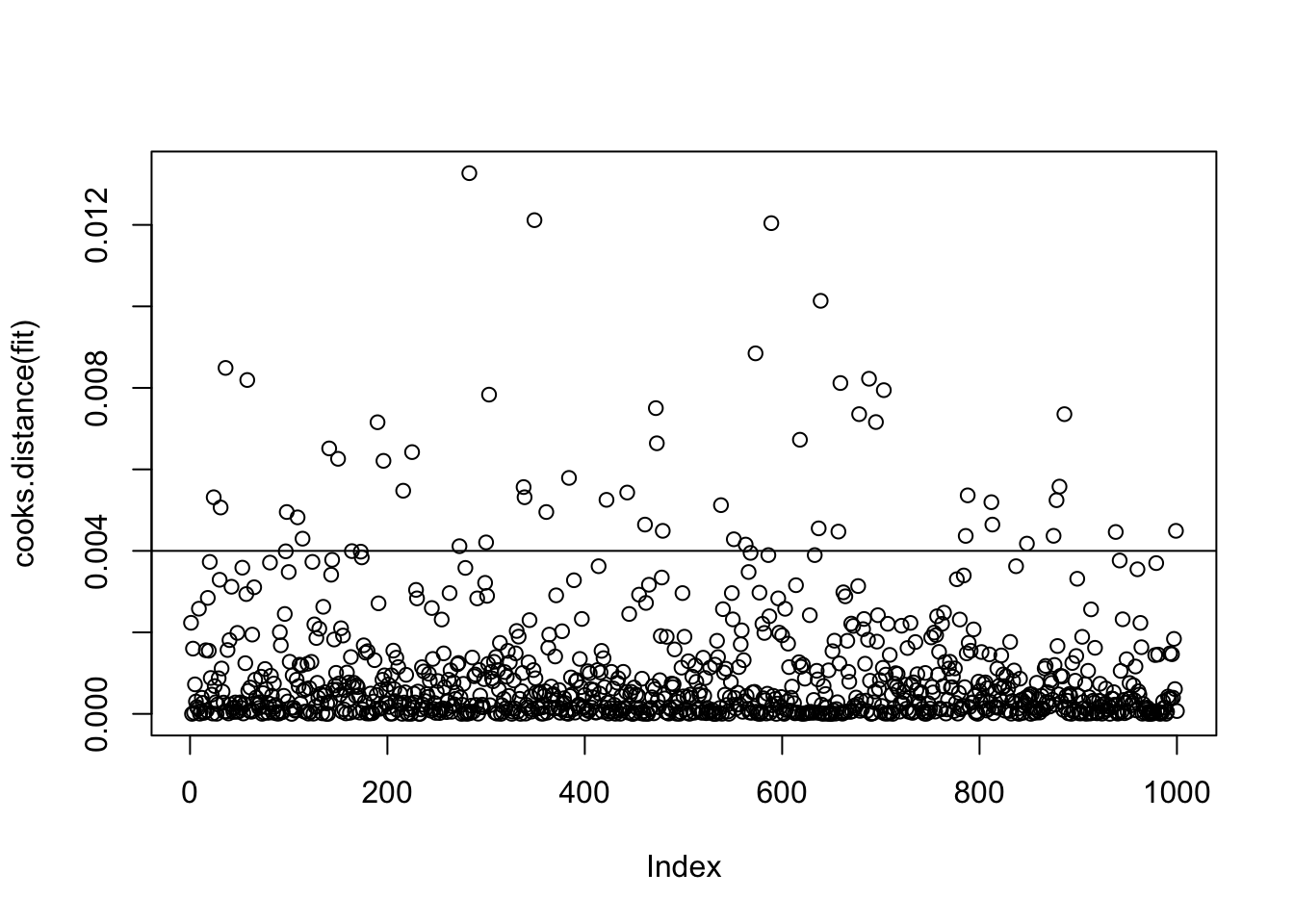
Mit der Funktion plot(cooks.distance(fit)) können Sie sich die Cook’s Distanzen für alle Personen anzeigen lassen. Mit abline(h = Cut-Off-Wert) können Sie in diese Grafik eine Linie auf einer bestimmten Höhe einzeichnen, hier bietet sich der Cut-Off-Wert an, z.B. abline(h = 0.022)
