1 + 8R Tutorial (Teil 1): Grundlagen
Wie funktioniert dieses Tutorial?
Dieses Tutorial ist für alle Studierenden gedacht, die noch nie mit R und RStudio gearbeitet haben oder die sich eine Auffrischung wünschen, bei der es nochmal mit den absoluten Basics losgeht. Das Tutorial ist so geschrieben, dass Sie Schritt für Schritt durch die wichtigsten Grundlagen geführt werden, die Ihnen die Arbeit mit dem Statistikprogramm R ermöglichen. In allen unseren Lehrveranstaltungen und in vielen Veranstaltungen anderer Lehr- und Forschungseinheiten (z.B. die Empras) ist es notwendig, eine statistische Software wie R zu verwenden. R stellt damit ein wichtiges Handwerkszeug für das empirische Arbeiten dar, das Ihnen nicht nur hilft, gelehrte Inhalte besser zu verstehen, sondern Ihnen auch ermöglicht, selbst statistische Analysen durchzuführen. Bevor wir also inhaltlich in unseren Vorlesungen in die Statistik einsteigen, sollen Sie sich hier mit den Grundlagen von R vertraut machen.
In diesem Tutorial werden wir Ihnen Schritt für Schritt die Struktur und die grundlegende Funktionsweise von R und RStudio erläutern. Sie werden zwischendrin immer wieder Kästen unterschiedlicher Farben entdecken:
HinweisHinweis
In den blauen Kästen geben wir nützliche Hinweise, die die Arbeit mit R und RStudio genauer erläutern.
TippNützlich
In den grünen Kästen behandeln wir weiterführende Themen zur Funktionalität von R und RStudio. Wenn Sie wollen, können Sie diese Kästen beim ersten Durchlauf überspringen, damit es Ihnen leichter fällt den Überblick über die Basics zu behalten.
WarnungVorsicht
In den gelben Kästen weisen wir Sie auf Fallstricke und mögliche Fehlerquellen hin. Versuchen Sie sich diese Punkte besonders einzuprägen, damit R immer das tut was Sie möchten.
VorsichtProbieren Sie es aus!
In den orangen Kästen finden Sie eine Reihe von Übungsaufgaben. Bitte führen Sie alle Übungen selber an Ihrem eigenen Computer durch.
Wie benutzen Sie dieses Tutorial?
R zu lernen ist genauso wie eine neue Sprache zu lernen. Man muss die Inhalte immer wieder wiederholen, bis das Gelernte in der Praxis selbstständig angewendet werden kann. Seien Sie nicht zu streng zu sich selbst und erwarten Sie nicht, dass Sie nach dem ersten Durchlauf des Tutorials bereits alle Inhalte verinnerlicht haben. Unser Tutorial soll Sie dazu animieren, die gelehrten Inhalte gleich auszuprobieren. Deshalb haben wir den Text und unsere Beispiele immer wieder ergänzt durch Bilder und kleine GIFs (kurze Videos ohne Ton), die die Arbeit mit dem Programm erläutern. Ein ganz wichtiger Teil des Tutorials sind außerdem die Übungen, die in den roten Kästen präsentiert werden. Im ersten dieser Kästen werden wir Sie gleich dazu auffordern, die gezeigten Programme auf Ihrem eigenen Computer zu installieren. Unsere Erfahrung zeigt, dass das Erlernen von R und RStudio nur dann funktioniert, wenn Sie von Anfang an versuchen, selbst damit zu arbeiten und die Inhalte regelmäßig wiederholen.
Bitte tun Sie das auch! Es wird sich auf jeden Fall lohnen!
1 Erste Schritte in R und R-Studio
R, wie wir es verwenden, besteht aus zwei Programmen: R und RStudio. R und RStudio sind nicht das Gleiche, bauen aber aufeinander auf.
Was ist R?
![]()
- Programmiersprache mit Fokus auf Statistik, open-source und kostenlos
- Der “Motor”, das Programm, das all unsere Berechnungen ausführt
- Kann alles, was wir brauchen (und noch viel mehr)
- Sollte regelmäßig upgedated werden
Was ist RStudio?
![]()
- Zusätzliches Programm (Editor) zur einfacheren Bedienung von R, open-source und kostenlos
- Greift im Hintergrund auf R zu, funktioniert also nicht ohne Installation von R
- Kann also alles was R auch kann, ist aber benutzerfreundlicher
- Sollte regelmäßig upgedated werden
1.1 Installation
HinweisHinweis
Wenn Sie einen privaten Computer nutzen ist es hilfreich und notwendig zu wissen, wie man Programme darauf installiert. Die einzelnen Schritte dazu hängen von Ihrem jeweiligen Modell ab. Da es sehr viele verschiedene Computer- und Betriebssystemmodelle gibt, können wir hier nicht für jede Variante eine genaue Anleitung zur Programminstallation anbieten.
Bitte machen Sie sich also soweit mit Ihrem Gerät vertraut, dass Sie auch Programme (“Apps”) wie R und RStudio installieren und verwenden können.
Die folgenden Schritte geben eine kleine Übersicht über die häufigsten Wege der Programminstallation:
Installation auf Computern mit Windows-Betriebssystem
Installationsdateien werden bei Windows normalerweise als ausführbare Datei mit der Dateiendung “.exe” heruntergeladen. Durch einen Doppelklick auf diese Datei wird das Installationsprogramm gestartet und Sie müssen nur noch den Anweisungen auf dem Bildschirm folgen.Installation auf Computern mit Mac-Betriebssystem
Auf einem Mac gibt es bei heruntergeladenen Installationsdateien zwei Varianten, bei denen sich die folgenen Schritte unterscheiden. Diese Varianten erkennen Sie an der jeweiligen Dateiendung, die entweder “.pkg” (z.B. beim Programm R) oder “.dmg” (z.B. beim Programm RStudio) ist.
Dateiendung pkg
- Doppelklick im Ordner „Downloads“ auf die heruntergeladene Installationsdatei (sie wird als geöffnetes Postpaket dargestellt).
- Die auf dem Bildschirm angezeigten Anweisungen befolgen.
Dateiendung dmg
- Herunterladen der DMG-Datei: Die meisten Programme werden über die Webseite des Herstellers als .dmg-Datei heruntergeladen. Diese Datei finden Sie danach normalerweise im „Downloads“-Ordner oder auf dem Desktop.
- Öffnen der DMG-Datei: Doppelklicken Sie auf die heruntergeladene DMG-Datei, um sie zu „mounten“. Ein neues Fenster mit dem Programmsymbol erscheint. Falls kein Fenster erscheint, prüfen Sie Ihren Desktop - ein „virtuelles Laufwerk“ wird dort angezeigt.
- Drag-and-Drop: Ziehen Sie das Programmsymbol in den „Programme“-Ordner im Finder. Dieser Schritt kopiert die Anwendung fest auf Ihr System.
- Entfernen des virtuellen Laufwerks: Klicken Sie nach dem Kopieren mit der rechten Maustaste auf das virtuelle Laufwerk auf dem Desktop und wählen Sie „Auswerfen“ oder drücken Sie CMD+E, um das Laufwerk sicher zu entfernen.
- Sicherheitsabfragen: Wenn Sie eine Anwendung öffnen, die aus dem Internet heruntergeladen wurde, könnte es sein, dass macOS eine Sicherheitswarnung anzeigt. Bestätigen Sie, dass Sie die Anwendung vertrauen, indem Sie auf „Öffnen“ klicken.
Installation auf Computern mit Linux-Betriebssystem
Wenn Sie Linux als Betriebssystem nutzen, ist eine Anleitung dieser Art für Sie vermutlich nicht notwendig… ;-)Um R zu installieren, klicken wir hier und dann auf 1: Install R. Dann müssen wir die richtige Version für unser Betriebssystem auswählen, herunterladen und (wie jedes andere Programm auch) installieren.
Um im Anschluss RStudio zu installieren, klicken wir hier und dann auf 2: Install RStudio. Damit sollte automatisch die richtige Version für unser Betriebssystem heruntergeladen werden, die wir dann (wie jedes andere Programm auch) installieren können.
VorsichtProbieren Sie es aus!
Installieren Sie R und RStudio auf Ihrem Computer.
Hinweis: Leider ist eine Installation auf Tablets mit iOS oder Android Betriebssystem nicht möglich. Sie benötigen also einen Laptop oder Desktop-Computer. Ob Sie Mac-, Windows- oder Linux-Nutzerin sind, ist völlig egal. Es ist sehr wichtig, dass Sie eine Möglichkeit finden, wie Sie R auf Ihrem eigenen Gerät nutzen können. Wenn Sie keine Möglichkeit finden, wenden Sie sich bitte an uns, vielleicht finden wir dann eine Lösung. Der Nutzen des nachfolgenden Tutorials ist nahezu Null, wenn Sie nicht selbst versuchen, die gezeigten Übungen zu lösen.
TippR und RStudio aktualisieren (updaten)
R und RStudio sollten regelmäßig aktualisiert werden, um sicherzustellen, dass wir die neuesten Funktionen und Sicherheitsupdates nutzen. RStudio erinnert uns normalerweise automatisch, wenn ein Update verfügbar ist. Diese Erinnerung von RStudio können Sie nutzen, um ebenfalls eine neue Version von R zu installieren. Leider gibt es von R selbst keine automatische Erinnerung.
Weder R noch RStudio können automatisch geupdated werden. Um R und RStudio zu aktualisieren, besuchen wir einfach erneut die Website von oben und laden die neueste Version herunter, so als würden wir das Programm gerade zum ersten mal installieren.
R kann auf Mac einfach über die bestehende Version installiert werden. Auf Windows müssen wir die alte Version manuell deinstallieren (z.B. über Start > Einstellungen > Apps > Apps &-Features), falls wir verhindern wollen, dass wir mehrere Versionen von R gleichzeitig installiert haben. Normalerweise findet RStudio aber automatisch die neueste Version von R, wenn Sie RStudio einmal komplett schließen und wieder neu öffnen.
RStudio kann normalerweise sowohl bei Mac als auch bei Windows über die bestehende Version installiert werden, ohne dass wir die alte Version manuell löschen müssen.
Nach der Installation von R und RStudio arbeiten wir nur noch mit RStudio. R selbst müssen wir zu keinem Zeitpunkt öffnen (wenn Sie wollen, können Sie die Desktopverknüpfung zu R direkt löschen, um Verwechslungen mit RStudio zu vermeiden).
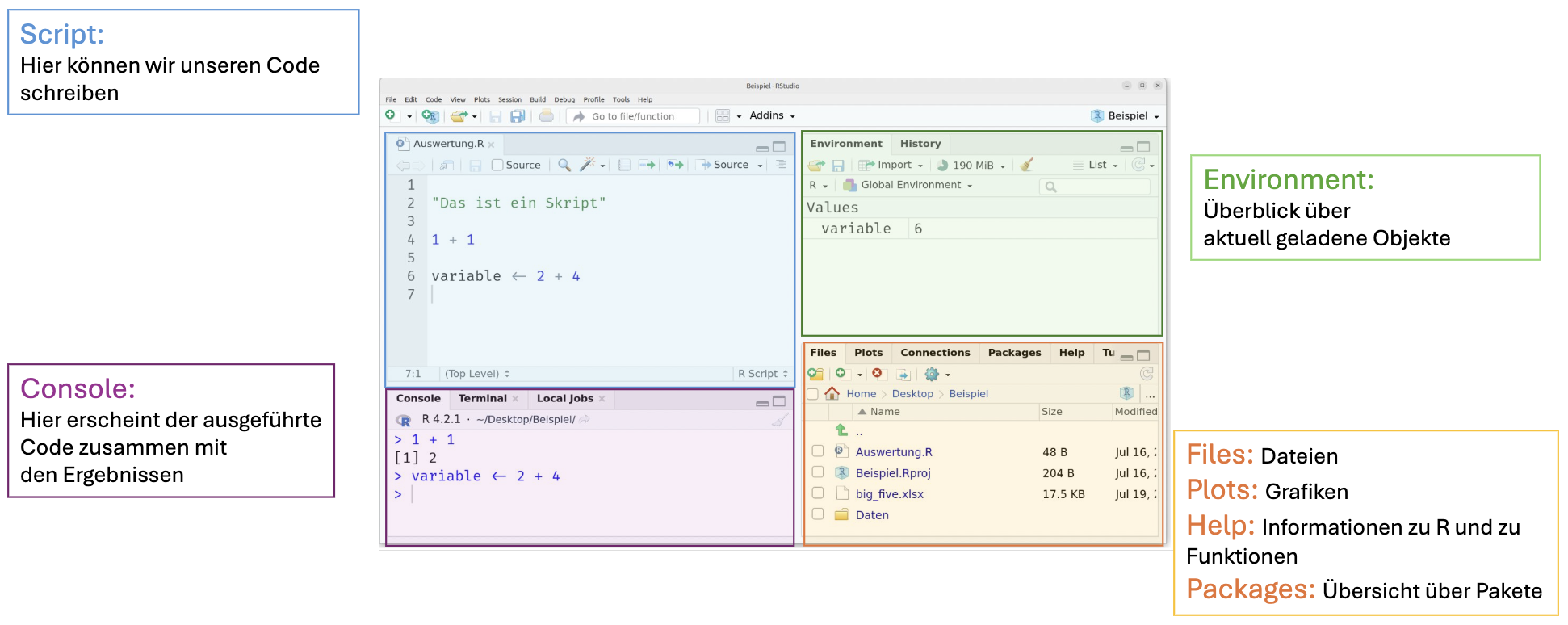
Als nächstes öffnen wir RStudio, indem wir auf die RStudio Verknüpfung auf dem Desktop, im Startmenü bei Windows oder im Finder unter Programme bei Mac klicken. Wenn wir RStudio zum ersten mal öffnen, gliedert sich die Ansicht in die folgenden drei Bereiche:
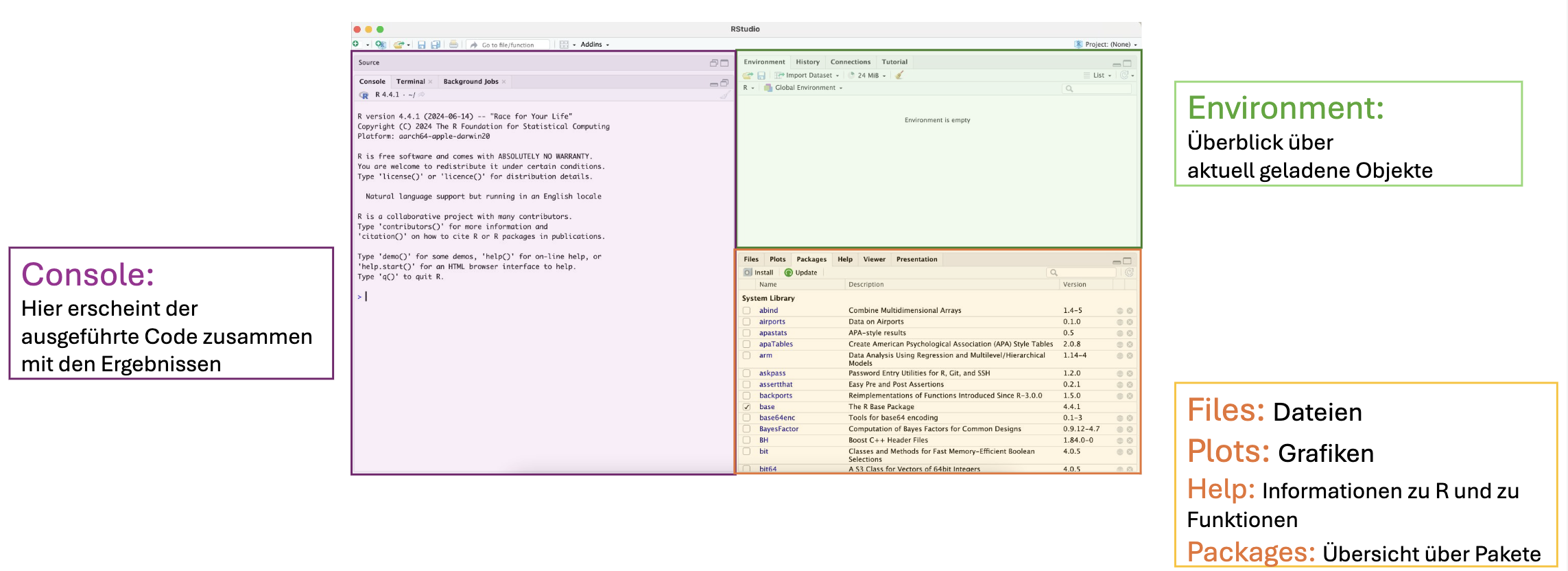
1.2 R als Taschenrechner
Wenn wir RStudio geöffnet haben, können wir in das Fenster namens Console (unten links) direkt R Befehle/Code eingeben und ausführen lassen. Zum Einstieg verwenden wir R wie einen Taschenrechner, um einfache Rechnungen auszuführen. Tippen Sie…
…in die Console und bestätigen Sie die Eingabe mit der Enter- oder Return-Taste (↵).
HinweisHinweis
Alle R-Befehle, die wir in der Console oder in Skripten (was das ist, sehen wir später) ausführen, werden in diesem Tutorial in grauen Kästen stehen:
1 + 8[1] 9Direkt unterhalb dieser Kästen steht der Output (das Ergebnis) des ausgeführten Befehls, der nach Tastendruck auf die ↵ Taste in der Console in der nächsten Zeile erscheint. Vor dem Ergebnis wird immer [1] angezeigt. Warum das so ist können wir erstmal ignorieren.
Den Code innerhalb der grauen Blöcke können Sie kopieren, indem Sie mit der Maus über die obere rechte Ecke des Kastens fahren und auf das Kopiersymbol klicken. Anschließend können Sie den Code bei sich in der Console (oder im Skript) mit dem Befehl command + v beim Mac oder Strg + v bei Windows einfügen.
Code von der Website kopieren
Wir können mit den Symbolen auf unserer Tastatur schon die wichtigsten Rechenarten ausführen:
| Symbol auf der Tastatur | Rechnung/Operation |
|---|---|
+ |
Addition |
- |
Subtraktion |
* |
Multiplikation |
/ |
Division |
^ |
Exponentiation (Potenz) |
. |
Angabe von Dezimalstellen |
( und ) |
Struktur der Rechnung (Klammersetzung) |
sqrt() |
Quadratwurzel |
log() |
(Natürlicher) Logarithmus |
VorsichtProbieren Sie es aus!
7 / 8Lösung
[1] 0.8751.6 * 7Lösung
[1] 11.2log(54)Lösung
[1] 3.9889843^2 Lösung
[1] 9(3 + 6) * 4Lösung
[1] 363 + 7 * 4Lösung
[1] 311.3 Logische Vergleiche
Wir können in R zwei Zahlen miteinander vergleichen und feststellen, ob diese gleich oder ungleich sind. Wir können auch überprüfen, ob eine Zahl größer oder kleiner ist als eine andere Zahl. Eine solche Frage wird dann in R mit entweder Ja (TRUE) oder Nein (FALSE) beantwortet. Solche Vergleiche werden logische Vergleich genannt und sind auch nicht nur auf Zahlen beschränkt (mehr dazu später).
Wenn wir uns zum Beispiel dafür interessieren, ob die Zahl 7 größer ist als die Zahl 3 können wir dies mit dem Code 7 > 3 herausfinden:
7 > 3[1] TRUEDa 7 tatsächlich größer ist als 3, erhalten wir von R die Antwort TRUE.
| Symbol auf der Tastatur | Rechnung oder Operation |
|---|---|
== |
Gleich |
!= |
Ungleich |
> bzw. < |
Größer bzw. Kleiner |
>= bzw. <= |
Größer oder gleich bzw. Kleiner oder gleich |
WarnungVorsicht
Zur Überprüfung, ob zwei Zahlen identisch sind, muss man den Operator == verwenden und erhält den Rückgabewert TRUE (ja, die Zahlen sind identisch) oder FALSE (nein, die Zahlen sind nicht identisch). Das einfache = weist einer Variable einen Wert zu (dazu später mehr).
