Effektgrößen und Stichprobenumfangsplanung bei der ELR und MLR
Im Übungsblatt 6 haben Sie mit dem Datensatz „Beziehungen.csv” eine Regressionsanalyse zur Vorhersage der Dauer von Beziehungen aus der Altersdifferenz der beiden Partner*innen durchgeführt. Der Output wurde als Objekt gespeichert, das wir im Folgenden „fit” nennen.
Ermitteln Sie in R die Schätzwerte und Konfidenzintervalle für die unbekannten Effektgrößen \(\beta_{z}\) und \(\rho^{2}\). Für das KI für \(\rho^{2}\) können Sie die Funktion ci.R2() aus dem MBESS package verwenden: ci.R2(R2 = r-quadrat, p = Anzahl der Prädiktoren, N = Stichprobengröße). Für den Schätzwert und das KI für \(\beta_{z}\) müssen die Variablen mithilfe der Funktion scale() z-standardisiert werden. Diese kann direkt in der lm-Funktion angewandt werden: fit2 <- lm(scale(Beziehungsdauer) ~ scale(Altersdifferenz), data = Daten)
Interpretieren Sie jeweils die Konfidenzintervalle für \(\beta_{z}\) und \(\rho^{2}\).
TippLösung
Schätzwerte:
Daten <-read.csv2("Beziehungen.csv")
fit2 <-lm(scale(Beziehungsdauer) ~scale(Altersdifferenz), data = Daten)## Schätzwerte für beta_z und rho^2summary(fit2)
Call:
lm(formula = scale(Beziehungsdauer) ~ scale(Altersdifferenz),
data = Daten)
Residuals:
Min 1Q Median 3Q Max
-0.71590 -0.14417 0.00337 0.14691 0.67518
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.560e-16 7.071e-03 0.0 1
scale(Altersdifferenz) -9.747e-01 7.075e-03 -137.8 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2236 on 998 degrees of freedom
Multiple R-squared: 0.95, Adjusted R-squared: 0.95
F-statistic: 1.898e+04 on 1 and 998 DF, p-value: < 2.2e-16
Wir gehen davon aus, dass die Korrelation zwischen der Altersdifferenz und der Beziehungsdauer in der Population zwischen -0.96 und -0.99 liegt.
Alternativ: Wir gehen davon aus, dass in der Population die durchschnittliche Beziehungsdauer um 0.96 bis 0.99 Standardabweichungen sinkt, falls sich die Altersdifferenz um eine Standardabweichung erhöht.
Konfidenzintervall für \(\rho^{2}\):
## KI für rho^2library(MBESS)ci.R2(R2 =0.95, p =1, N =1000)
Wir gehen davon aus, dass der Anteil an der Gesamtvarianz der Beziehungsdauer in der Population, der durch die Altersdifferenz erklärt werden kann, zwischen 94.35 und 95.57% liegt.
Berechnen Sie mit R den Mindeststichprobenumfang für den Hypothesentest einer ELR für die Hypothesen
Gehen Sie von einer Power von \(1 - \beta = 0.8\) und einer Irrtumswahrscheinlichkeit von \(\alpha = \ 0.005\) aus. Der Mindesteffekt soll \(\rho^{2}\ = \ 0.1\) betragen. Sie brauchen dafür die Funktion pwr.f2.test() aus dem Package “pwr”.
library(pwr)pwr.f2.test(u =1, f2 =0.11, sig.level =0.005, power =0.8)
Multiple regression power calculation
u = 1
v = 123.0059
f2 = 0.11
sig.level = 0.005
power = 0.8
Da \(\nu\) die Anzahl der Freiheitsgrade angibt, die mindestens benötigt werden, und \(\nu\) = n – 2 ist, müssen wir zu \(\nu\) noch 2 hinzuaddieren: 123.0059 + 2 = 125.0059.
Insgesamt sollten also (aufgerundet) 126 Personen erhoben werden.