TippLösung
Daten <-read.csv2("Beziehungen.csv")fit <-lm(Beziehungsdauer ~ Altersdifferenz, data = Daten)
Überprüfung der Linearitätsannahme:
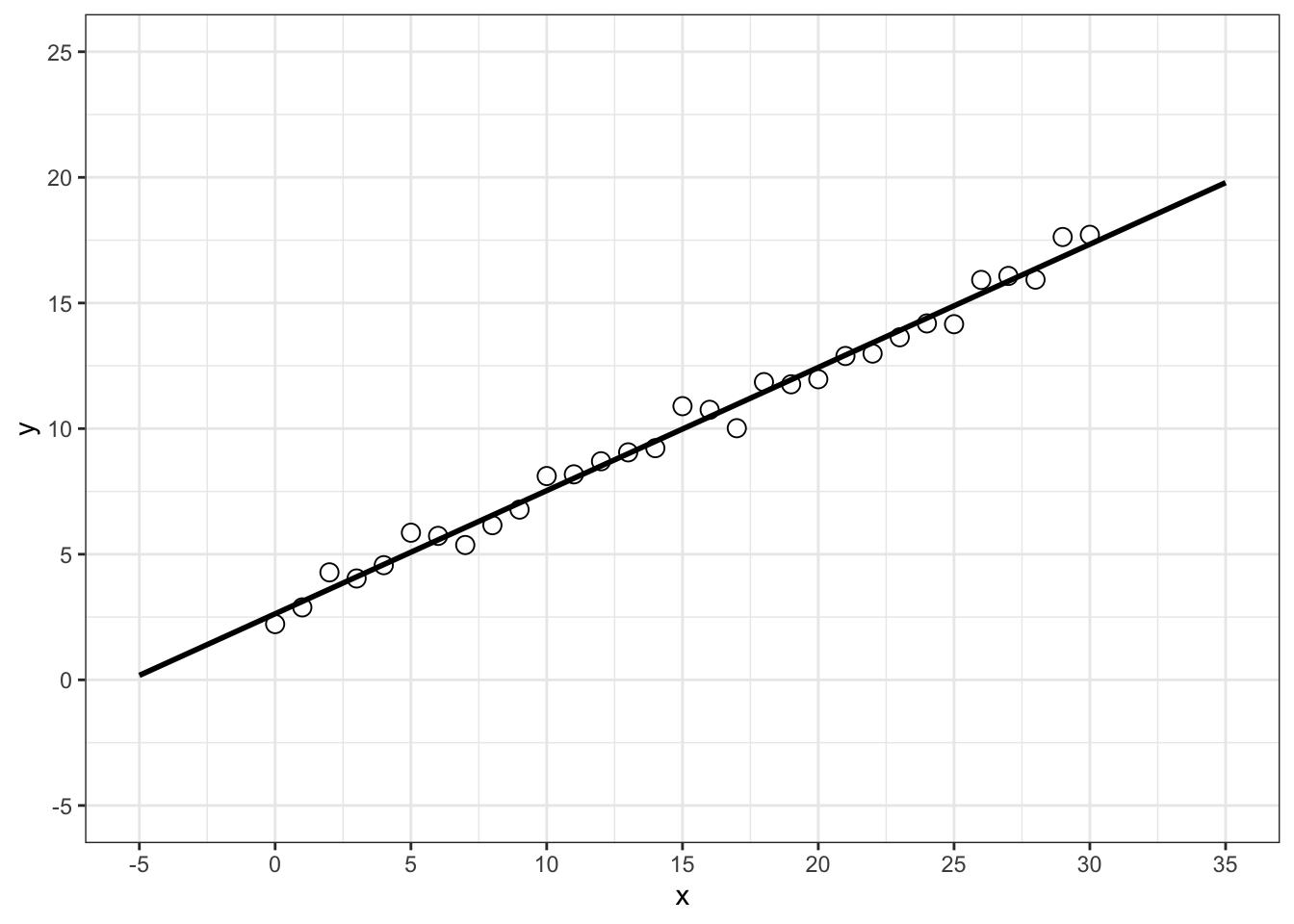
plot(Beziehungsdauer~Altersdifferenz,data=Daten)
Interpretation: Die Linearitätsannahme scheint zu gelten.