VorsichtProbieren Sie es aus!
8 > 7Lösung
[1] TRUE3 > 4Lösung
[1] FALSE3 <= 4Lösung
[1] TRUE4 >= 4Lösung
[1] TRUE6 == 7Lösung
[1] FALSE6 != 7Lösung
[1] TRUE8 != 8Lösung
[1] FALSE
TippKombinierte Vergleiche mit logischem UND bzw. logischem ODER
Neben den einfachen logischen Vergleichen von oben ist es auch möglich, mehrere logische Vergleiche miteinander zu kombinieren. Als Verknüpfung sind vor allem das logische UND sowie das logische ODER relevant.
| Symbol auf der Tastatur | Operation | Bedeutung |
|---|---|---|
& |
logisches UND | Sind beide Vergleiche wahr? |
| |
logisches ODER | Ist mindestens einer der Vergleiche wahr? |
Als Antwort eines kombinierten logischen Vergleichs erhält man erneut entweder den Rückgabewert TRUE oder FALSE. Um sicherzugehen, dass R alle Symbole in der von uns gewünschten Reihenfolge auswertet, kann es sinnvoll sein Klammern zu setzen.
Beispiel 1:
Ist die Zahl 7 größer als 5 UND ist die Zahl 9 kleiner als 8?
(7 > 5) & (9 < 8)[1] FALSEBeispiel 2:
Ist die Zahl 7 größer als 5 ODER ist die Zahl 9 kleiner als 8 (oder beides)?
(7 > 5) | (9 < 8)[1] TRUE1.4 Datentypen Teil 1
Im folgenden wollen wir Ihnen die wichtigsten Datentypen vorstellen, denen wir bei unserer Arbeit mit R begegnen werden.
numeric, integer, double
Wie wir in Abschnitt 1.2 gesehen haben, können wir in R mit dem Datentyp “Zahl” umgehen. Intern wird dafür der Begriff numeric verwendet. Es gibt manchmal Situationen, in denen R weiter unterscheidet ob es sich um eine ganze Zahl (integer) oder eine Dezimalzahl (double) handelt. Mit jedem dieser drei Datentypen können mathematische Berechnungen vorgenommen werden. Für unsere Anwendungen ist es in der Regel egal, ob eine Zahl von R als numeric, integer oder double verstanden wird. Wir werden die Unterschiede daher nicht im Detail besprechen.
logical
Im Abschnitt 1.3 haben wir dann nach einem logischen Vergleich eine Information erhalten, die nur zwei Ausprägungen haben kann: TRUE oder FALSE. Diese Informationen haben in R den Datentyp logical. Ist für einen Wert nun der Datentyp logical hinterlegt, weiß R, dass eben nur diese beiden Ausprägungen möglich sind.
HinweisHinweis
Tatsächlich sind auch mit dem Datentyp logical manche mathematischen Berechnungen möglich. Wie kann das sein? Intern wird der logische Wert TRUE als \(1\) verstanden, der Wert FALSE als 0. Damit müsste die Berechnung TRUE \(+\) TRUE \(= 2\) ergeben:
TRUE + TRUE[1] 2Diese Eigenschaft logischer Werte mag zunächst mal sinnfrei erscheinen. Wir können sie uns jedoch an vielen Stellen zu Nutze machen. Zum Beispiel könnten wir in einer beliebig großen Menge an logischen Werten einfach alle Elemente addieren, um herauszufinden, wie viele Elemente dieser Menge die Ausprägung TRUE haben.
character (string)
Eine weitere wichtige Funktion von R ist der Umgang mit Text. Text kann dabei unterschiedlich lang sein (ein Buchstabe, ein Name, ein Absatz, ein ganzes Buch). Dadurch dass Text eine beliebige Länge haben kann, die Reihenfolge der einzelnen Buchstaben jedoch ungeheuer wichtig ist (sonst wäre der Text ja nicht lesbar), spricht man von Zeichenketten. Die Übersetzung dieses Begriffs auf Englisch wäre character string. Deshalb findet sich in R für Text häufig die Bezeichnung character oder string die synonym verwendet werden.
Durch die beliebige Länge eines Texts ist es notwendig, eindeutig zu markieren, wo die Zeichenkette beginnt und wo sie aufhört. Das machen wir mit Anführungszeichen "" die wir um den Text herumlegen.
"Das ist mein Text"[1] "Das ist mein Text"Mit Text können natürlich keine sinnvollen mathematischen Berechnungen angestellt werden, weshalb der Versuch dazu zur Fehlermeldung führt, dass ein Teil der Berechnung keine Zahl (non-numeric) ist:
"Das ist mein Text" + 1Error in "Das ist mein Text" + 1: non-numeric argument to binary operator1.5 Zuweisungen
Alles womit wir in R arbeiten können wird auch als Objekt bezeichnet. Das Ergebnis eines logischen Vergleichs ist beispielsweise ein Objekt vom Typ logical. Häufig wollen wir Objekte nicht nur einmalig und unmittelbar durch die Ausführung eines Befehls erstellen, sondern mit ihnen an späterer Stelle noch weiter rechnen. Dafür können wir mit einer so genannten Zuweisung bewusst Objekte mit von uns vergebenen Namen erstellen. Wir können dann die erstellten und benannten Objekte verwenden, ohne den ursprünglichen Befehl noch einmal ausführen zu müssen.
Die Zuweisung erfolgt mit dem Zuweisungspfeil <- (ein “kleiner” Zeichen, direkt gefolgt von einem “Minus”). Links vom Pfeil steht der Objektname, mit dem wir später auf den Inhalt des Objekts zugreifen, rechts vom Pfeil die Operation, die uns als Ergebnis den Inhalt liefert, den wir zwischenspeichern wollen. Sobald wir das Objekt erstellt haben, ist es im Environment-Fenster (oben rechts in RStudio) zu finden. Hier sind dann auch nützliche Informationen zum Objekt angegeben, wie beispielsweise auch der Datentyp des Objekts.
Ein Beispiel
Wir wollen die Operation \(\sqrt{x}\) für \(x = 7\) einmal ausführen und das Ergebnis in einem Objekt mit dem Namen “A” abspeichern. Der Programmiervorgang ist typischerweise:
- Objektnamen bestimmen
- Zuweisungspfeil
- Auszuführende Operation
A <- sqrt(7)Zuweisung
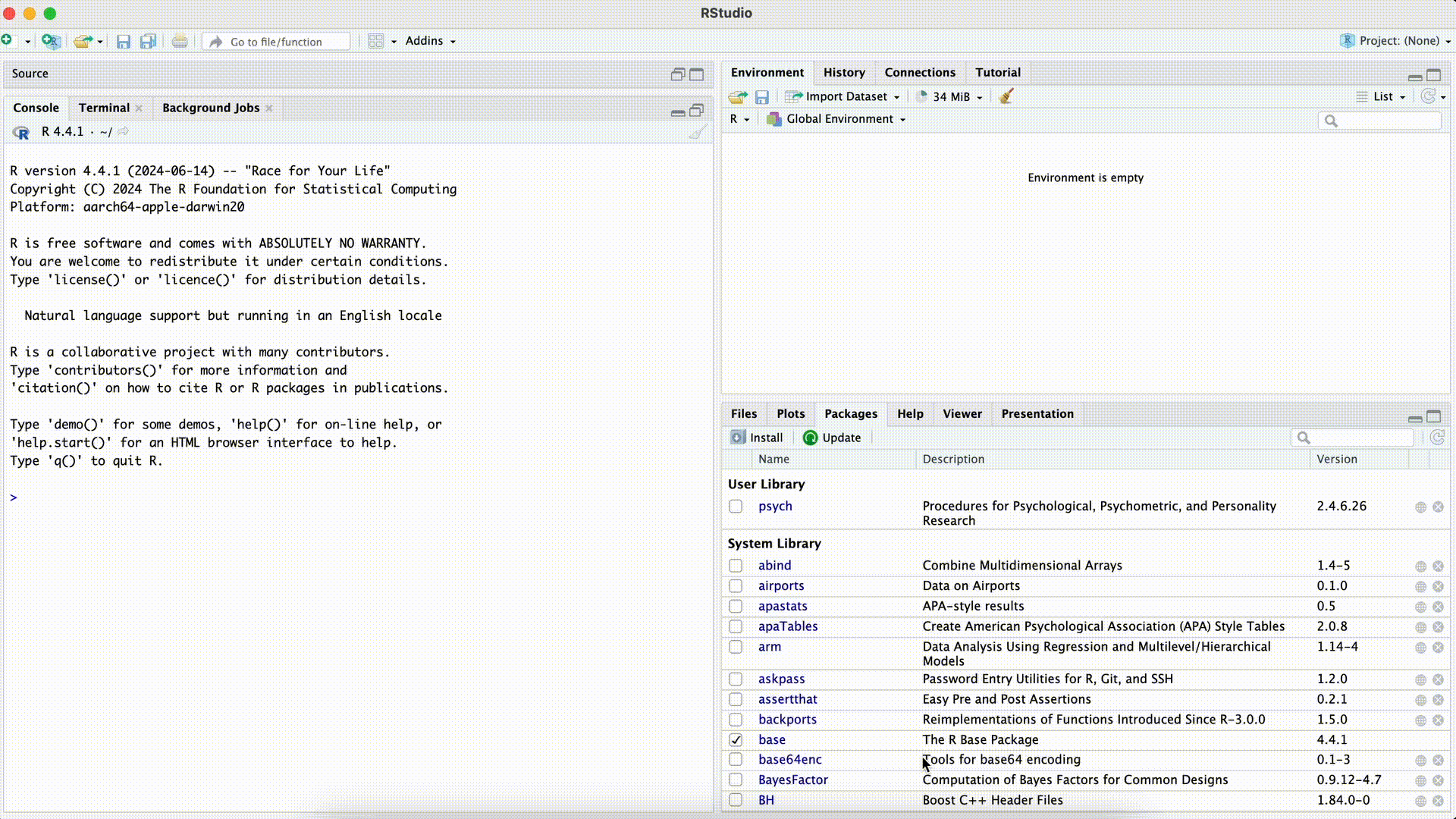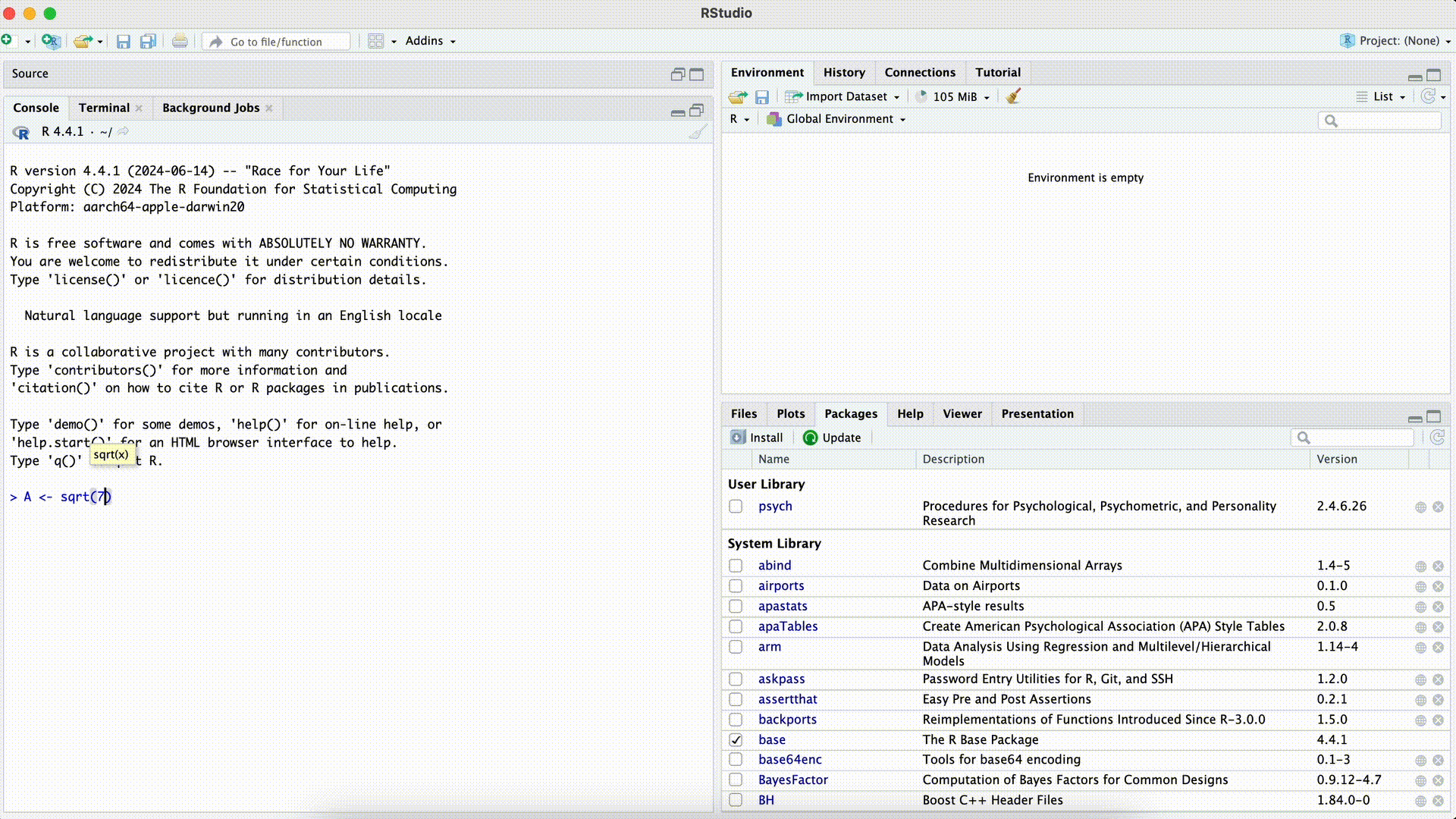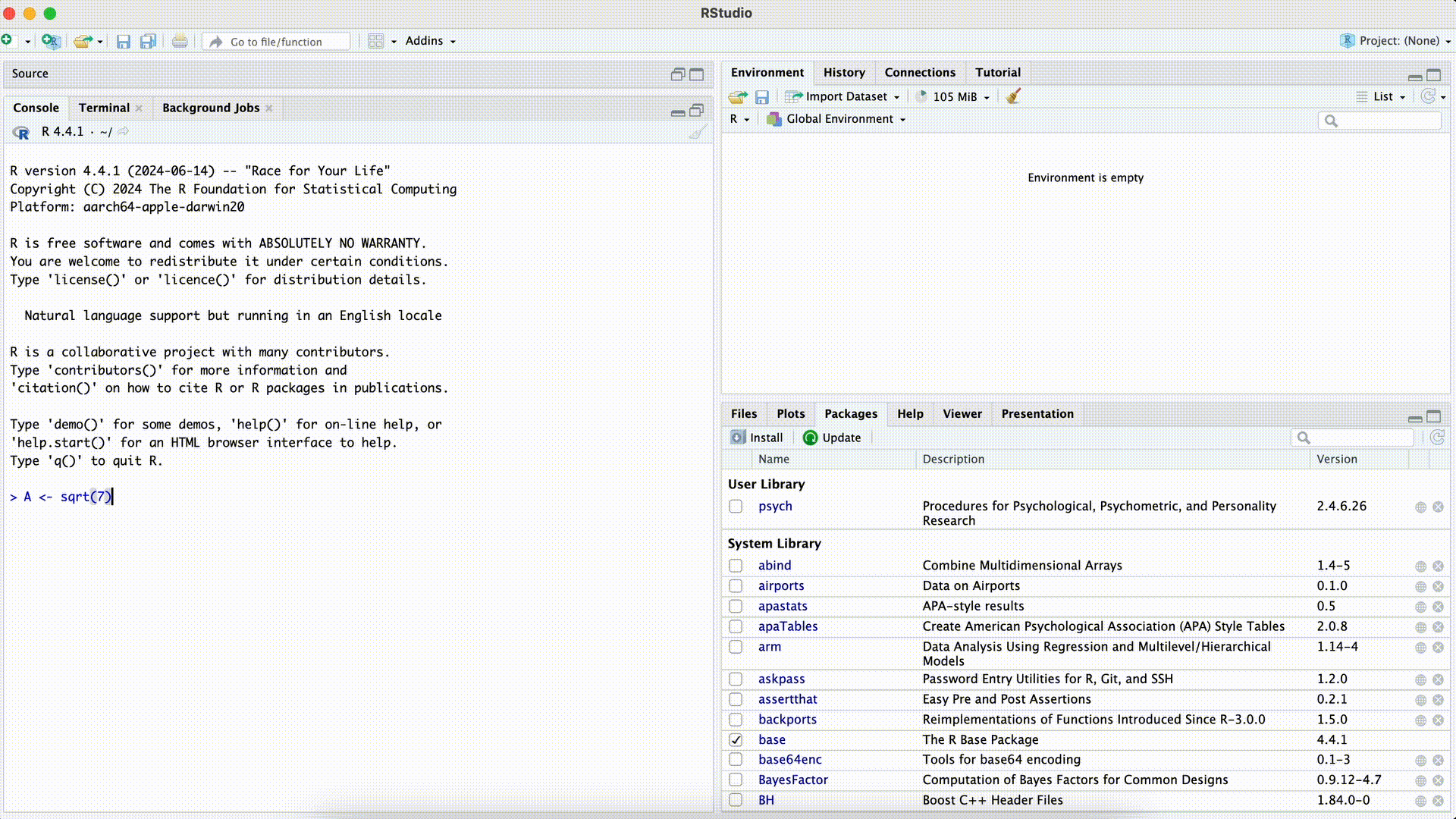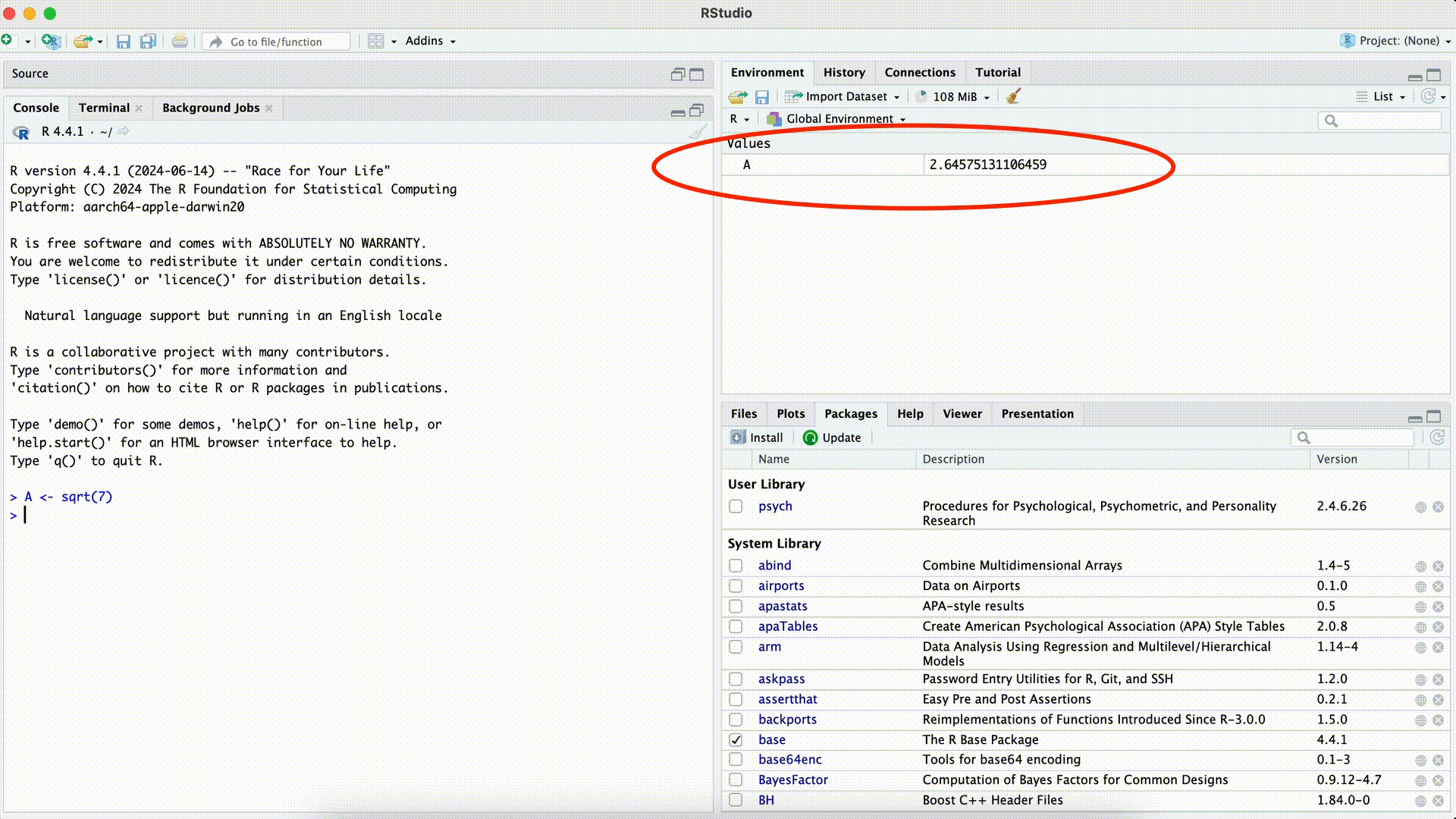
Wenn wir herausfinden wollen, ob die Zuweisung funktioniert hat und das Objekt A nun den Zahlenwert der Quadratwurzel von \(7\) hat, können wir das Objekt A einfach ausführen. Das heißt, wir geben A nach der Zuweisung in die Console ein und drücken auf die Enter-Taste:
A <- sqrt(7)
A[1] 2.645751Wenn wir jetzt nur den Befehl rechts von der Zuweisung ausführen, sehen wir als Ergebnis den gleichen Zahlenwert:
sqrt(7)[1] 2.645751
HinweisHinweis
Wenn wir den Zuweisungsbefehl in der Console durchführen, wird nicht angezeigt welcher konkrete Wert genau zugewiesen wurde. Mit dem Zuweisungsbefehl
A <- sqrt(7)haben wir R nur angewiesen, die Zuweisung durchzuführen. Wir haben nicht den Befehl gegeben, den konkreten Wert anzuzeigen. Angezeigt wird der Inhalt des Objekts nur dann, wenn wir entweder das Objekt links vom Zuweisungspfeil A, oder den Befehl rechts des Zuweisungspfeils sqrt(7) in die Console eintippen und durchführen.