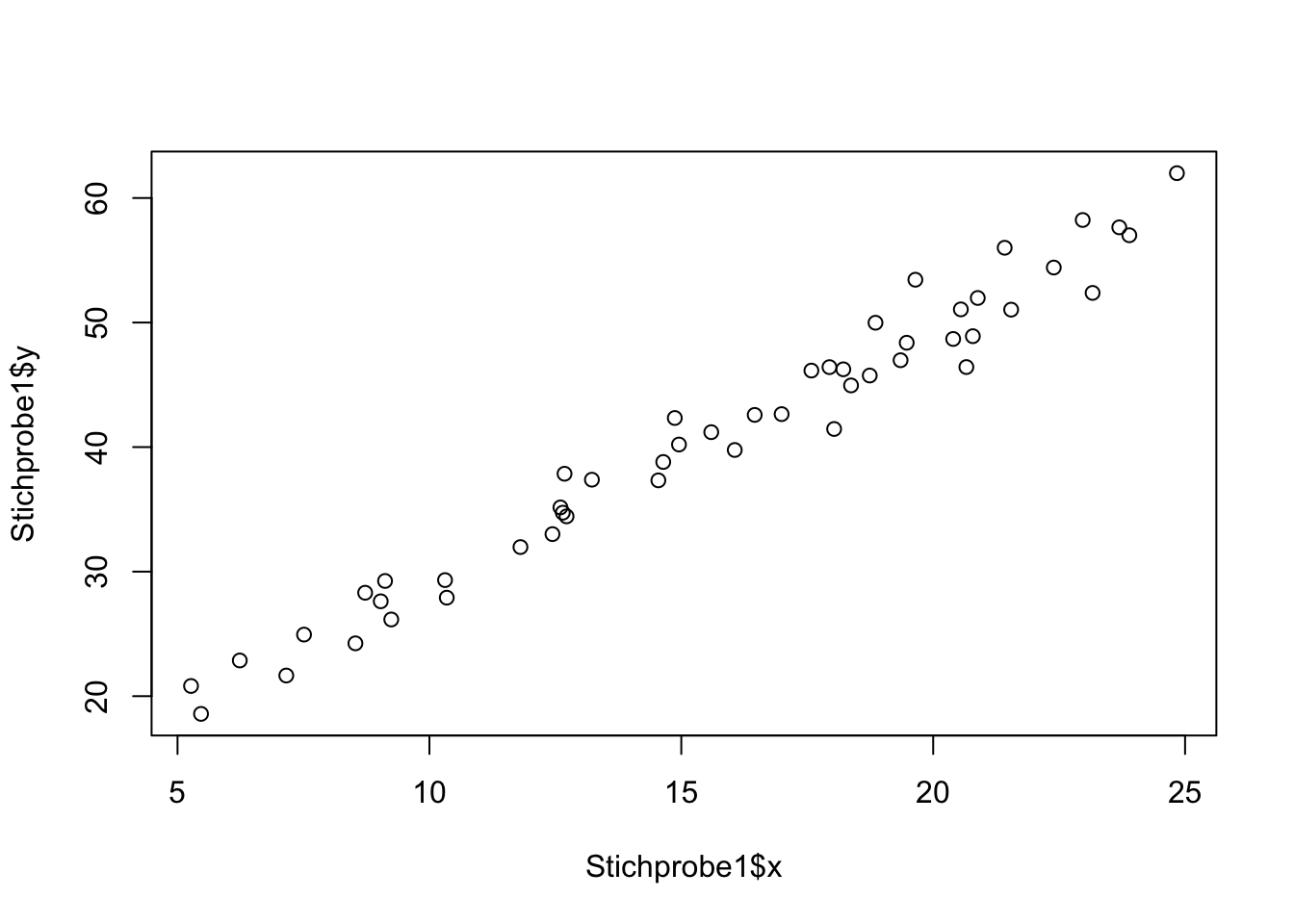
BONUS: Ziehen Sie in R jeweils eine Stichprobe mit n1 = 50 und n2 = 100.000 basierend aus dem statistischen Modell: \(Y_{i} = 10 + 2X_{i} + \ \varepsilon_{i}\), \(\varepsilon_{i}\ \stackrel{\text{iid}}{\sim} N(0,4)\). Ziehen Sie dafür für die X-Werte mit dem Befehl runif() gleichverteilte Zufallszahlen zwischen 5 und 25. Simulieren Sie die Werte für \(\varepsilon_{i}\) mit dem Befehl rnorm(). Speichern Sie anschließend die Stichproben in einem Dataframe ab. Führen Sie vor der Simulation den Befehl set.seed(1) aus, um dieselben Zufallszahlen wie später im Lösungsblatt zu erhalten.