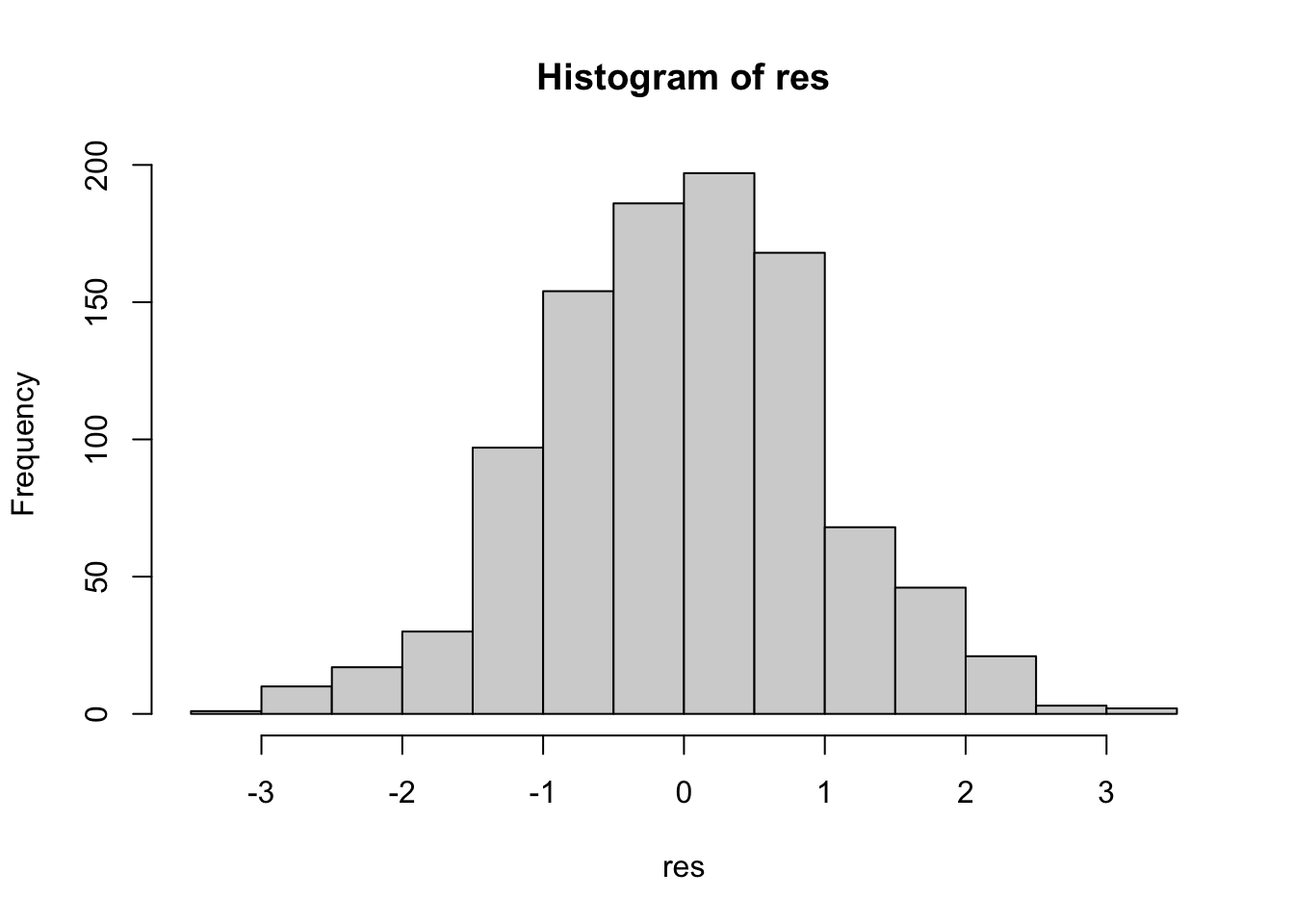
Überprüfung der Normalverteilungsannahme:
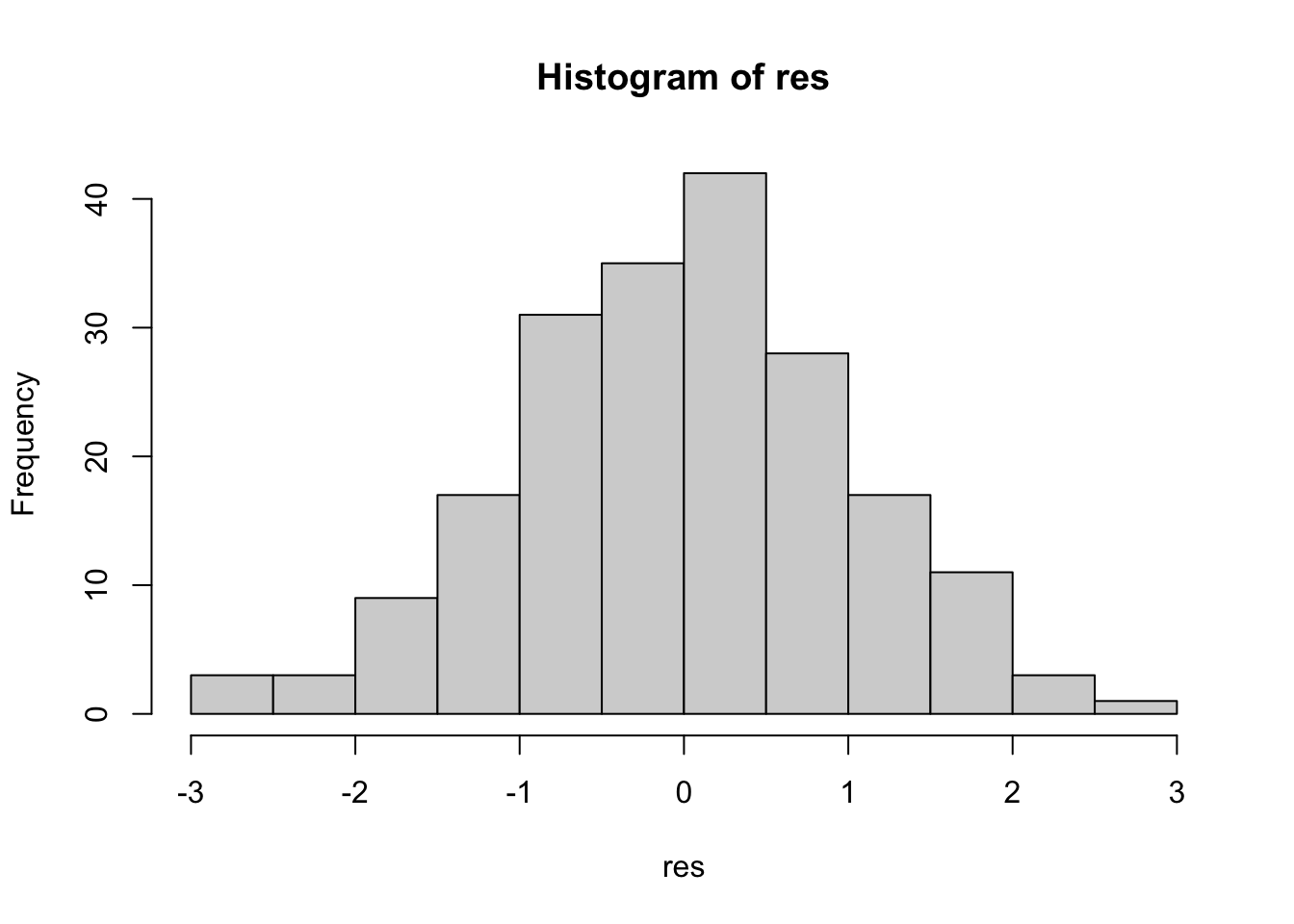
res <-rstandard(fit)hist(res)
Interpretation: Es kann davon ausgegangen werden, dass die Fehler εi einer Normalverteilung folgen.