A[1] 2.645751sqrt(7)[1] 2.645751Ein Objekt kann auch überschrieben werden indem ihm mit dem Zuweisungspfeil ein neuer Inhalt zugewiesen wird. Das alte Objekt ist dann allerdings verloren. Bei der Objektzuweisung müssen wir also aufpassen, ob wir den gewählten Namen schon an anderer Stelle verwenden und ob wir das Objekt wirklich endgültig überschreiben wollen. Eine Übersicht bietet das Environment-Fenster, da dort alle bisher erstellen Objekte zusammengefasst sind.
Es wird empfohlen, möglichst eindeutige und sinnhafte Objektbezeichnungen zu wählen, um direkt zu wissen, was der Inhalt des Objekts ist. Z.B. pers_ID <- 123456 für die Zuweisung einer Personen-ID an ein Objekt.
HinweisHinweis
Die Benennung von Objekten ist inhaltlich dem Nutzer überlassen. Vergeben Sie die Namen, die für Sie den Inhalt des benannten Objekts am besten beschreiben. Allerdings sind dabei einige Zeichen nicht erlaubt. Ein Objektname darf in der Regel keine Leerzeichen oder Bindestriche enthalten und nicht mit einer Ziffer oder einem Unterstrich beginnen.
Erlaubt:
mein_Objekt <- 4
mein.Objekt <- 4
mein2tesObjekt <- 4
ObjektNummer2 <- 4Nicht Erlaubt:
mein Objekt <- 4
mein-Objekt <- 4
2tesObjekt <- 4
_ObjektNummer2 <- 4
TippReservierte Objektnamen
Zusätzlich zu den oben genannten Regeln gibt es einige ganz bestimmte Wörter, die als Objektnamen nicht erlaubt sind, weil sie für besondere Objekte reserviert sind. Die Liste aller reservierten Wörter können Sie mit dem folgenden Befehl anzeigen lassen.
?Reserved
VorsichtProbieren Sie es aus!
- Berechnen Sie \(16^3\) und weisen Sie das Ergebnis dem Objekt \(z\) zu.
- Berechnen Sie die Quadratwurzel von \(z\) und weisen Sie das Ergebnis dem Objekt \(y\) zu.
- Berechnen Sie den natürlichen Logarithmus von \(y\) und weisen Sie das Ergebnis dem Objekt \(x\) zu.
- Führen Sie die Schritte 1 - 3 ohne die Zuweisungen der Zwischenergebnisse in einer Zeile Code durch und vergleichen Sie das Ergebnis mit dem in \(x\) gespeicherten Wert.
Lösung
z <- 16 ^ 3
y <- sqrt(z)
x <- log(y)
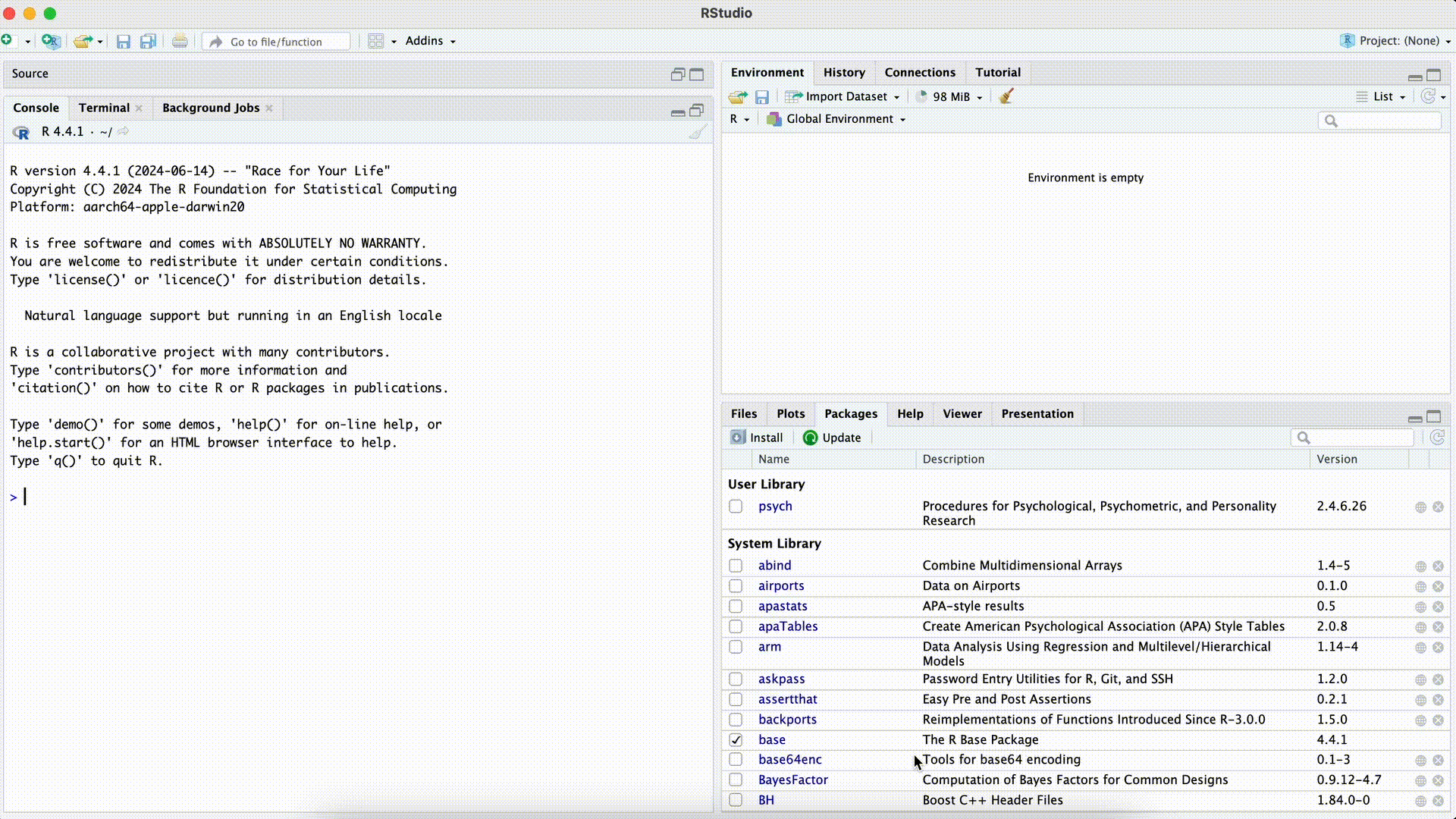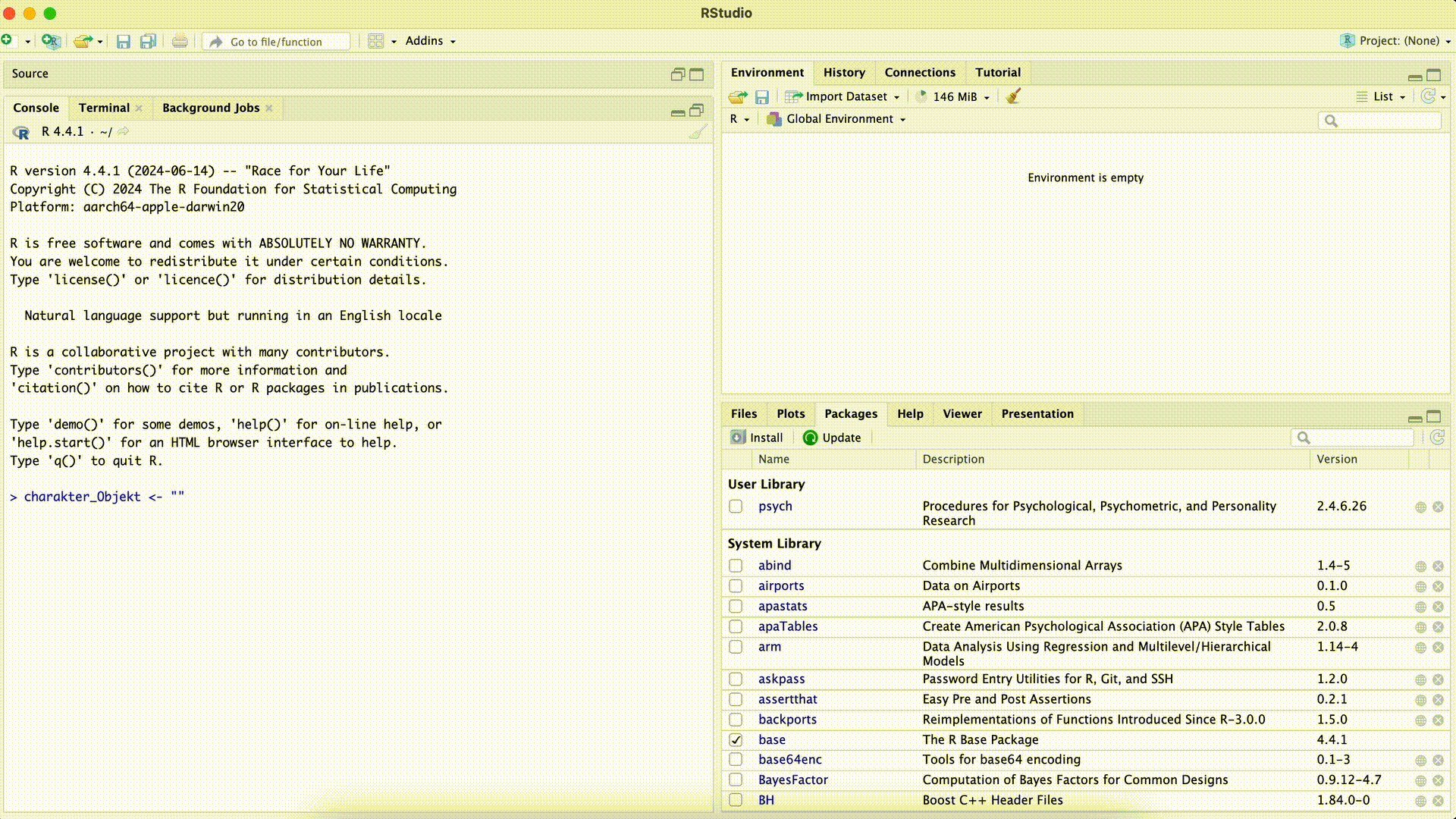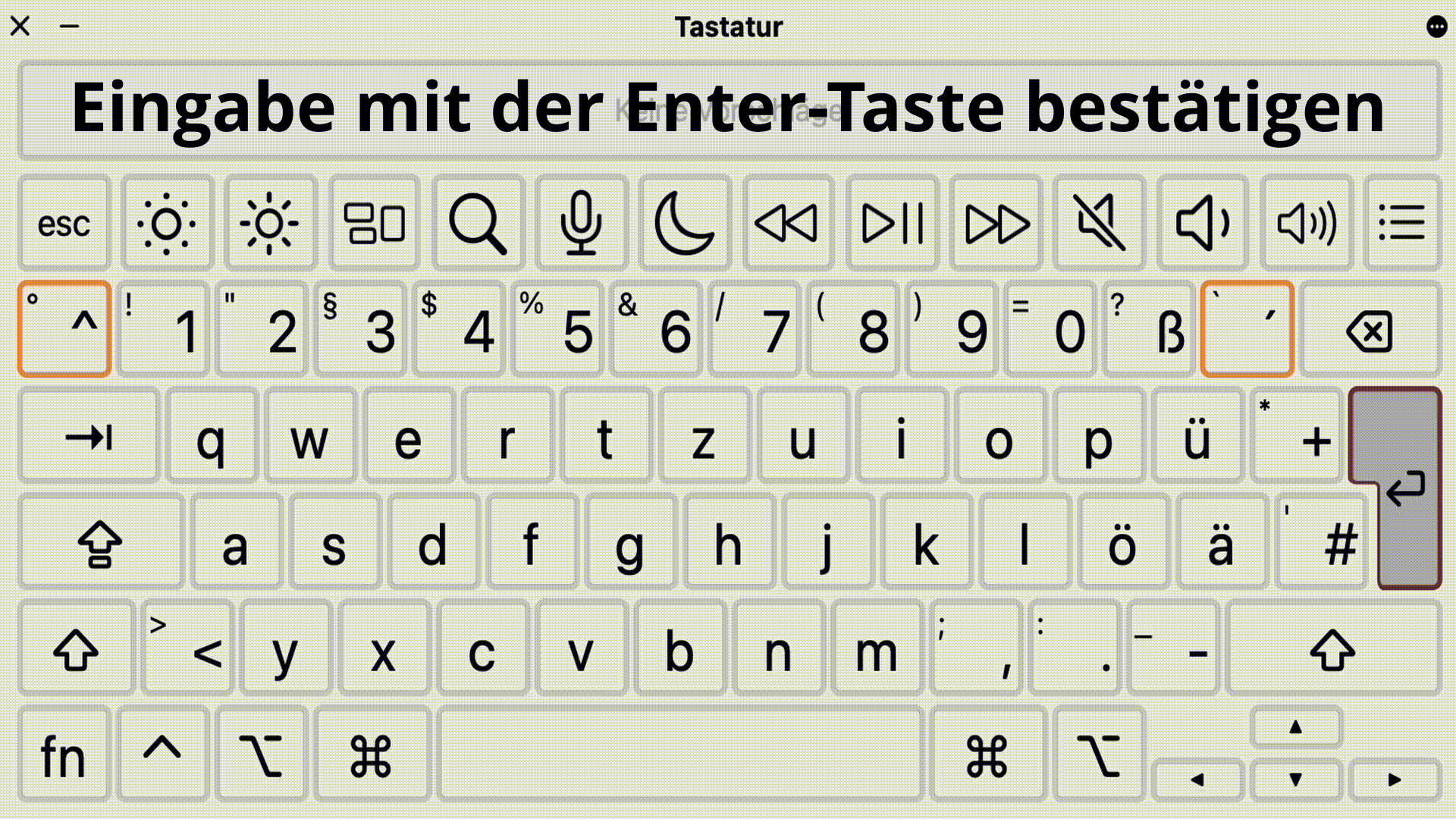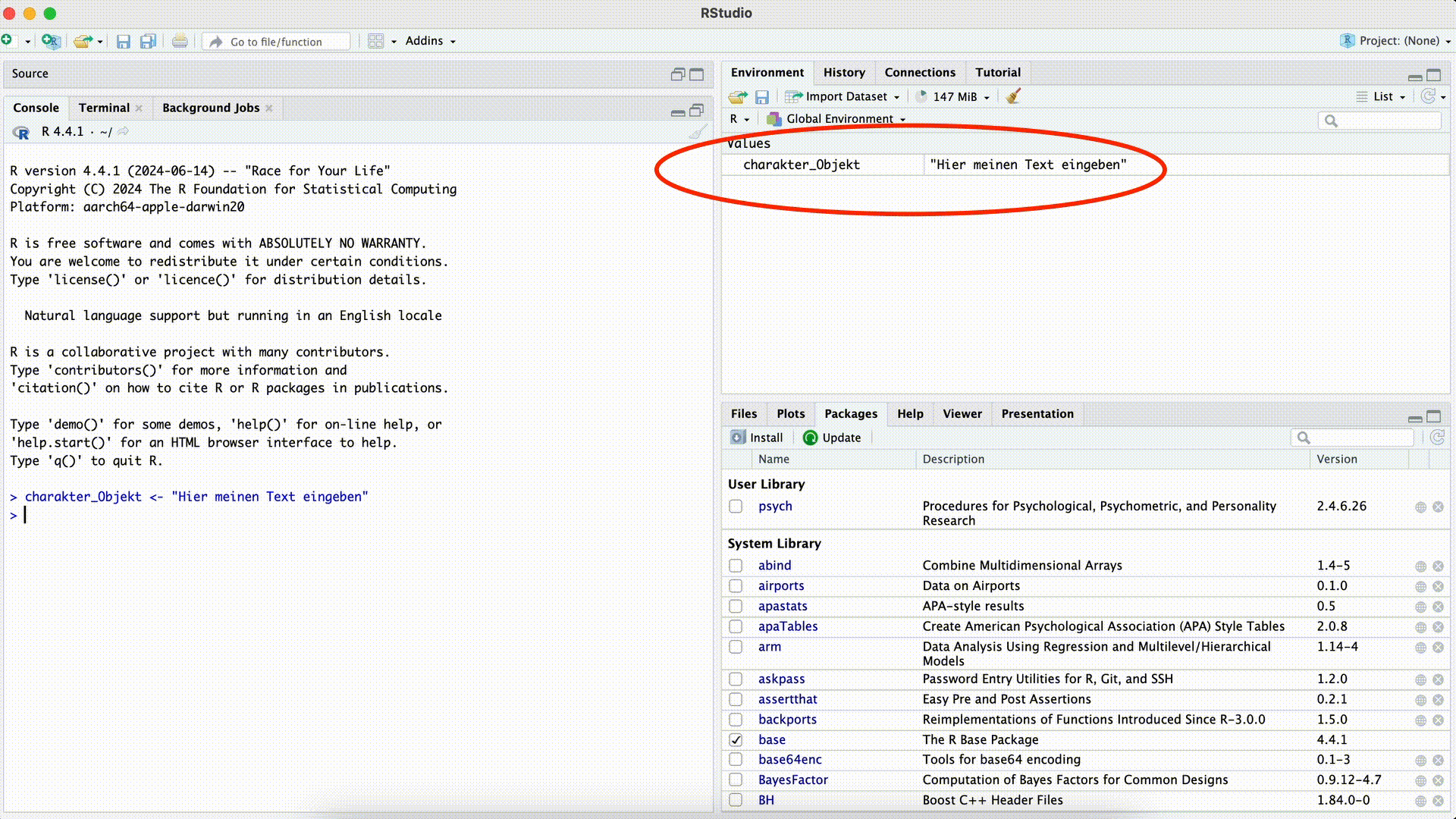
x[1] 4.158883log(sqrt(16 ^ 3))[1] 4.158883Natürlich ist es auch möglich, alle anderen Datentypen einem Objekt zuzuweisen. Speichern wir beispielsweise Text in einem Objekt, so hat dieses Objekt dann den Typ character, wie uns die Information im Environment-Fenster verrät.