Erstellen Sie für beide Stichproben das Streudiagramm.
TippLösung
plot(Stichprobe1$x, Stichprobe1$y)
plot(Stichprobe2$x, Stichprobe2$y)
Bestimmen Sie für beide Stichproben die 95%-Konfidenzintervalle der Koeffizienten \(\alpha\) und \(\beta\) und vergleichen Sie diese mit den Werten für \(\alpha\) und \(\beta\) aus dem statistischen Modell.
TippLösung
fit_1 <-lm(y ~ x, data = Stichprobe1)fit_2 <-lm(y ~ x, data = Stichprobe2)confint(fit_1)
2.5 % 97.5 %
(Intercept) 7.189840 10.601337
x 1.930984 2.137068
confint(fit_2)
2.5 % 97.5 %
(Intercept) 9.952609 10.021589
x 1.998900 2.003192
Sowohl für \(\alpha\) als auch \(\beta\) enthalten die Konfidenzintervalle beider Stichproben die wahren Werte aus dem Modell. Dabei ist das KI für die Stichprobe 1 aufgrund des geringeren Stichprobenumfangs breiter.
Bemerkung: Würde man die Simulation für Stichproben der gleichen Größe sehr oft wiederholen, würde man erwarten, dass das 95%-Konfidenzintervall für \(\beta\) in etwa fünf Prozent der Simulationsdurchgänge das wahre \(\beta\) nicht enthält (analog für \(\alpha\))
Geben Sie alle Effektgrößen an, die Sie im Rahmen der multiplen linearen Regression kennengelernt haben.
TippLösung
\[\ \beta_{z_{j}},\ \rho_{j}^{2},\ \rho^{2}\]
Sie betrachten ein multiples lineares Regressionsmodell mit zwei Prädiktoren.
Wie groß muss die Stichprobe sein, damit der statistische Hypothesentest mit \(\alpha = 0.005\) für die Hypothesen
bei einem \(\rho_{1}^{2} = 0.05\) und einem \(\rho^{2} = 0.1\) eine Power von \(1 - \beta = 0.8\) aufweist?
Hinweis: Verwenden Sie die Funktion pwr.f2.test() aus dem pwr package (mit u = 1).
bei einem \(\rho^{2} = 0.1\) eine Power von \(1 - \beta = 0.8\) aufweist?
Hinweis: Verwenden Sie die Funktion pwr.f2.test() aus dem pwr package (mit u = Anzahl der Prädiktoren).
## Stichprobenplanung Omnibustestpwr.f2.test(u =2, f2 =0.11, sig.level =0.005, power =0.8)
Multiple regression power calculation
u = 2
v = 144.6068
f2 = 0.11
sig.level = 0.005
power = 0.8
Es müssen also wegen \(\nu = n - k - 1 = n - 3\) aufgerundet 148 Personen erhoben werden.
Sie wollen auf Basis der Daten der PISA-Studie von 2012 untersuchen, wie die folgenden Variablen mit der Matheleistung deutscher Schüler zusammenhängen:
Interesse an Mathematik
Motivation in Bezug auf Mathematik
Selbstvertrauen in Bezug auf Mathematik
Lernaufwand für Mathematik
Angst vor Mathematik
wahrgenommene Unterstützung durch den Mathelehrer
Zugehörigkeitsgefühl in der Schule
Häufigkeit des Zuspätkommens in der Schule
Zeit, die pro Tag mit Internet-Surfen verbracht wird
Zeit, die pro Tag in sozialen Netzwerken verbracht wird
Bildung der Eltern
Anzahl der Bücher zu Hause
Lernressourcen zu Hause
Sozioökonomischer Status (SES)
Laden Sie hierzu den - Datensatz herunter und speichern Sie ihn in ein Objekt „Daten”. Sie können davon ausgehen, dass die Modellannahmen erfüllt sind.