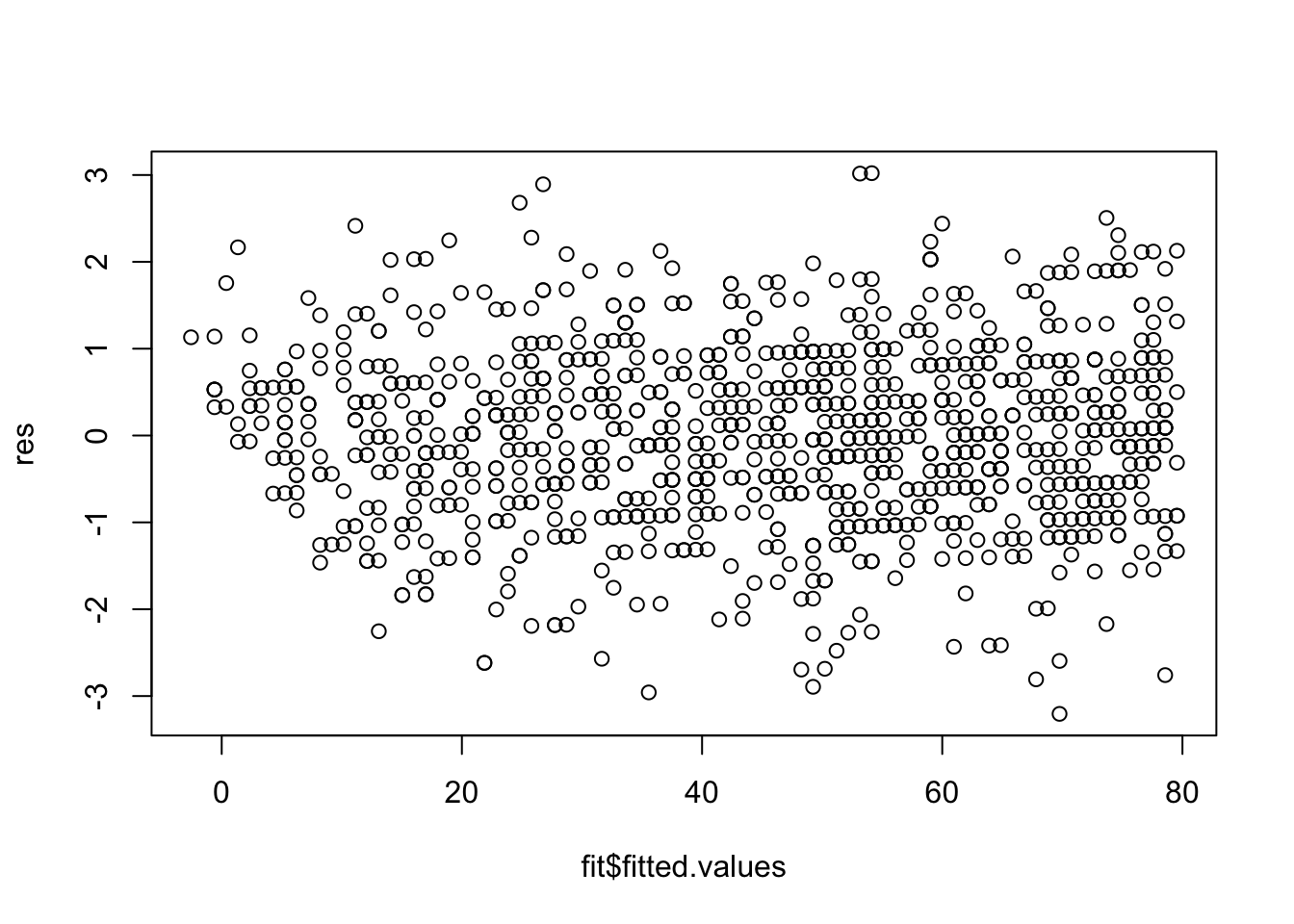
Überprüfung der Homoskedastizitätsannahme:
plot(fit$fitted.values,res)
Interpretation: Die Homogenitätsannahme scheint zu gelten.
# Prozentsatz von Cook`s Distance > 0.004`length(which(cooks.distance(fit)>0.004))/nrow(Daten)
[1] 0.053
Wird der Cut-off-Wert als Maßstab zur Bewertung herangezogen, dann weist der Datensatz ca. 5% Einflusswerte auf. Da aber im Modell explizit festgelegt wird, dass die Fehler einer Normalverteilung folgen, sind auch sehr hohe bzw. niedrige Variablenwerte zu erwarten.
Warum sind Einflusswerte bei regressionsanalytischen Verfahren problematisch? Wie gehen Sie mit identifizierten Einflusswerten um?