Character-Objekt erstellen
2 Reproduzierbares Arbeiten mit RStudio
2.1 R Skripte
Bisher haben wir in der Console programmiert. Theoretisch würde dies ausreichen, um alle Funktionen von R zu nutzen. Das Vorgehen ist jedoch nicht zu empfehlen! Sobald wir RStudio schließen, gehen unsere Berechnungen verloren und sind nicht so einfach reproduzierbar.
Die Verwendung von R in der Console ist in etwa so, als würden wir für die Dekorierung unseres Ballsaals unserem Butler James über den Gang immer wieder einzelne Arbeitsaufträge zurufen, die James dann auch jedes Mal sofort erledigt. Etwas effizienter wäre es in diesem Bild, wenn wir uns überlegen, was wir gerne erledigt haben möchten und eine Liste mit Aufträgen schreiben. Wir drücken dann James diese Liste in die Hand und er erledigt einen Auftrag nach dem Anderen in der Reihenfolge in der sie auf der Liste stehen.
Das hat den Vorteil, dass wir auch am nächsten Tag noch mal auf die Liste schauen können um herauszufinden, welche einzelnen Arbeitsschritte nötig waren um den Ballsaal exakt so zu dekorieren wie beim letzten Mal.
Ein solches Vorgehen wählen wir auch bei der Verwendung von R. Die Liste mit Arbeitsaufträgen für unseren Butler R nennt man hier Skript.
Skript erstellen
Um ein neues Skript zu erstellen, klicken wir oben links in der Titelleiste auf File > New File > R Script. Alternativ können wir in RStudio oben links auf  klicken und R Script auswählen. Das neue Skript öffnet sich im linken oberen Bildschirmbereich.
klicken und R Script auswählen. Das neue Skript öffnet sich im linken oberen Bildschirmbereich.
Skript erstellen
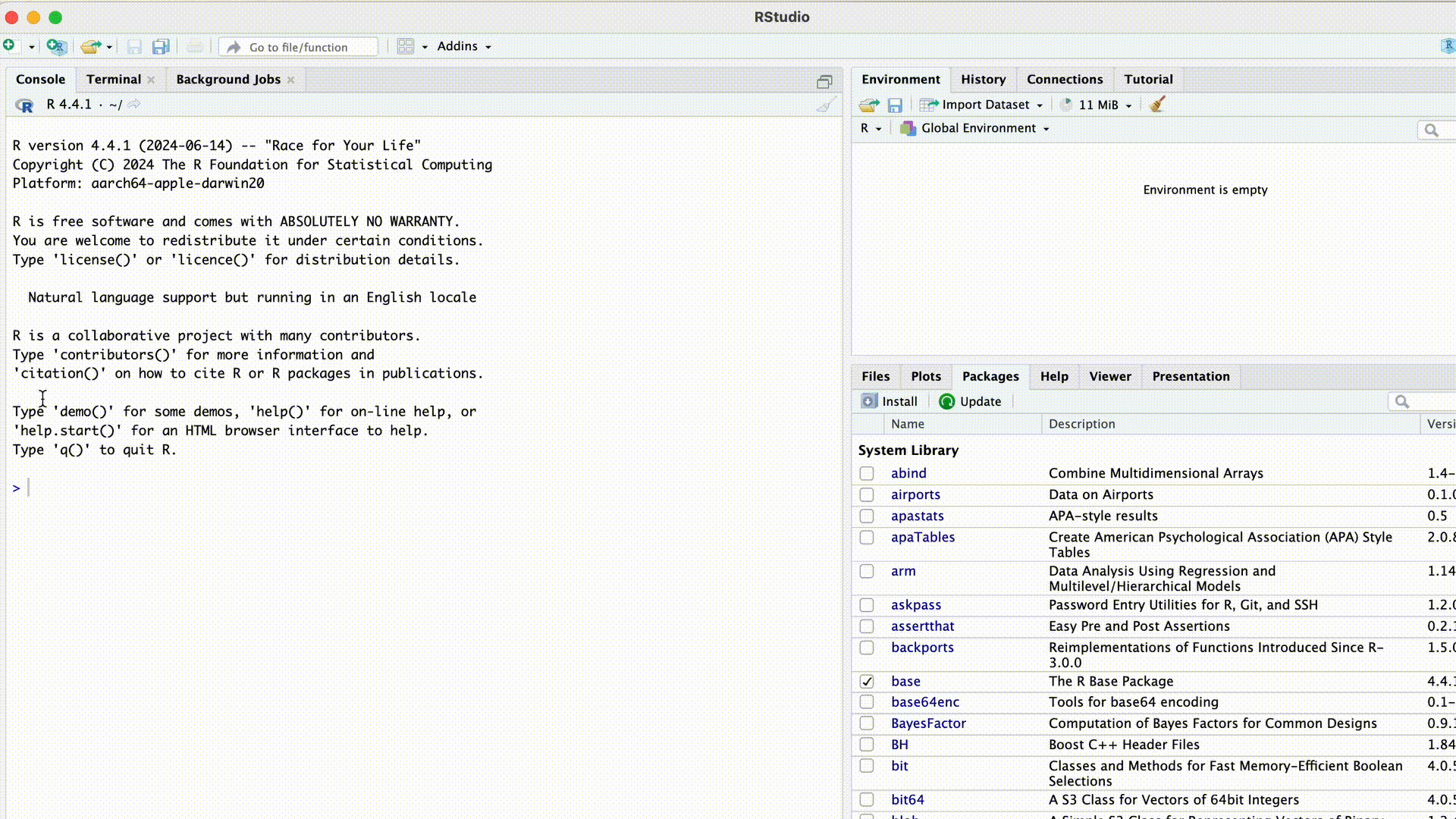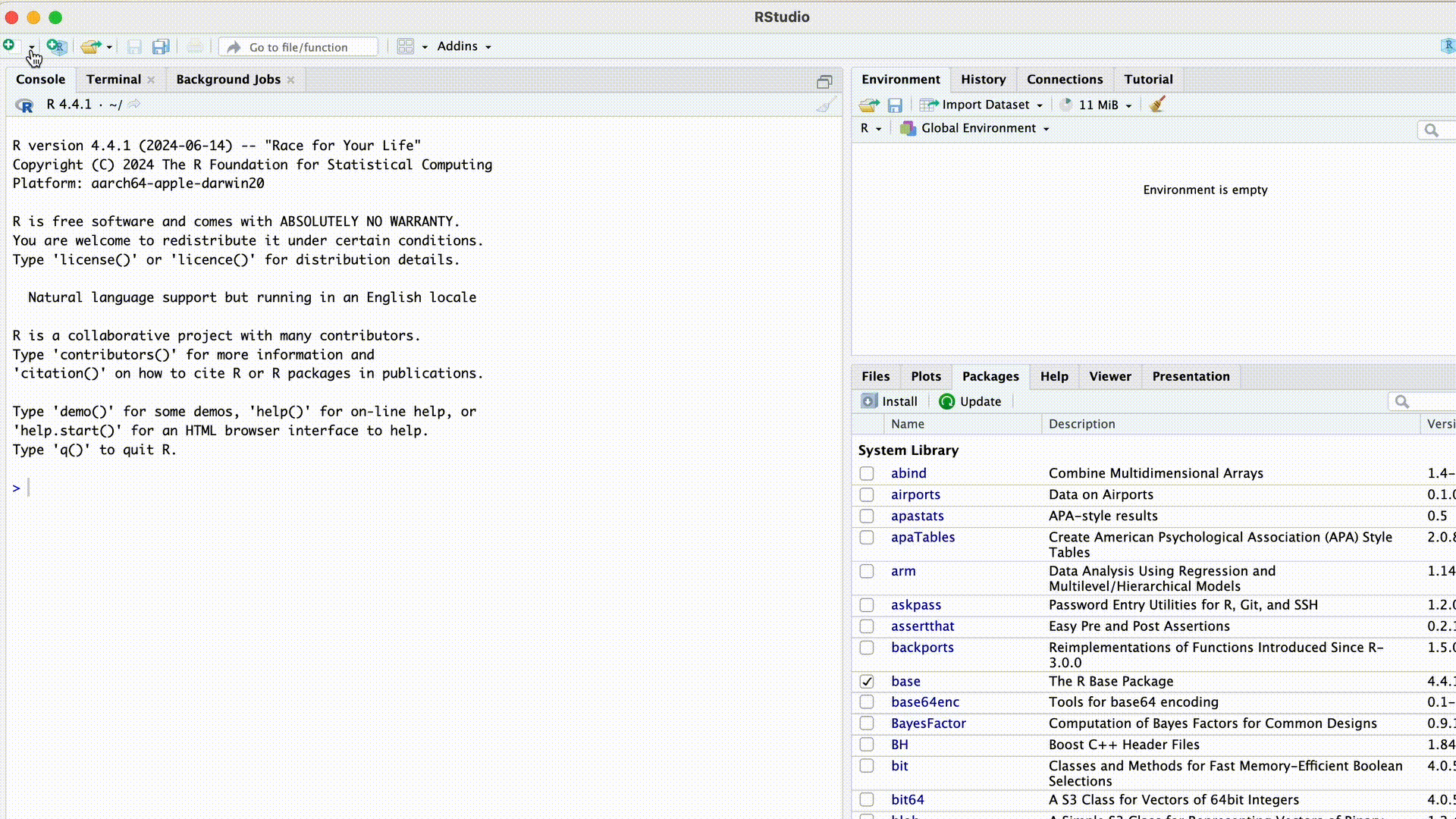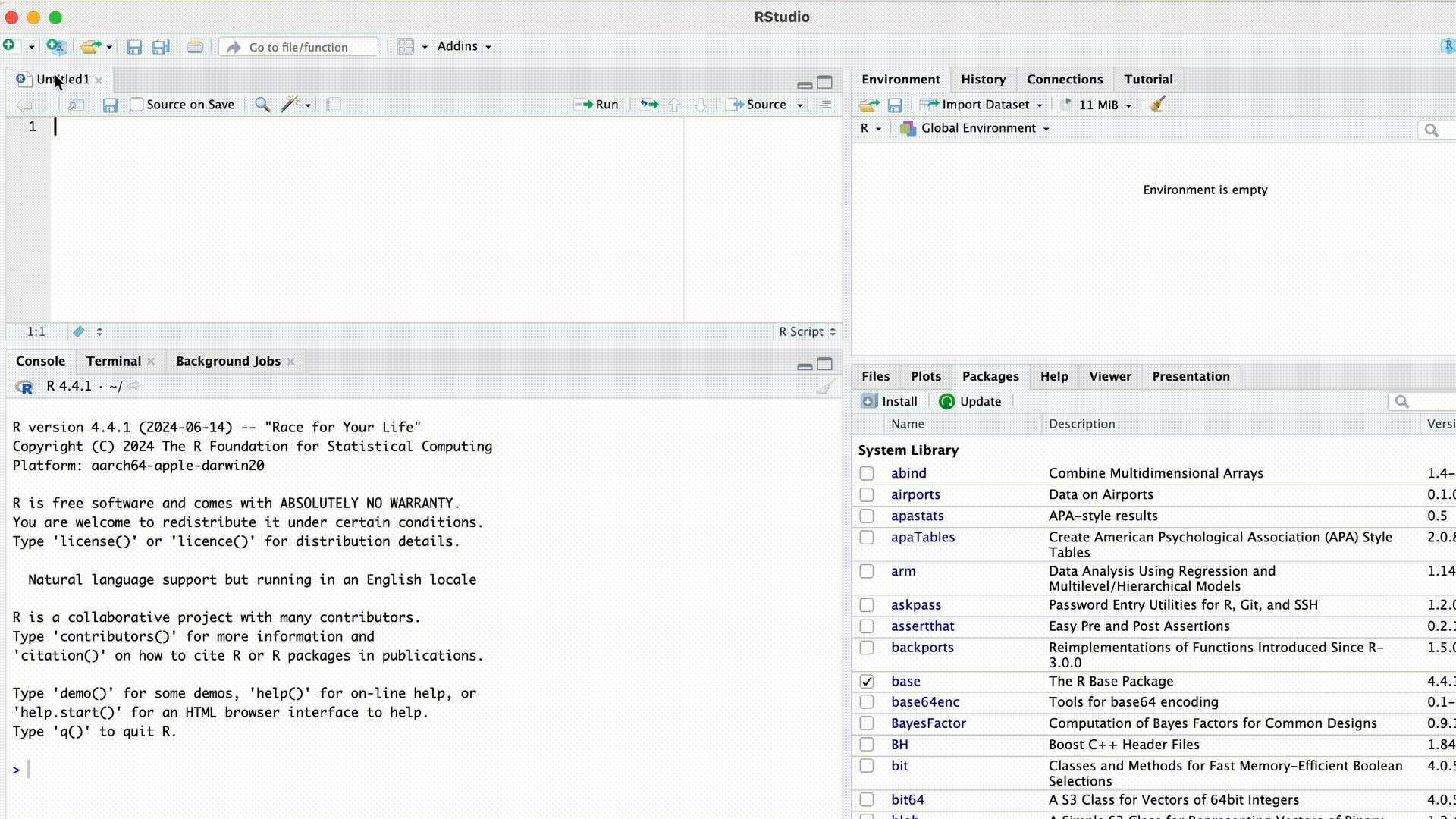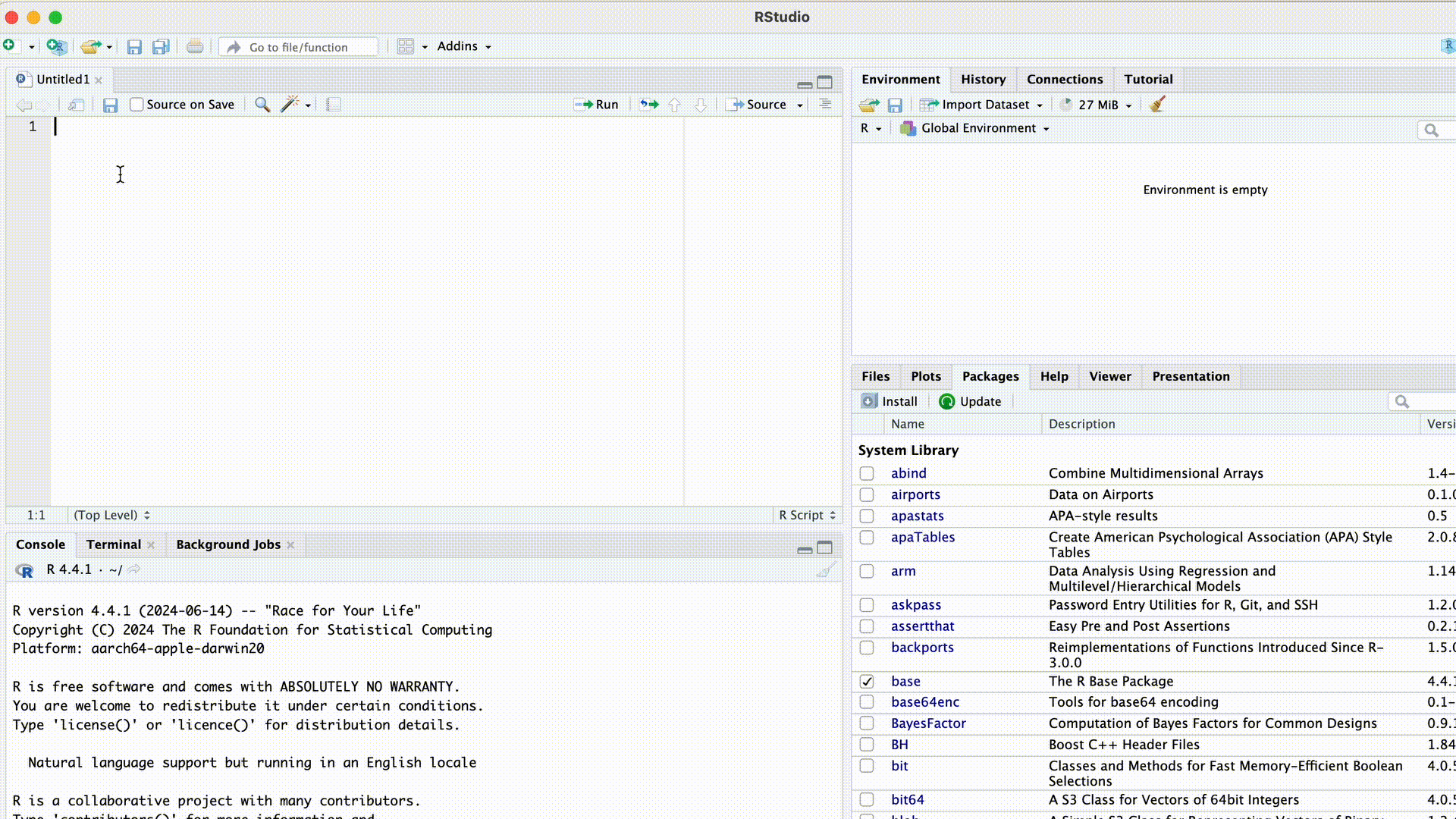
Als wir RStudio nach der Installation das erste Mal geöffnet haben, konnten wir feststellen, dass sich der Bildschirm in drei Bereiche gliedert. Nach dem Erstellen eines Skriptes taucht nun ein vierter Bereich oben links auf:
TippRStudio Fenster anpassen
Das folgende GIF zeigt, wie wir die Größe der einzelnen Fenster in RStudio beliebig verändern können.