TippLösung
Daten <-read.csv2("PISA.csv")
Für welche Prädiktoren ergeben sich die vier größten Schätzwerte für \(\beta_{z_{j}}\) (im Betrag)?
HinweisHinweise
Bevor Sie die Variablen standardisieren, müssen sie Beobachtungen mit fehlenden Werten aus dem Datensatz entfernen:
Daten_komplett <- na.omit(Daten)
Um alle Variablen im Datensatz zu standardisieren, können Sie die Funktion scale() auf den kompletten Datensatz anwenden:
Daten_z <- data.frame(scale(Daten_komplett))
Um in die lm()-Funktion nicht alle Prädiktoren einzeln eintippen zu müssen, können Sie einen Punkt eingeben:
fit <- lm(Matheleistung ~ ., data = Daten_z)
Mit dem Punkt spezifizieren Sie, dass Sie alle Variablen aus dem Datensatz (bis auf das Kriterium) als Prädiktoren in das Modell aufnehmen wollen.
TippLösung
## Beobachtungen mit fehlenden Werten entfernenDaten_komplett <-na.omit(Daten)## Verbleibende Stichprobengrößenrow(Daten_komplett)
[1] 1184
## z-Standardisierung aller VariablenDaten_z <-data.frame(scale(Daten_komplett))## Berechnung der Schätzwerte und Konfidenzintervalle für beta_z_jfit <-lm(Matheleistung ~ ., data = Daten_z)summary(fit)
Selbstvertrauen in Bezug auf Mathematik: \(b_{z_{Selbstvertrauen}} = 0.298\)
Angst vor Mathematik: \(b_{z_{Angst}} = -0.22\)
Anzahl der Bücher zu Hause: \(b_{z_{Bücher}} = 0.219\)
Bildung der Eltern: \(b_{z_{Bildung}} = 0.101\)
Berechnen Sie ein 95%-Konfidenzintervall für \(\beta_{z_{Bücher}}\ \) und interpretieren Sie dieses. Beziehen Sie Stellung zu der Aussage, dass der Zusammenhang zwischen der Anzahl der Bücher zuhause und der Matheleistung dadurch erklärt werden kann, dass Eltern mit einer größeren Anzahl an Büchern zuhause einfach gebildeter sind und diese Bildung an ihre Kinder weitergeben (z.B. durch Erziehung oder Vererbung).
Wir gehen davon aus, dass sich die durchschnittliche Matheleistung um 0.166 bis 0.272 Standardabweichungen erhöht, falls sich die Anzahl der Bücher zuhause um eine Standardabweichung erhöht und alle anderen Prädiktoren gleich bleiben.
Prinzipiell sind hier (ohne zusätzliche Annahmen) keine kausalen Schlüsse möglich. Aber auch wenn es sich um Daten aus einem Experiment handelt würde: Die Variable Bildung wurde als Prädiktor mit in das Modell aufgenommen. Das heißt bei einem \(\beta_{z_{Bücher}} \neq 0\), dass sich zwei Personen mit unterschiedlicher Bücheranzahl im Mittel in der Matheleitung unterscheiden, auch wenn deren Eltern den gleichen Bildungsgrad aufweisen. Die Anzahl der Bücher daheim hängt also über den Effekt der Bildung der Eltern hinaus mit der Matheleistung zusammen.
Wie viel Varianz in der Matheleistung können die Prädiktoren gemeinsam erklären? Berechnen Sie ein 95%-Konfidenzintervall für die entsprechende Effektgröße. (Hinweis: Gleiche R-Funktion wie bei der ELR.)
TippLösung
## Berechnung des Konfidenzintervalls für rho^2library(MBESS)ci.R2(R2 =0.3784, conf.level =0.95, N =1184, p =14)