TippLösung
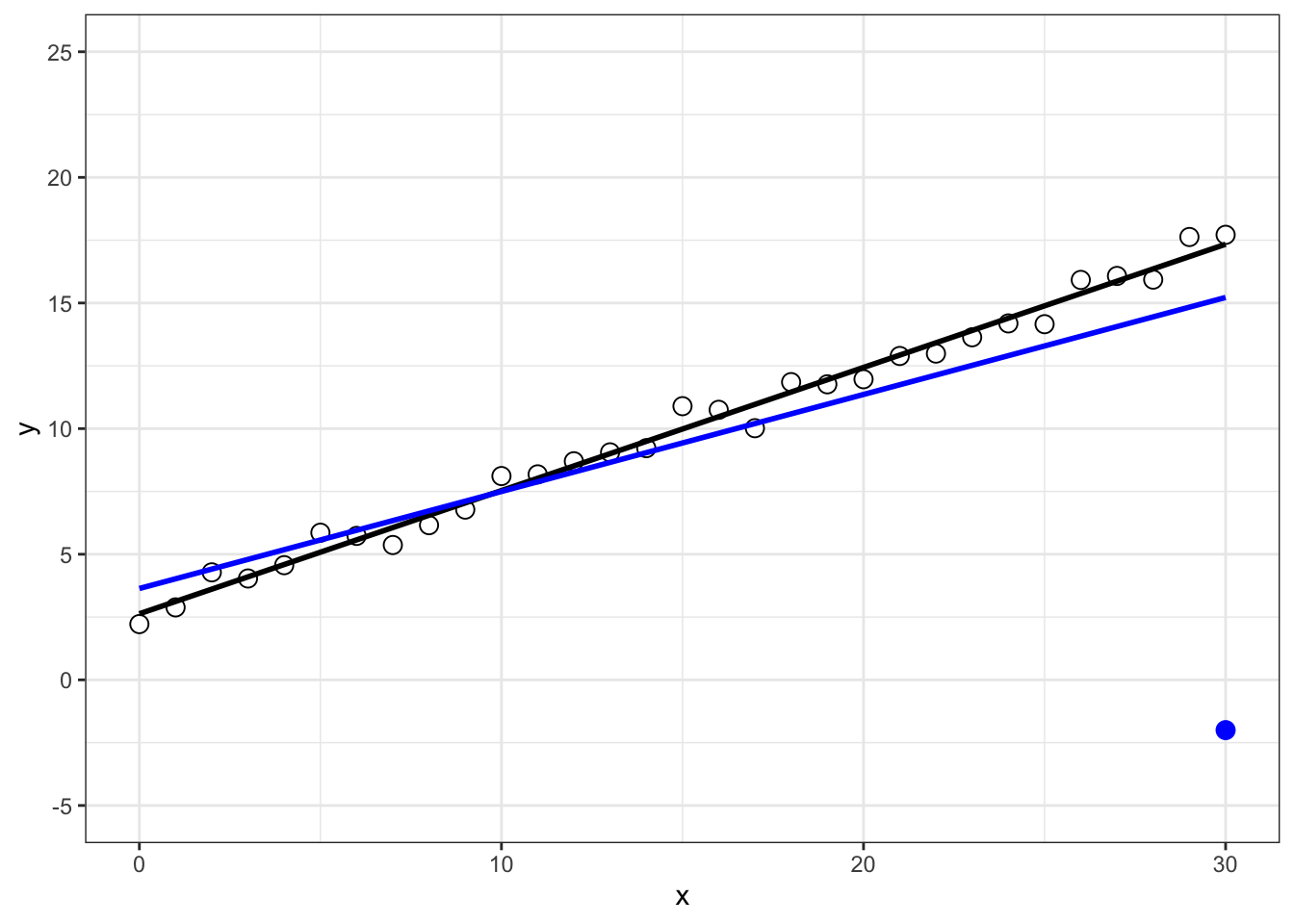
Hohe Einflusswerte wirken sich aufgrund ihrer Hebelwirkung auf die Regressionskoeffizienten aus.
Nach der Identifizierung von Einflusswerten wird nach der Ursache für die hohen Ausprägungen gesucht: Liegen Dateneingabefehler vor? Da das statistische Modell außergewöhnlich hohe bzw. niedrige Werte zulässt, sollten Ausreißerwerte nicht entfernt werden (es sei denn es liegt ein Dateneingabefehler vor, der nicht korrigiert werden kann): Es wird in den Modellannahmen festgelegt, dass die Verteilung der Beobachtungswerte einer Normalverteilung folgen, es wird daher erwartet, dass einige wenige Werte außergewöhnlich hoch bzw. niedrig sind.