Fenstergröße verändern
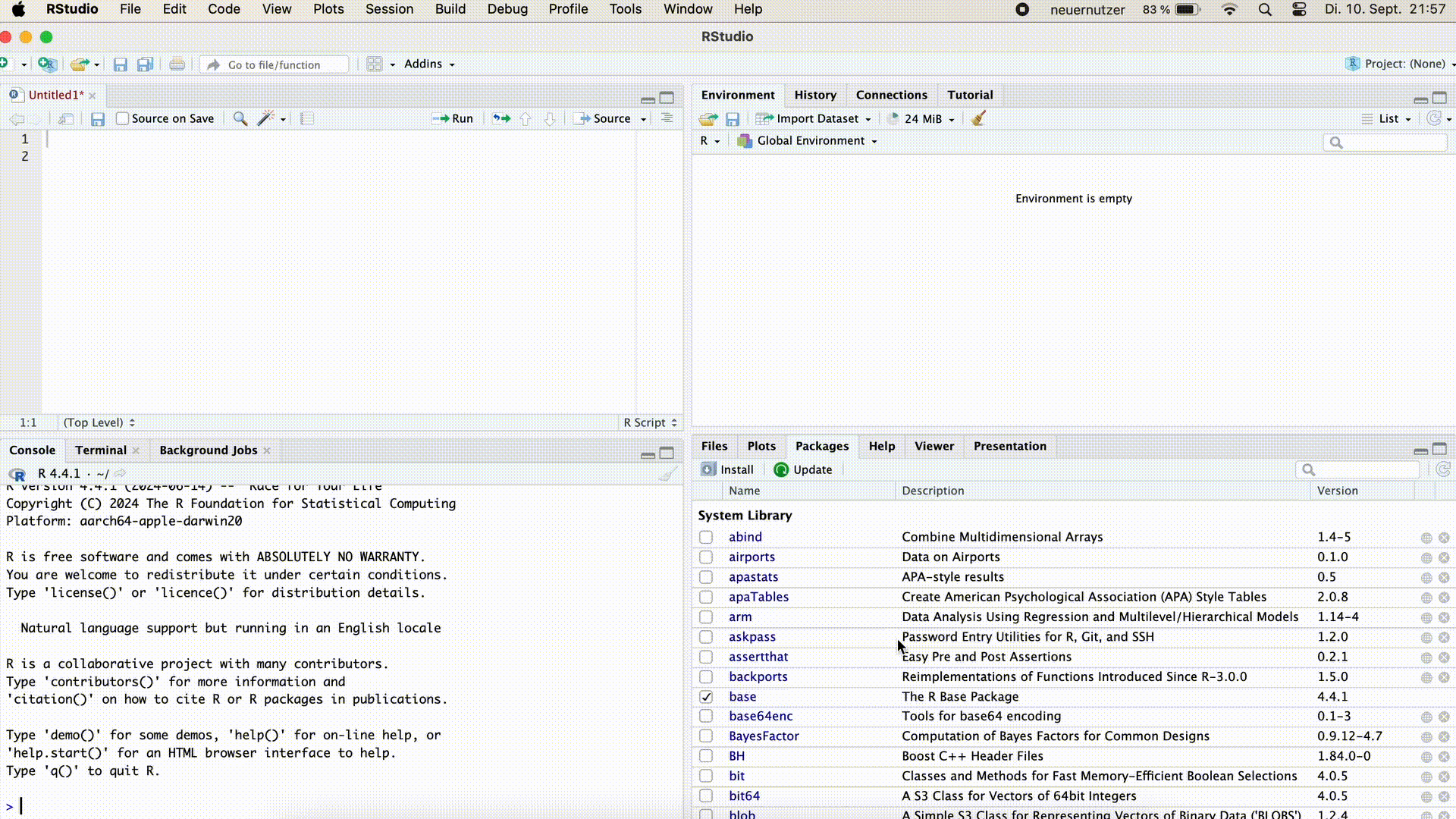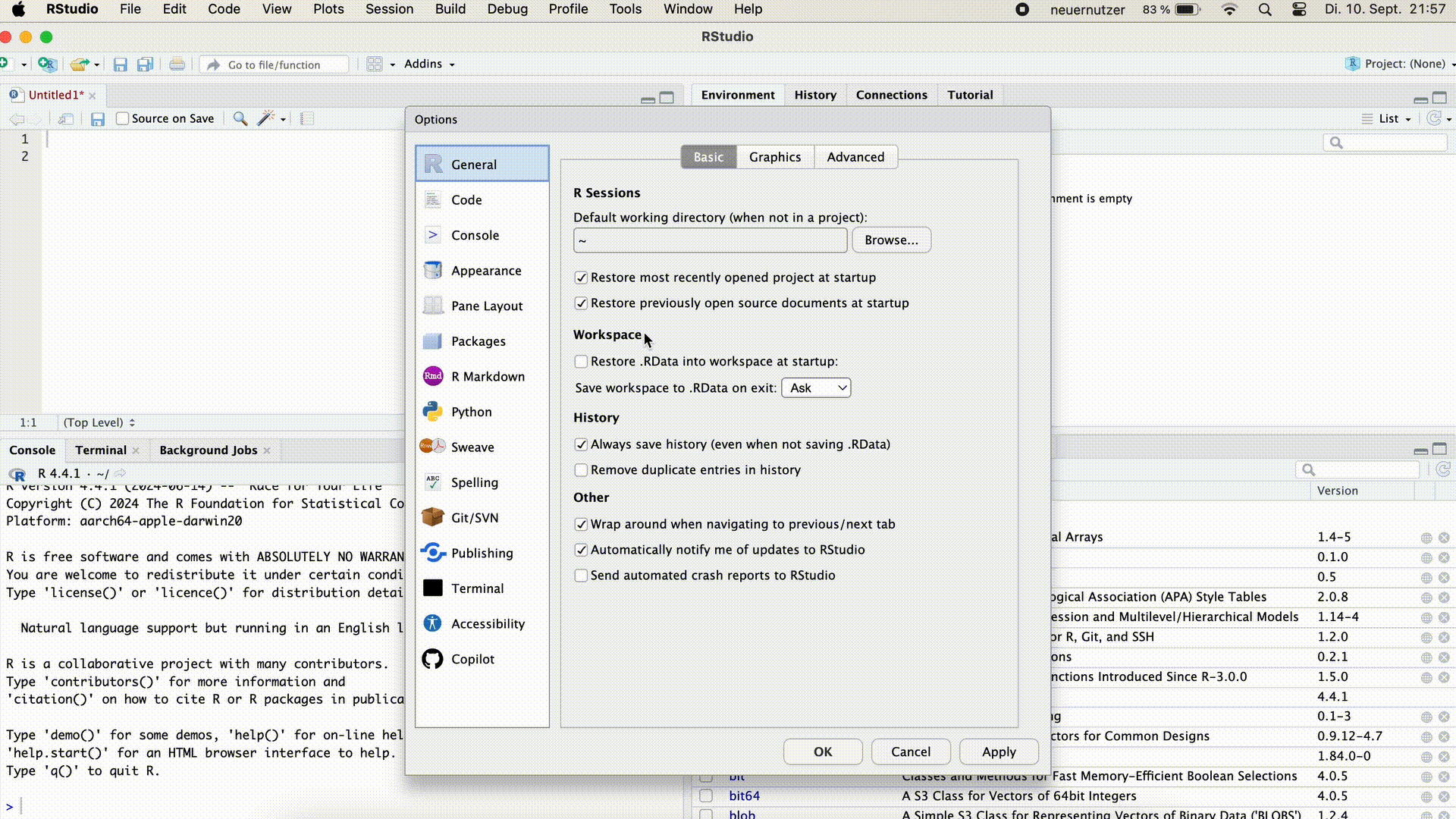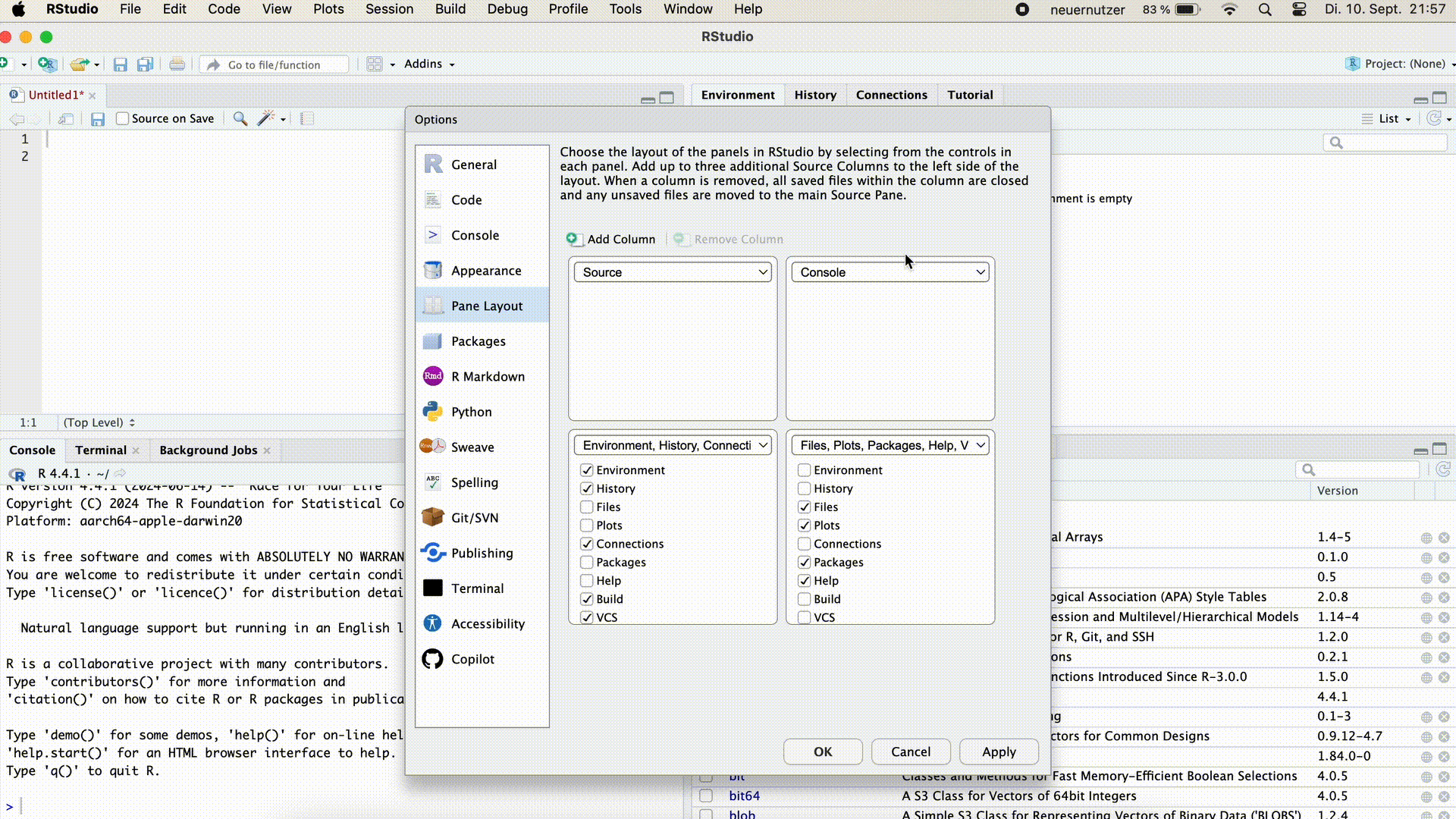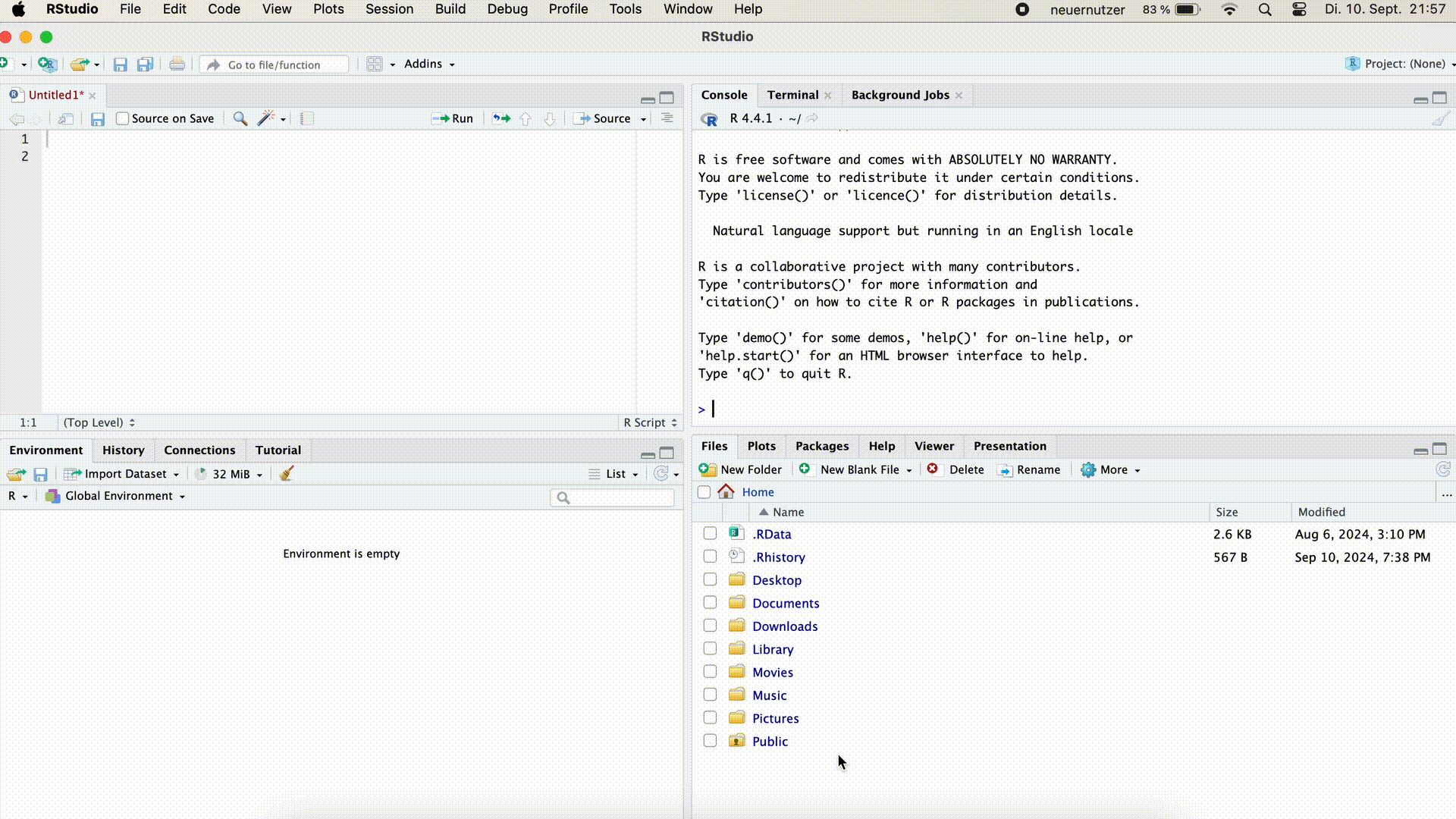
Man kann die Console auch auf der rechten Bildschirmseite neben dem Skript anordnen. Dies kann nützlich sein, wenn wir sowohl das Skript- als auch das Konsolenfenster groß ausgeklappt sehen wollen. Um die Console rechts anzuordnen gehen wir in die Menüleiste > Tools > Globlal Options > Pane Layout. Hier können wir die Fensteranordnung auswählen und mit Apply bestätigen.
Console rechts anordnen
Im Skript können wir jetzt der Reihe nach alle Befehle schreiben, die wir gerne ausführen möchten. Im Gegensatz zur Console wird durch das Drücken der Enter-Taste der Befehl jedoch nicht ausgeführt, sondern es kommt einfach ein Zeilenumbruch und wir können einen weiteren Befehl in die nächste Zeile schreiben.
Das Skript ist also eine Sammlung von Befehlen, die für ein bestimmtes Ziel in einer festen Reihenfolge (Zeile für Zeile von oben nach unten) durchgeführt werden
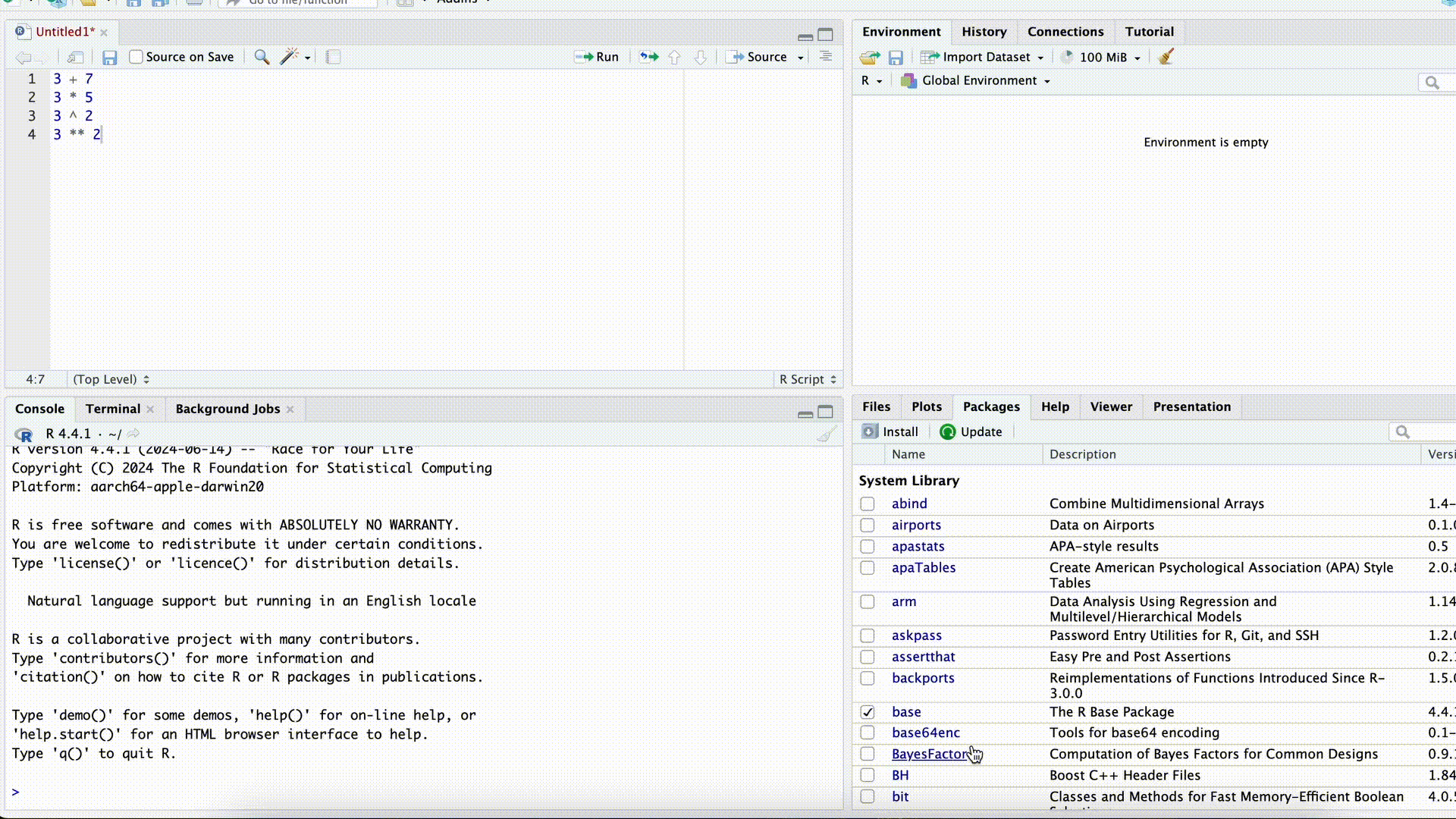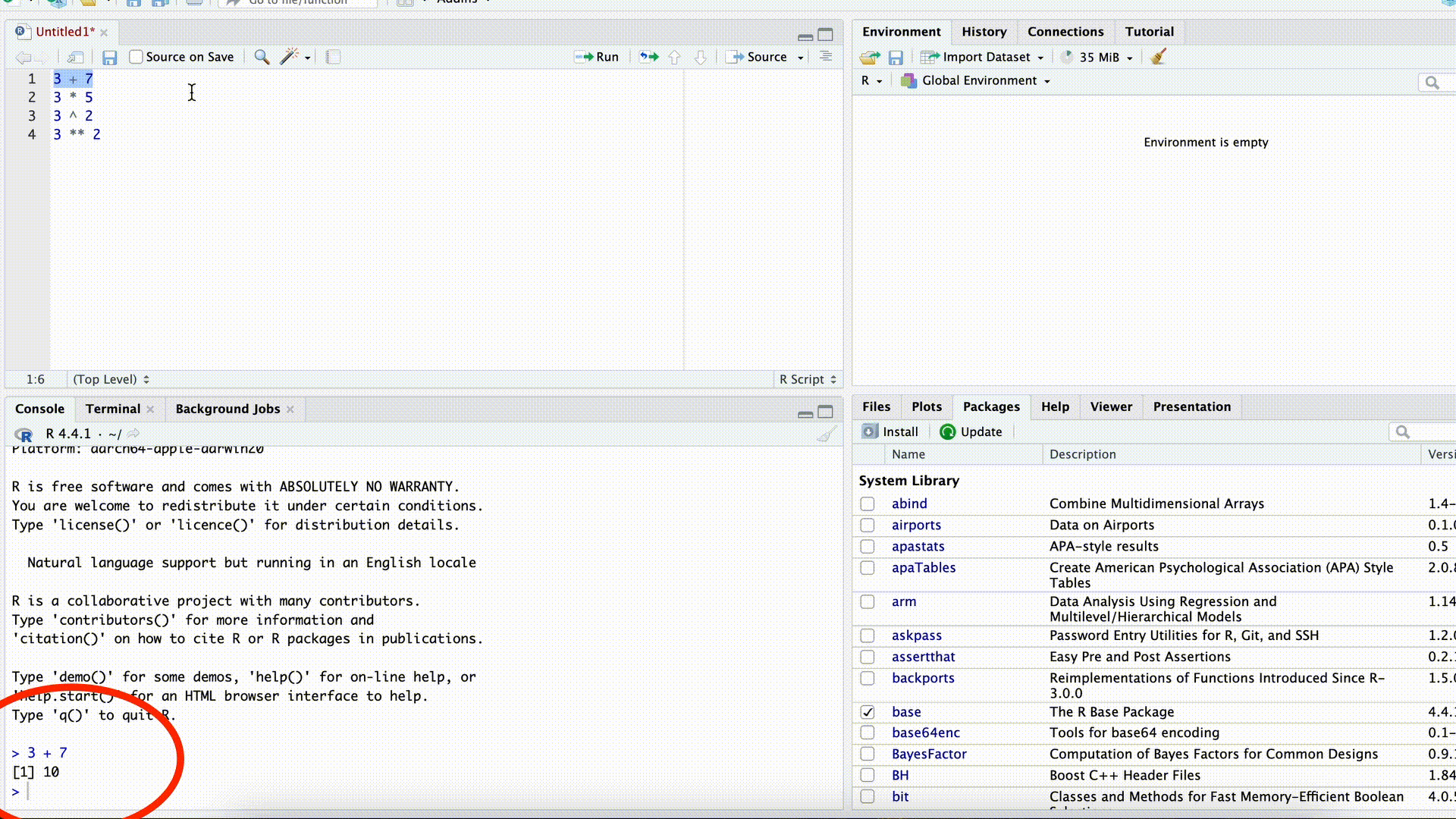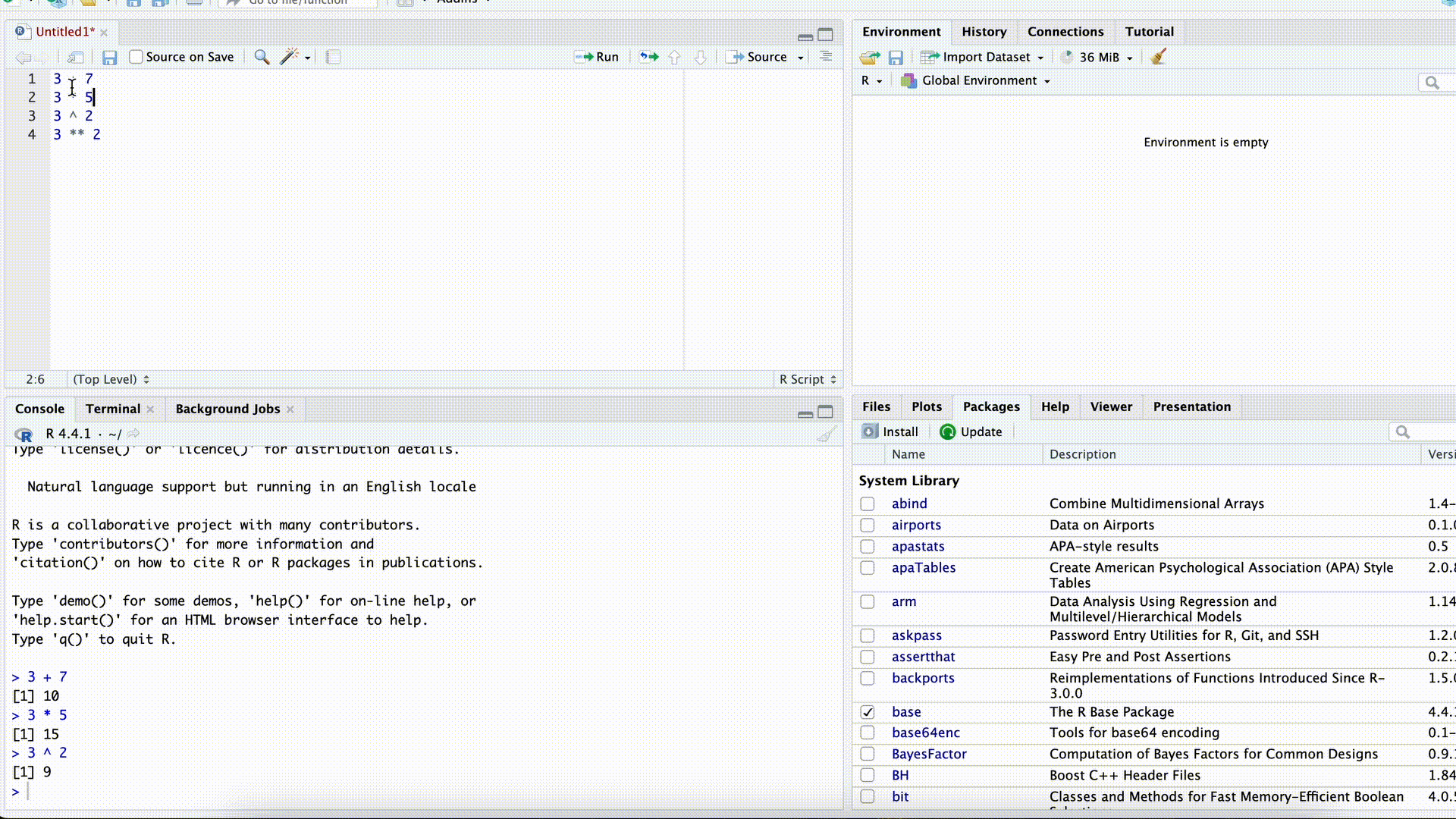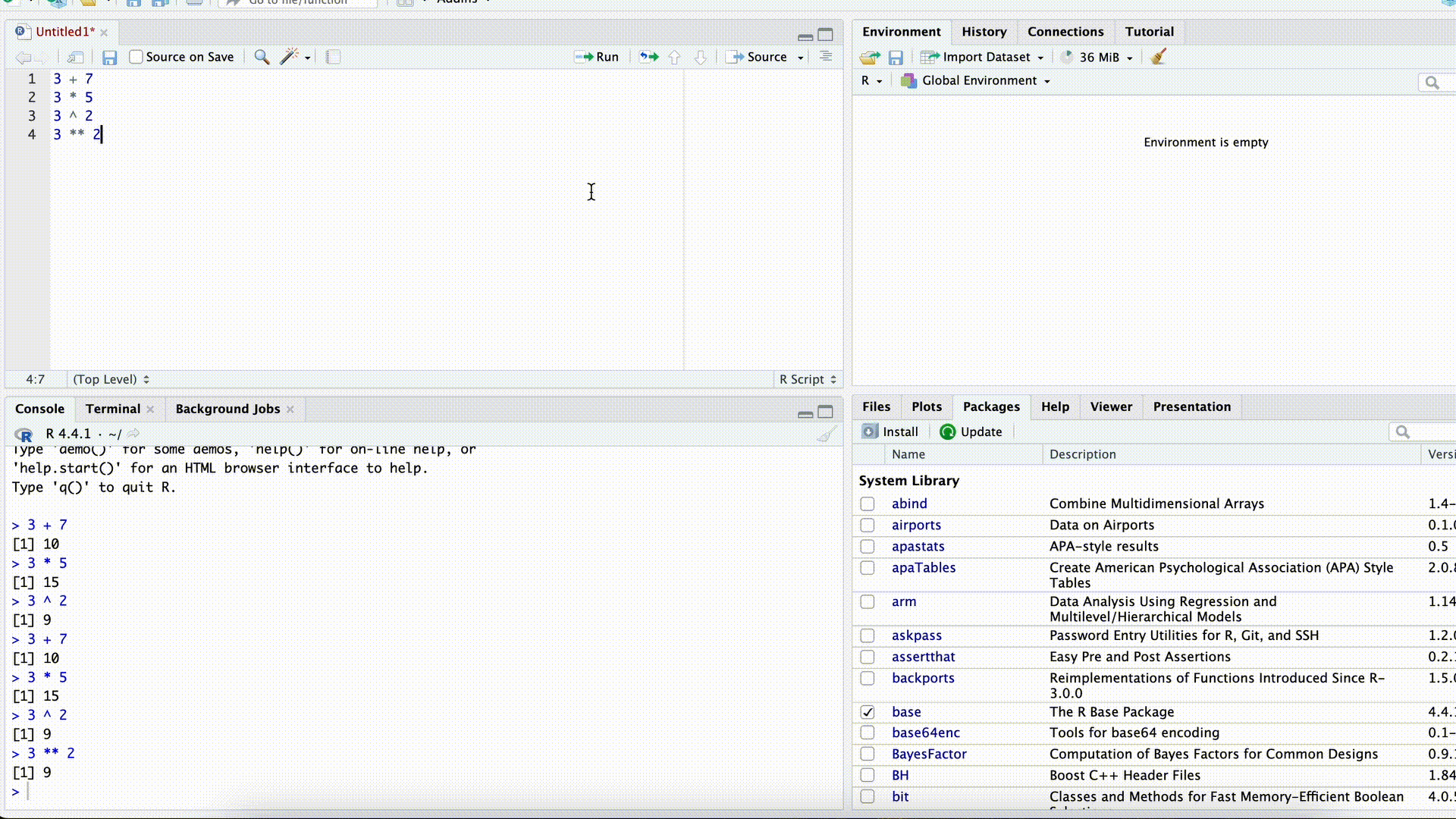
Möchten wir eine Zeile des Skriptes ausführen, können wir den Cursor in diese Zeile setzen (z.B. indem wir mit der Maus irgendwo in die Zeile klicken) und dann
- die Tastenkombination Strg + Enter (engl: Ctrl-Return) drücken. Auf einem Mac funktioniert auch command + Enter.
- im Skript-Fenster oben rechts auf
 klicken.
klicken.
Möchten wir mehrere Zeilen oder bestimmte Teile einer oder mehrerer Zeilen ausführen, können wir auch die gewünschten Befehle markieren und dann mit Variante 1 (Strg + Enter) oder 2 (Klick auf ) ausführen.
Skript ausführen
VorsichtProbieren Sie es aus!
Öffnen Sie ein neues Skript in RStudio
Kopieren Sie die folgenden Zeilen und fügen Sie diese in das neue Skript ein.
x <- 4 y <- 5 x + y # Addition 1 x <- x + y x + y # Addition 2Markieren Sie alle gerade eingefügten Zeilen im Skript und führen Sie den Code mit Strg-Enter (Mac: command-Enter) aus. Was fällt Ihnen auf?
Lösung
x <- 4 y <- 5 x + y # Addition 1[1] 9x <- x + y x + y # Addition 2[1] 14Addition 1 und 2 ergeben zwei unterschiedliche Ergebnisse, weil dazwischen der Wert
xverändert wird.Vertauschen Sie die dritte (
x + y) und vierte Zeile (x <- x + y), markieren Sie den gesamten Code erneut und führen Sie ihn aus. Was fällt Ihnen auf?Lösung
x <- 4 y <- 5 x <- x + y x + y # Addition 1[1] 14x + y # Addition 2[1] 14Addition 1 und 2 ergeben nun die gleichen Ergebnisse, weil der Wert
xnun vor der ersten Addition verändert wurde. Obwohl insgesamt die gleichen Befehle ausgeführt wurden, macht die Reihenfolge der Befehle einen entscheidenden Unterschied.
Skript abspeichern
Um ein Skript abzuspeichern, stehen uns mehrere Möglichkeiten zur Verfügung:
- In der Menüleiste: File > Save
- Mit der Tastenkombination Strg + s (Windows und Mac) oder command + s (nur Mac)
- In R Studio unter dem Symbol
 in der linken oberen Ecke.
in der linken oberen Ecke.
Kommentare
Oft ist es sinnvoll, Kommentare in unser Skript einzubauen, damit andere Personen oder wir selber später nachvollziehen können, was berechnet wurde.
Kommentare schreiben wir hinter ein # Zeichen. Bei der Ausführung des Codes weiß R dann, dass es sich dabei um einen Kommentar handelt, und führt die Zeile nicht aus.
# hier wird 4 hoch 5 berechnet
4 ^ 5[1] 1024Bei Kommentaren die über mehr als eine Zeile gehen, muss zu Beginn jeder Zeile ein # stehen. Es ist auch möglich, direkt hinter einen ausführbaren Befehl einen Kommentar zu schreiben:
4 ^ 5 # hier wird 4 hoch 5 berechnet[1] 1024Wir sehen, dass nur der Code vor dem # ausgeführt wird.
TippWas sind “nützliche” Kommentare
Wenn Sie R neu lernen, macht es durchaus Sinn mit Kommentaren festzuhalten, was die Befehle in Ihrem Skript bewirken. Je besser Sie sich mit R auskennen, desto seltener brauchen Sie solche Kommentare, da die Information was Ihr Code tut streng genommen aus den Befehlen selbst hervorgeht (schließlich könnten Sie durch eigene Recherche jederzeit wieder herausfinden, wie die Befehle funktionieren). Umso nützlicher sind daher Kommentare, warum ein bestimmter Code notwendig ist um das Ziel Ihrer Analyse zu erreichen (und warum Sie nicht z.B. einen anderen Weg gewählt haben). Solche Informationen sind nicht sofort aus dem Code selbst ersichtlich und es ist immer wieder erstaunlich, wie schnell man vergisst, was man sich damals dabei gedacht hat als man etwas programmiert hat.
2.2 Umgang mit dem Workspace
Wenn wir in R arbeiten, erstellen wir dabei in der Regel verschiedene Objekte (z.B. x <- 42), die dann in unserem Environment Fenster in RStudio angezeigt werden. Irgendwann sind wir für heute fertig mit unserer statistischen Analyse und wollen RStudio gerne schließen. Schließen wir RStudio, werden wir vom Programm gefragt, ob wir den Workspace, der alle unsere R Objekte aus dem Environment Fenster (und noch ein paar andere Sachen) enthält, speichern wollen.
Im Gegensatz zu unserem R Skript wollen wir den Workspace (in 99% der Fälle) nicht speichern!
HinweisWarum wollen wir den Workspace nicht speichern?
- Nur was in unserem R Skript steht ist reproduzierbar! Wenn wir zwischendurch in der R Console Dinge ausprobiert, in unserem Skript Befehle gelöscht oder angepasst haben, wissen wir nicht mehr genau, wie die Objekte im Environment zustande gekommen sind.
- Daher ist es gute Praxis, sich selbst zu zwingen, dass alle für die Analyse notwendigen und speicherwürdigen Schritte im Skript enthalten sind und dass wir jedes mal wenn wir mit R arbeiten mit einer “frischen” Arbeitsumgebung (= leeres Environment) starten.
Wenn wir RStudio das nächste mal öffnen und wir hätten beim Schließen den Workspace gespeichert, würden alle R Objekte vom letzten mal automatisch wieder geladen. Das mag auf den ersten Blick vielleicht praktisch erscheinen, führt in der Praxis jedoch sehr häufig zu Problemen.
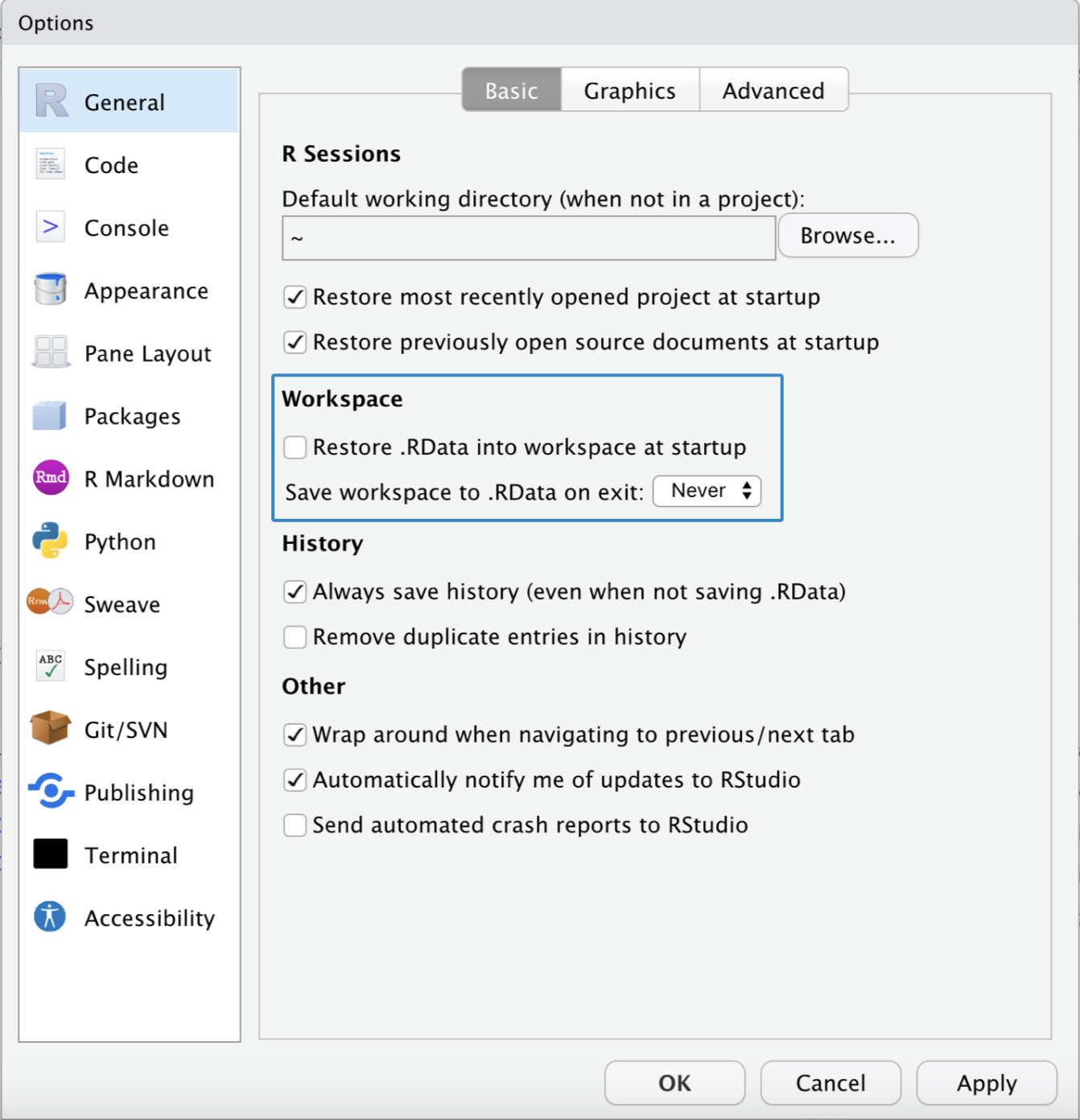
Workspace Einstellungen anpassen
Wir können in den Einstellungen von RStudio festlegen, dass…
- beim Öffnen kein Workspace geladen werden soll und
- beim Schließen von RStudio der Workspace nicht gespeichert wird und wir auch nicht mehr danach gefragt werden.