Tragen Sie in die folgende Graphik einen Einflusswert ein und veranschaulichen Sie dessen Wirkung, indem Sie eine zweite Regressionsgerade einzeichnen.
TippLösung
Überprüfen Sie für das Regressionsmodell aus Aufgabe 3 dieses Übungsblattes die Modellannahmen der Linearität, Normalverteilung und Homoskedastizität. (Hinweis: Verwenden Sie für die Partiellen Residuen-Plots die Funktion crPlots aus dem car package.)
TippLösung
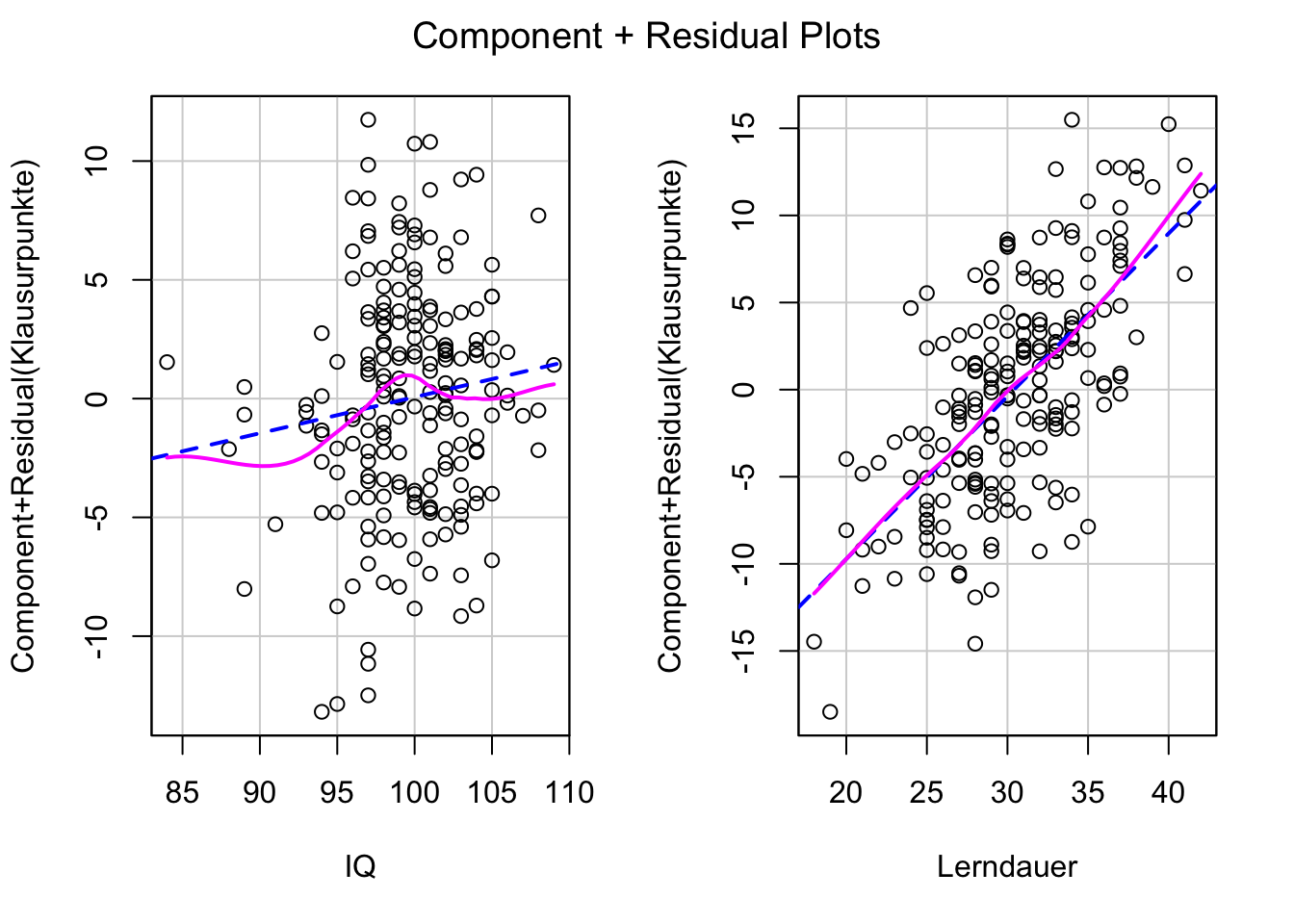
library(car)crPlots(fit3)
res <-rstandard(fit3)hist(res)
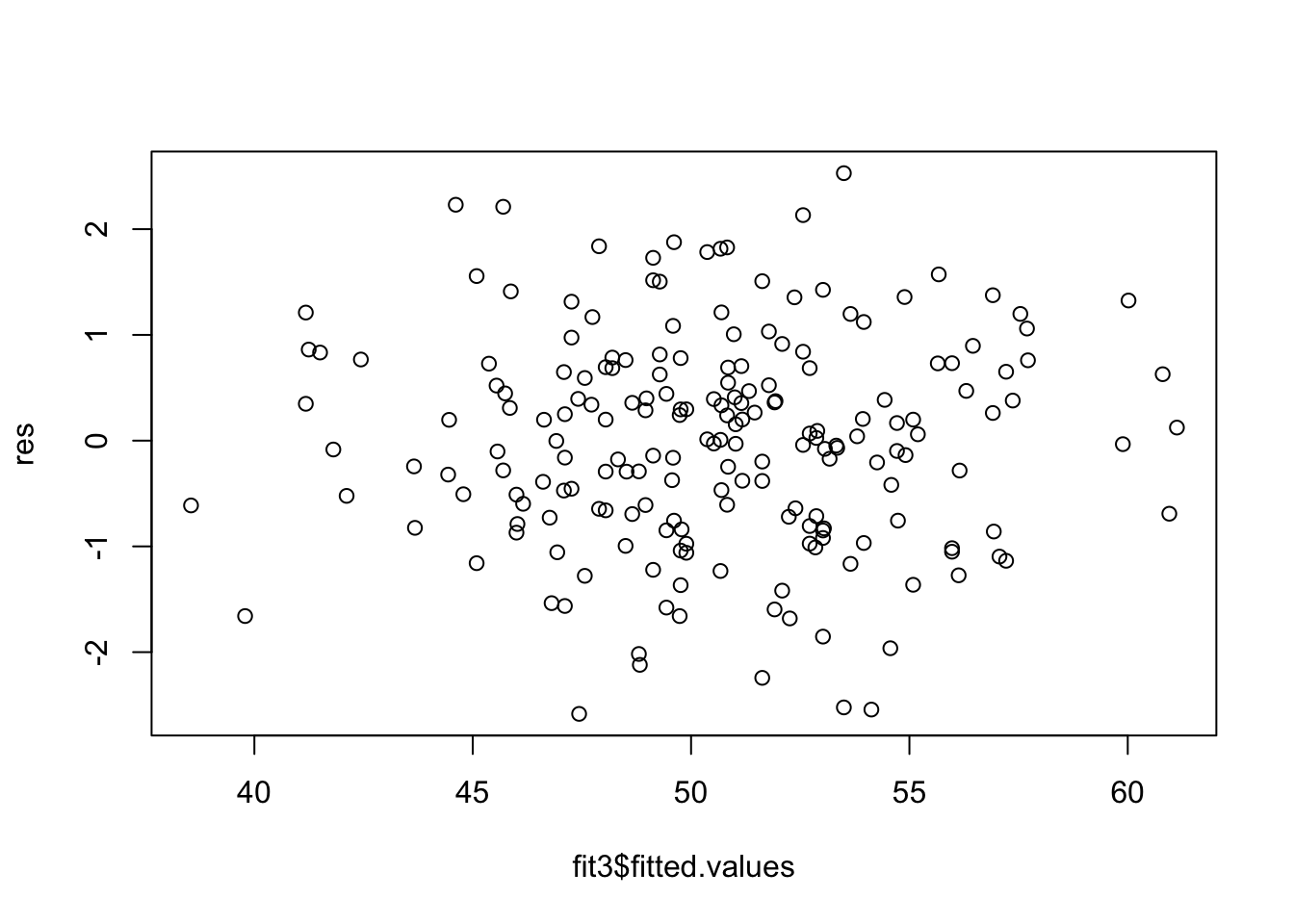
plot(fit3$fitted.values, res)
Alle Modellannahmen scheinen erfüllt zu sein. Hinweis: Die pinke Linie im Partiellen Residuen-Plot ist sehr anfällig für Ausreißer und sollte nur mit großer Vorsicht interpretiert werden!