Dafür klicken wir in RStudio auf Tools > Global Options und wählen die in der Abbildung blau markierten Einstellungen aus.
VorsichtProbieren Sie es aus!
Passen Sie wie beschrieben die Workspace Einstellungen in RStudio an.
Erstellen Sie mindestens ein R Objekt, z.B. mit dem Befehl
x <- 10. Schließen Sie RStudio und beobachten Sie, dass Sie nicht danach gefragt werden, ob Sie den Workspace speichern wollen (Wenn Sie Änderungen an einem R Skript vorgenommen haben, werden Sie immer trotzdem gefragt, ob Sie das Skript speichern wollen).Öffnen Sie RStudio erneut und überprüfen Sie, dass das zuvor erstellte R Objekt nicht mehr existiert. Sie können dafür entweder versuchen das Objekt anzuzeigen (z.B. indem Sie in der Console den Namen des Objekts eingeben und Enter drücken) oder Sie versichern sich, dass das Environment-Fenster in RStudio leer ist.
2.3 R im Hintergrund neu starten
Auch während wir in RStudio arbeiten ist es sinnvoll, regelmäßig R “zurückzusetzen” und eine “frische Arbeitsumgebung” (= leeres Environment) zu schaffen. Damit wollen wir sicherstellen, dass der Code in unserem R Skript wie erwartet funktioniert und wir alle wichtigen Analyseschritte auch wirklich reproduzieren können.
Anstatt RStudio aufwendig zu schließen und wieder neu zu öffnen, können wir stattdessen im Hintergrund R neu starten, indem wir in RStudio entweder…
- auf Session > Restart R klicken oder
- die Tastenkombination command + Shift + 0 für Mac oder Strg + Shift + F10 für Windows verwenden.
Danach können wir entweder…
- unseren Code im Skript Schritt für Schritt manuell neu ausführen oder
- mit der Tastenkombination command + Shift + Enter für Mac oder Strg + Shift + Enter für Windows das komplette aktuell geöffnete Skript ausführen.
VorsichtProbieren Sie es aus!
Erstellen Sie ein neues R Skript das nur die folgenden drei Zeilen enthält:
x <- 1 y <- 2 x + yFühren Sie die drei Befehle im Skript der Reihe nach aus.
Geben Sie direkt in der Console den folgenden Befehl ein:
y <- xFühren Sie die 3. Zeile des Skripts erneut aus und vergleichen Sie das Ergebnis mit dem Ergebnis, dass jemand erwarten würde der nur das Skript kennt.
Starten Sie R im Hintergrund neu, indem Sie die beschriebene Tastenkombination verwenden.
Führen Sie das komplette Skript neu aus, indem Sie die beschriebene Tastenkombination verwenden. Überprüfen Sie das Ergebnis.
3 Arbeiten mit Daten
3.1 Funktionen
Argumente
Funktionen führen Operationen für uns durch, indem wir ihnen bestimmte Eingabewerte, sogenannte Argumente, übergeben. Vergleichbar ist das mit den mathematischen Funktionen, die angeben, welche Berechnungen mit dem Argument \(x\) angestellt werden sollen, um zu einem Ergebnis \(y\) zu gelangen, z.B.
\[ f(x) = x^2 + 5 \] Funktionen in R können ähnlich dazu ein oder mehrere Argumente verarbeiten und uns Ergebnisse wie Mittelwerte, Summen oder komplexere Berechnungen zurück liefern.
Ein Beispiel
Eine einfachere Funktion ist die Exponential-Funktion \(e^x\). Ihr einziges Argument ist der Exponent.
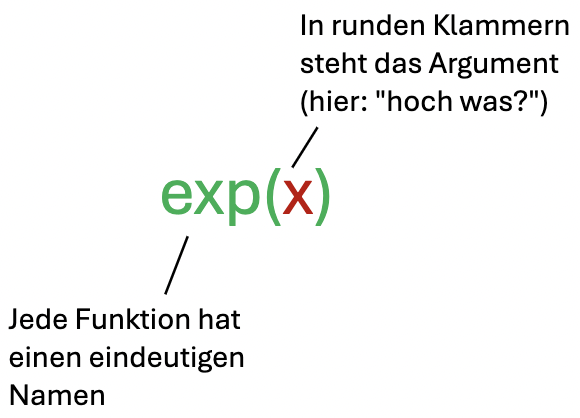
Verwendung der Exponentialfunktion in R für \(x = 1\):
exp(1)[1] 2.718282Oft ist es zweckmäßig, ein Ergebnis von Funktionen gleich wieder als Argument einer weiteren Funktion zu verwenden. Diese Funktionen sind dann in einer bestimmten Reihenfolge ineinander verschachtelt.
Ein Beispiel
Um \(e^{\sqrt{x}}\) zu berechnen würden wir zunächst die Quadratwurzel von \(x\) mit der Funktion sqrt(x) berechnen und das Ergebnis dann als Argument in die Exponentialfunktion exp() einsetzen:
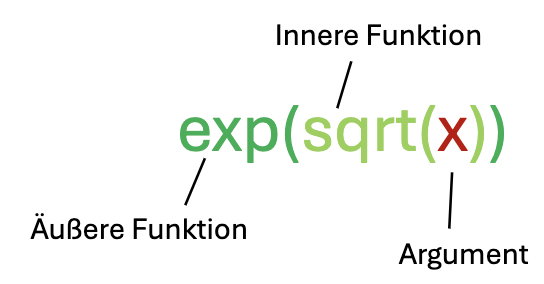
WarnungVorsicht
Die Reihenfolge der Verschachtelung spielt eine Rolle, z.B.:
\(e^{\sqrt{1}} \neq \sqrt{e^{1}}\)
exp(sqrt(1))[1] 2.718282sqrt(exp(1))[1] 1.648721Auch in der Mathematik ist es möglich, in einer Funktion mehr als ein Argument zu verarbeiten, wie z.B. in der Gleichung für einer Ebene im dreidimensionalen Raum:
\[ f(x, y) = 2x + 3y \]
Genauso gibt es in R viele Funktionen, die mehrere Argumente benötigen. Diese sind dann innerhalb eines Befehls mit Kommata voneinander getrennt und haben eindeutige Bezeichnungen um sie voneinander zu unterscheiden. Für manche Argumente gibt es default-Einstellungen, also Voreinstellungen, die R verwendet, wenn wir für ein Argument keine Angabe machen.
Ein Beispiel
Dies wird deutlich am Beispiel der round(x, digits) Funktion, die eine Zahl auf beliebig viele Nachkommastellen rundet. Als erstes Argument übergeben wir der Funktion die zu rundende Zahl, als zweites Argument die Anzahl der Nachkommastellen. Der Name des Arguments, das die Anzahl der Nachkommastellen bestimmt, lautet digits. Der Default (die Voreinstellung, wenn man kein Argument für digits übergibt) ist Null. Es wird also auf null Nachkommastellen gerundet.
.png)
Die Funktion round(4.12345, digits = 2) rundet die Zahl 4.12345 auf zwei Nachkommastellen, also auf 4.12.
HinweisMüssen Argumente benannt werden oder nicht?
Sie werden im weiteren Verlauf feststellen, dass Argumente auf zwei Arten angegeben werden. Im Beispiel oben round(4.12345, digits = 2) ist das erste Argument, die zu rundende Zahl 4.12345 unbenannt angegeben worden und das zweite Argument, die Anzahl der gewünschten Nachkommastellen 2 wurde mit der Bezeichnung digits = benannt.
Grundsätzlich sind bei jedem Argument beide Varianten möglich, führen aber nur dann zum gleichen Ergebnis, wenn die von einem Befehl erwartete Reihenfolge der Argumente eingehalten wurde. Werden die Argumente grundsätzlich nicht benannt, weiß ein Befehl ja nicht, ob die 2 die zu rundende Zahl sein soll oder die Nachkommastellen. Wir können das dem Befehl klar machen, in dem wir die Reihenfolge der Argumente einhalten, die auf der jeweiligen Hilfeseite (siehe Abschnitt 3.1.2) angegeben ist.
Weniger fehleranfällig und deutlich übersichtlicher wird es, wenn wir die folgende Konvention einhalten:
- Das erste Argument eines Befehls (das Hauptargument mit dem der Befehl arbeitet) wird nicht benannt.
- Alle weiteren Argumente die wir angeben wollen, werden mit der zugehörigen Benennung (z.B.
digits =) angegeben.
VorsichtProbieren Sie es aus!
round(4.12345, 2)[1] 4.12führt zum gleichen Argebnis wie
round(x = 4.12345, digits = 2)[1] 4.12Wohingegen
round(2, 4.12345)[1] 2Nicht zum gewünschten Ergebnis führt. Der Befehl denkt, die Ziffer 2 soll auf 4.12345 Nachkommastellen gerundet werden. Die Angabe von Nachkommastellen bei einer Anzahl ist zwar blödsinnig, der Befehl löst das jedoch dadurch, indem er die Nachkommastellen einfach ignoriert und versucht, die 2 einfach auf vier Nachkommastellen zu runden.
Durch die Benennung der Argumente könnten wir auf die richtige Reihenfolge verzichten:
round(digits = 2, x = 4.12345)[1] 4.12Obwohl das durchaus funktionieren würde ist diese Umkehrung der Reihenfolge eher unüblich. Eine weit verbreitete Style-Konvention schlägt vor, dass das Hauptargument des Befehls, das auch an erster Stelle erwartet wird unbenannt bleibt und alle weiteren Argumente in beliebiger Reihenfolge aber dafür benannt werden:
round(4.12345, digits = 2)[1] 4.12
TippFunktionen ohne Argument
In R gibt es auch Funktionen ganz ohne Argument, wie zum Beispiel:
Sys.time() # der Zeitpunkt, zu dem diese Funktion ausgeführt wurde[1] "2025-11-08 13:20:22 CET"Auf der technischen Ebene wird immer wenn in R irgendetwas passiert (etwas berechnen, anzeigen, oder sonst irgendwelche Informationen verarbeiten) eine Funktion ausgeführt.
Hilfe
Wenn wir wissen möchten, wie eine Funktion arbeitet, also z.B. wie die einzelnen Argumente heißen, brauchen wir die Hilfe. Die Hilfe finden wir im „Multifunktionsfenster“ rechts unten beim Reiter Help.
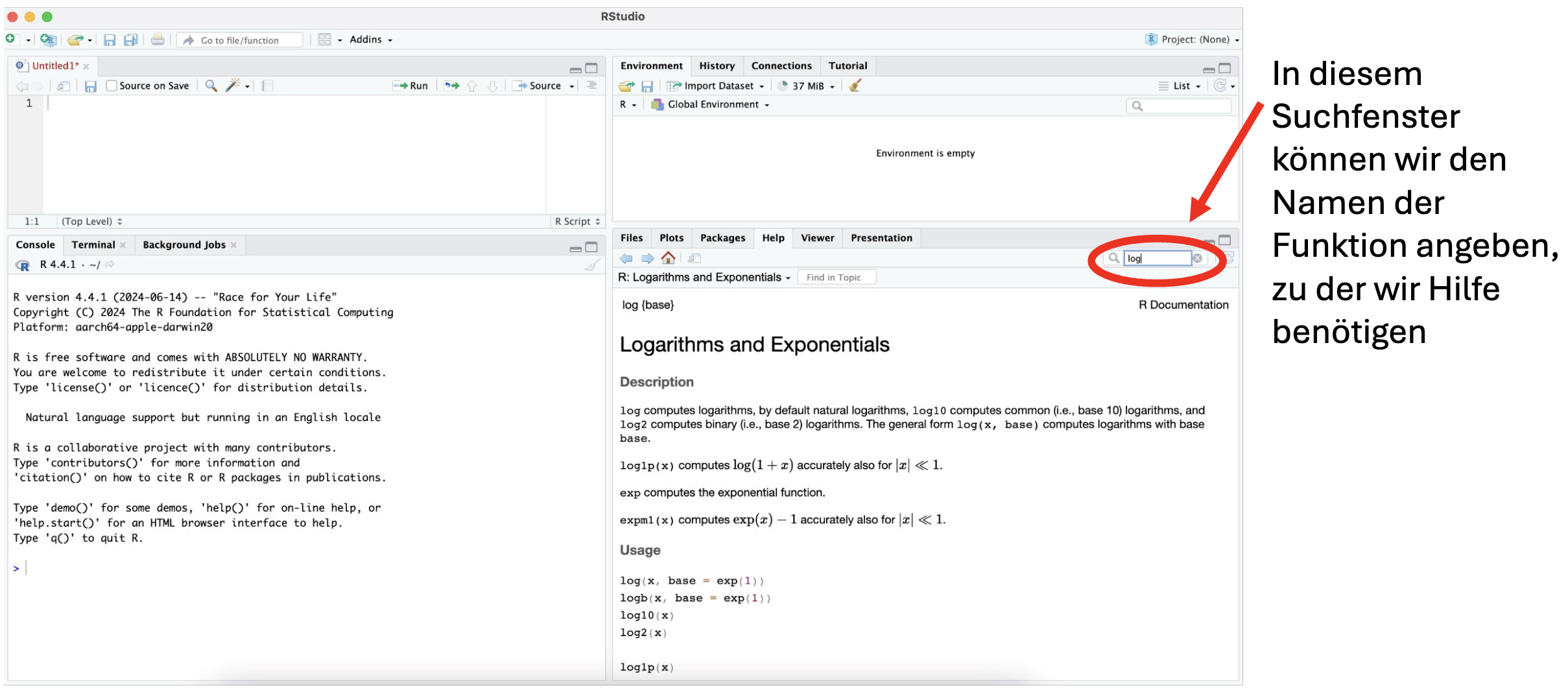
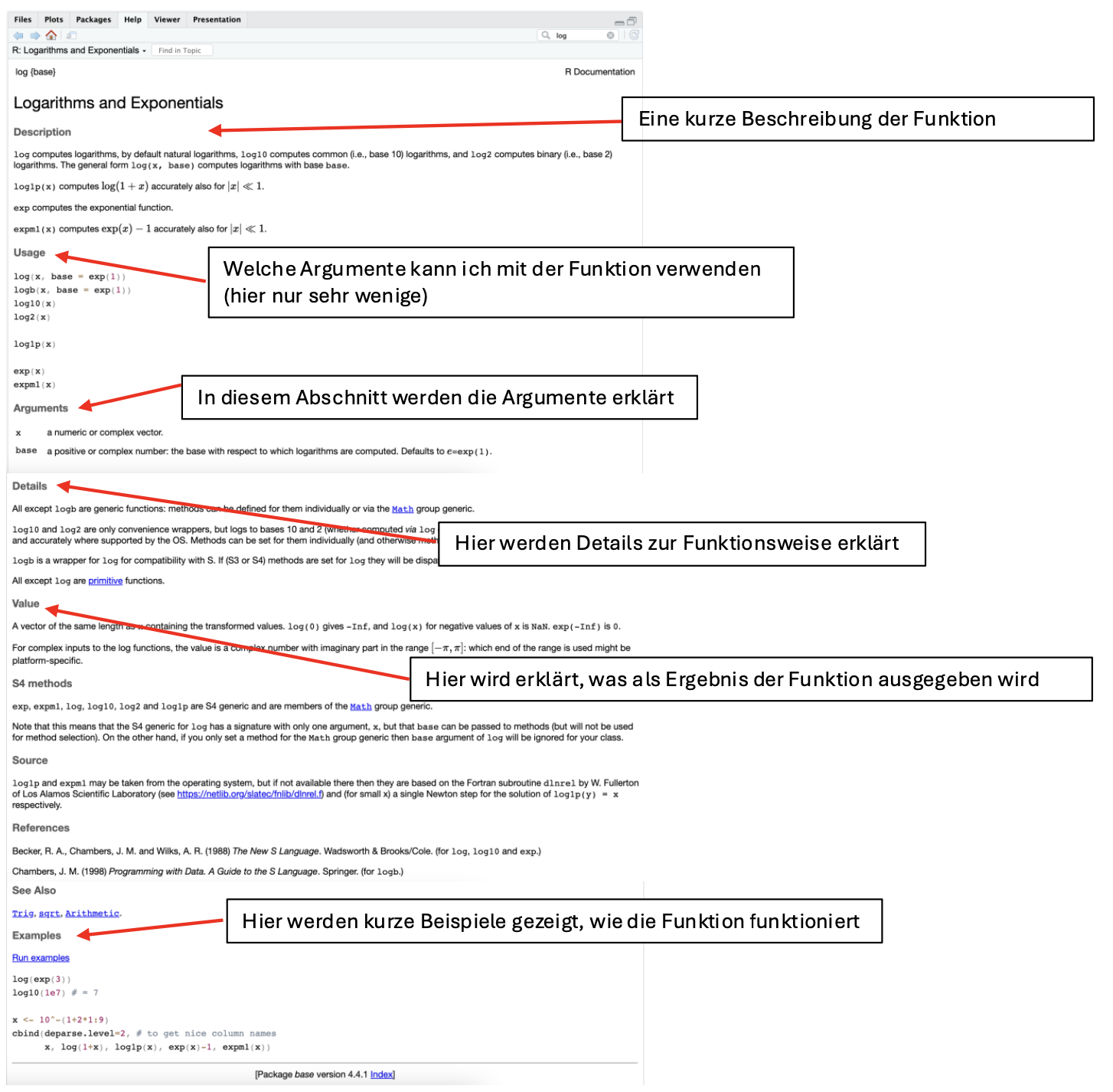
Noch schneller können wir die Hilfeseite öffnen, indem wir in der Console ein Fragezeichen vor den Namen der Funktion schreiben (z.B. ?log) und den Befehl ausführen.
In der Hilfeseite oben sehen wir zum Beispiel unter Description oder Usage, dass der Befehl log() per default den natürlichen Logarithmus berechnet (in der Statistik braucht man fast immer nur den), wir aber auch eine andere Basis mit dem Argument base einstellen könnten.
VorsichtProbieren Sie es aus
Finden Sie mit der Hilfefunktion heraus, warum die folgende Berechnung als Ergebnis 0 anzeigt:
round(0.5, digits = 0)[1] 0Lösung
In der Hilfeseite von ?round steht unter Details:
Note that for rounding off a 5, the IEC 60559 standard (see also ‘IEEE 754’) is expected to be used, ‘go to the even digit’. Therefore round(0.5) is 0 and round(-1.5) is -2.
Die Hilfe in R ist nur dann nützlich, wenn wir den Namen einer Funktion bereits kennen. Was aber machen wir, wenn wir den Namen einer Funktion nicht kennen (oder ihn gerade vergessen haben)? Oder anders ausgedrückt, wie finden wir in der Praxis heraus, welche Befehle oder Funktionen in R mir bei einer bestimmten Aufgabe weiterhelfen können?
Typischerweise geben wir eine möglichst präzise formulierte Frage in die Suchmaschine unserer Wahl ein.
Häufig finden wir bei einer solchen Suche heraus, dass eine für uns hilfreiche Funktion in einem bestimmten R Paket enthalten ist.
Pakete
Wenn wir R installieren ist eine ganze Menge an Funktionen schon in der Basisvariante verfügbar. Es ist jedoch möglich, den Funktionsumfang durch so genannte Pakete deutlich zu erweitern. Die meisten dieser Pakete werden kontinuierlich von einer großen Gruppe von Entwicklerinnen stetig gepflegt und erweitert und sind für jede R-Nutzerin kostenfrei verfügbar.
Häufig wurden Pakete von Wissenschaftlerinnen für einen bestimmten Zweck erstellt und enthalten dann eine Reihe von Befehlen, die aufeinander aufbauen und dabei helfen sollen, ein typisches Problem zu lösen.
Wollen wir Befehle aus einem Paket nutzen, müssen wir das Paket zunächst herunterladen (“installieren”). Das können wir entweder mit dem Befehl install.packages("PAKETNAME") machen, oder wir nutzen dazu in RStudio rechts unten den Reiter Packages.
Paket installieren
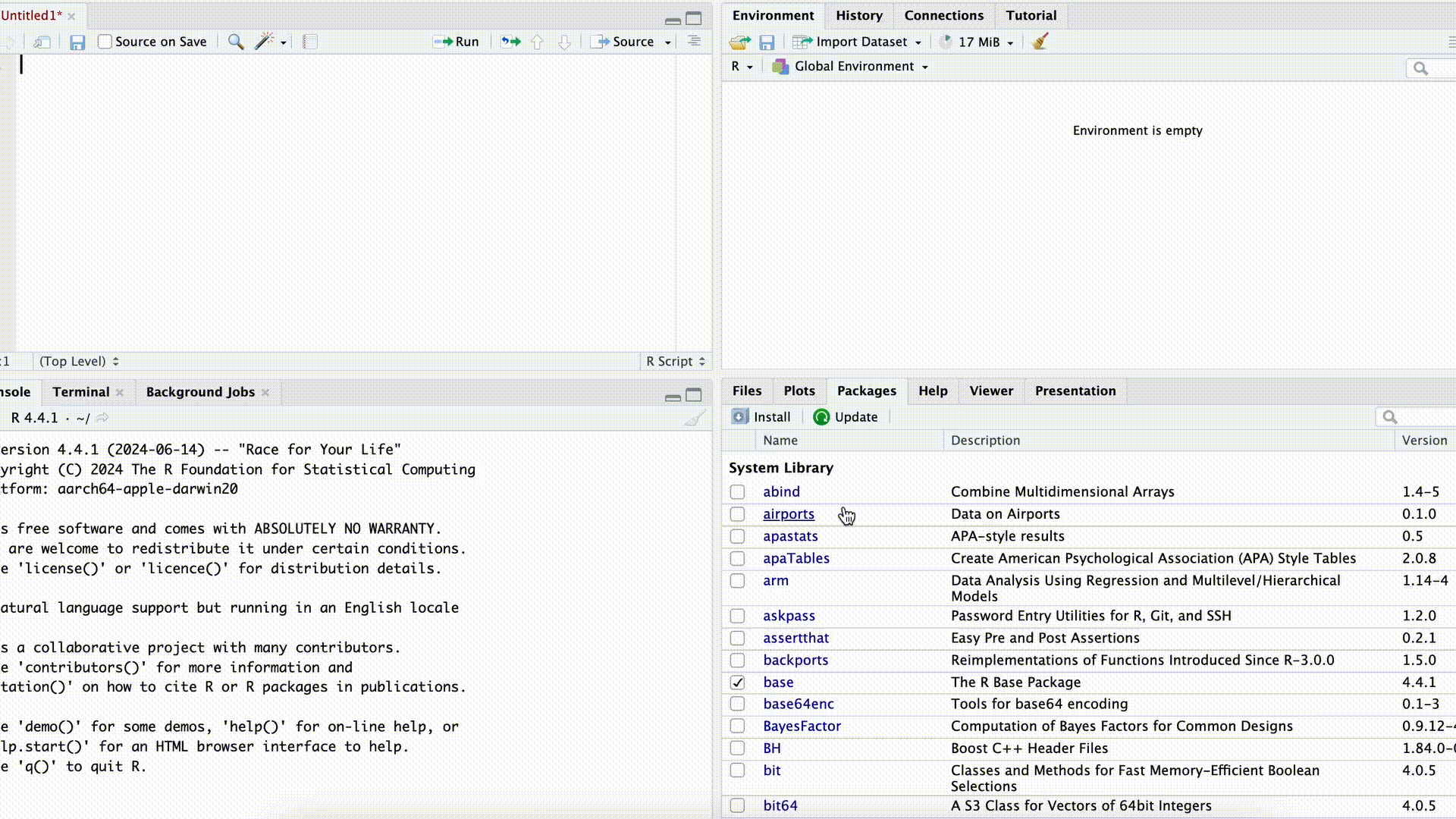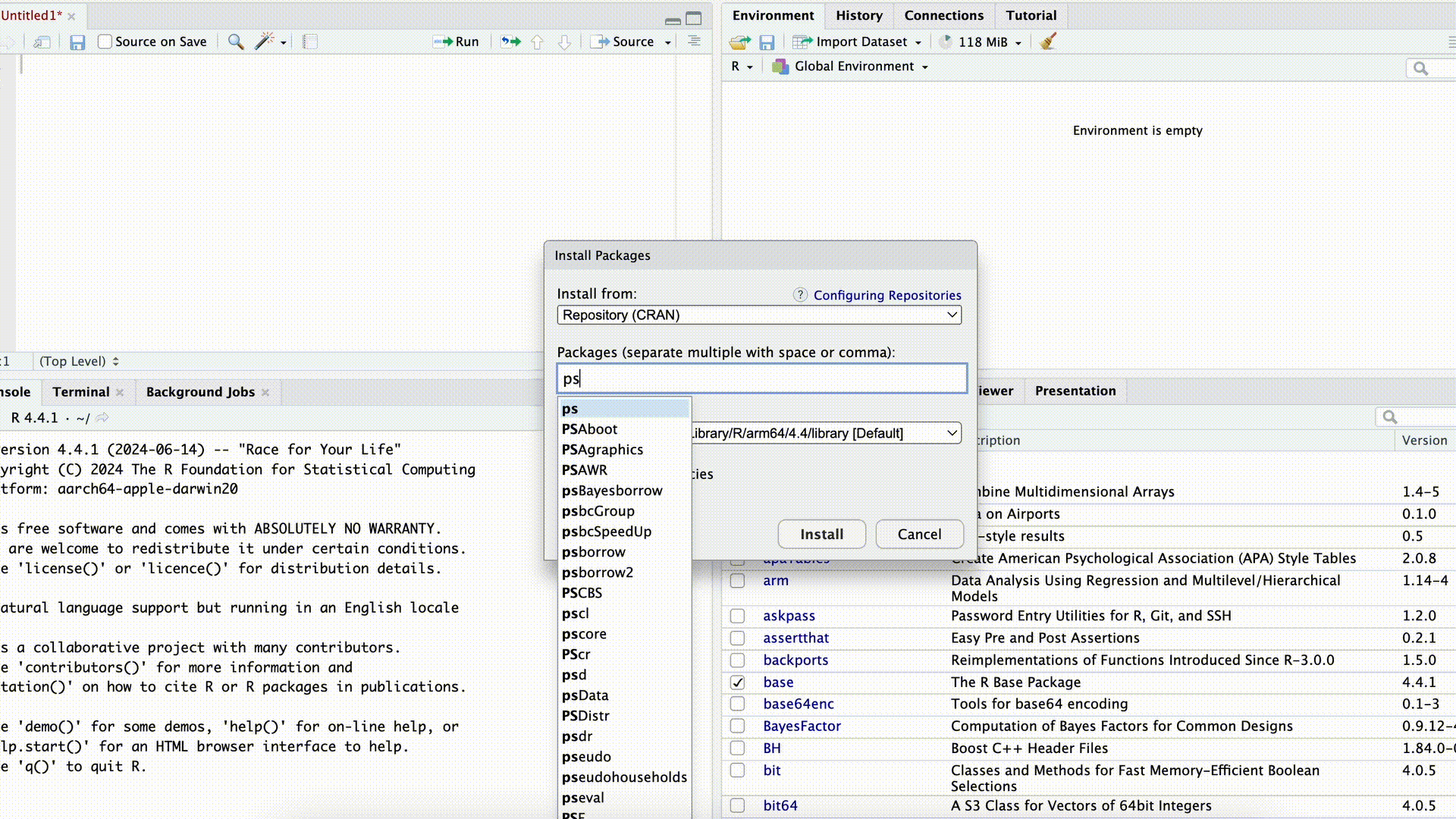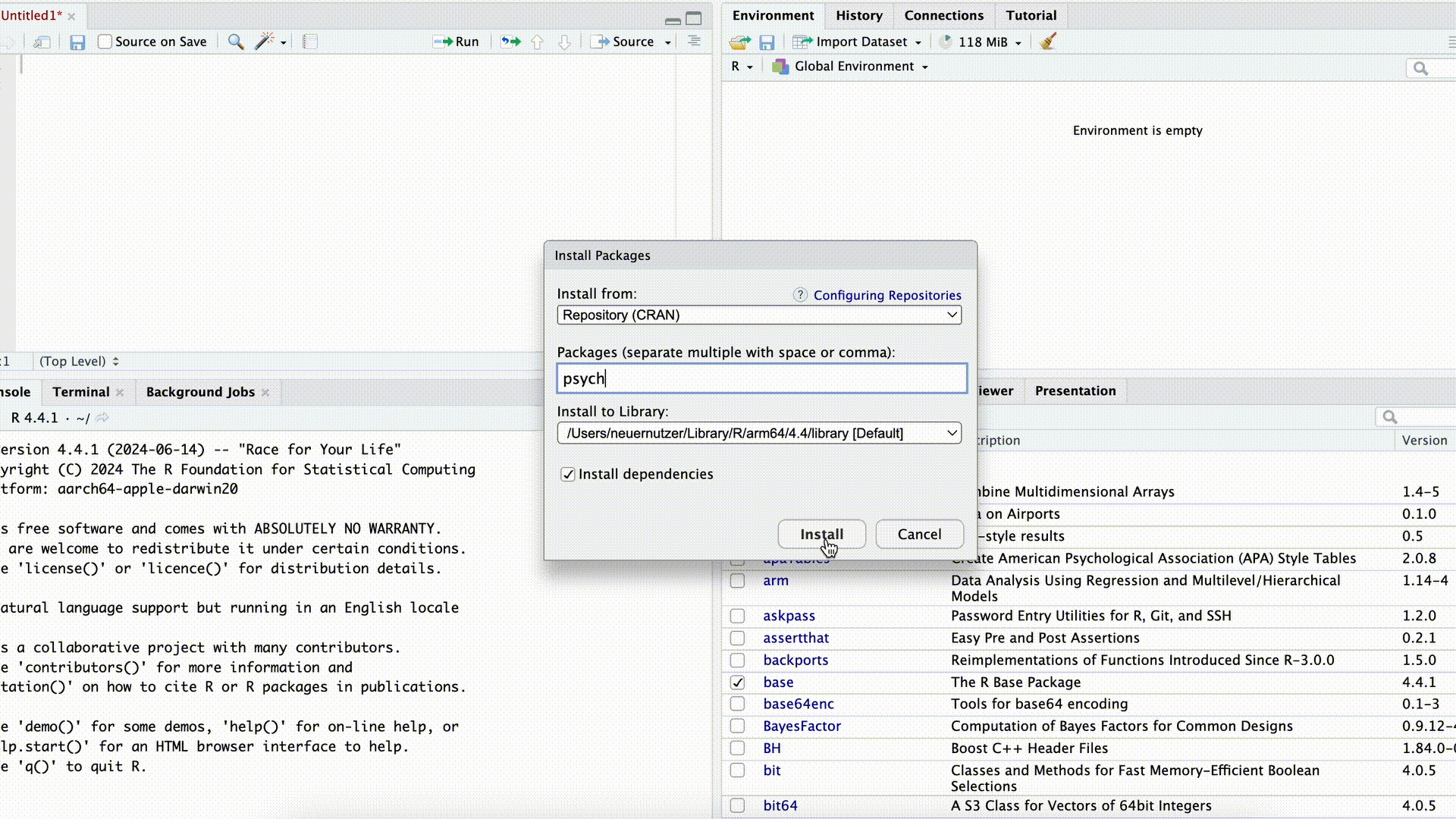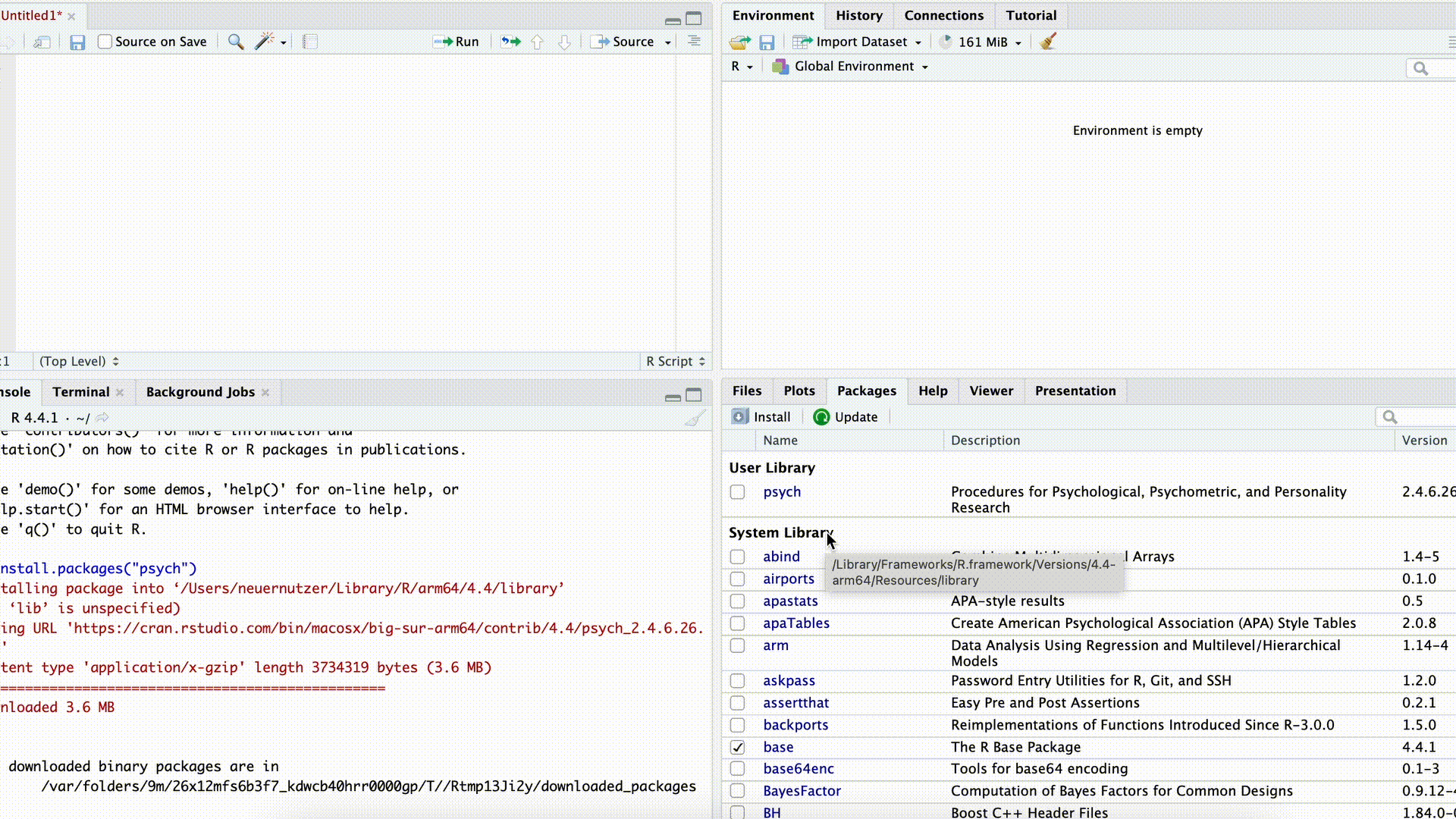
In beiden Fällen müssen wir genau wissen, wie das Paket heißt. Geben wir beispielsweise im Befehl install.packages("PAKETNAME") den Namen falsch an (oder vergessen die Anführungszeichen), schlägt der Befehl fehl:
install.packages("Psych") # das Paket heißt "psych" mit kleinem pWarning: package 'Psych' is not available for this version of R
A version of this package for your version of R might be available elsewhere,
see the ideas at
https://cran.r-project.org/doc/manuals/r-patched/R-admin.html#Installing-packagesWarning: Perhaps you meant 'psych' ?
WarnungVorsicht
Die Fehlermeldung…
Warning: package 'Psych' is not available for this version of R
…bedeutet hier nicht, dass unsere Version von R zu alt ist!
In diesem Fall haben wir uns nur verschrieben (R hat recht: Es gibt für unsere Version von R kein Paket namens ‘Psych’, aber es gäbe eines namens ‘psych’).
So wie wir Programme auf unserem Computer nur einmal installieren, müssen auch Pakete in der Regel nur einmal installiert werden, um sie danach immer wieder nutzen zu können. Lediglich nach einem Update von R (nicht von RStudio) ist es häufig notwendig, einmal installierte Pakete erneut zu installieren.
Wollen wir die Befehle des Pakets dann nutzen, müssen wir es für R zunächst mal verfügbar machen. Diesen Prozess nennt man das Paket zu laden. Am besten geht das mit dem Befehl…
library(PAKETNAME)…den wir häufig ganz oben in unser Skript schreiben, damit wir das Laden nicht vergessen.
Natürlich muss der Befehl nicht nur im Skript stehen, sondern auch ausgeführt werden!
HinweisHinweis
Ein Paket muss in der Regel nur einmal installiert, aber nach jedem Neustart von R oder RStudio erneut geladen werden, damit wir die Befehle darin nutzen können.
Ein Beispiel
Für unser Beispiel möchten wir die sogenannte logistische Funktion anwenden: \[
f(x) = \frac{1}{1 + e^{-x}}
\] Da wir im Internet gelesen haben, dass es z.B. im Paket psych den Befehl logistic() gibt, der diese Funktion berechnen kann, installieren und laden wir dieses Paket. Bevor wir das Paket installiert und auch geladen haben, können wir den Befehl daraus noch nicht nutzen:
logistic(0)Error in logistic(0): could not find function "logistic"Deshalb installieren wir das Paket einmalig wie oben beschrieben über den Reiter Packages oder mit dem folgenden Code:
# einmalig installieren:
install.packages("psych")Sofern die Installation geklappt hat können wir das Paket nun laden
# laden
library(psych)und den Befehl logistic() nutzen
logistic(0)[1] 0.5
VorsichtProbieren Sie es aus!
Sofern Sie die oben beschriebenen Schritte nicht ohnehin schon ausgeführt haben, versuchen Sie mal, die Funktion
logistic()zu verwenden, bevor Sie das Paketpsychinstalliert und geladen haben.Installieren Sie dann das Paket wie oben beschrieben.
Laden Sie das Paket wie oben beschrieben.
Führen Sie die folgenden Befehle aus:
logistic(0) logit(0.5) # das ist die UmkehrfunktionSchließen Sie RStudio und versuchen Sie, erneut die Befehle in Schritt 4 auszuführen.
Lösung
Ohne das Paket zu laden funktionert es nicht:
logistic(0)Error in logistic(0): could not find function "logistic"logit(0.5) # das ist die UmkehrfunktionError in logit(0.5): could not find function "logit"Erst wenn wir davor im Skript das Paket laden, klappt es wieder:
library(psych) logistic(0)[1] 0.5logit(0.5) # das ist die Umkehrfunktion[1] 0
WarnungVorsicht
Beim Installieren mit der Funktion install.packages("PAKETNAME") muss der Name des Pakets in Anführungszeichen stehen, beim Laden mit der Funktion library(PAKETNAME) nicht.
HinweisHinweis
Wenn wir ein Skript öffnen, in dem ein Paket geladen werden soll, das wir noch nicht installiert haben, weist uns RStudio darauf hin. Am oberen Rand des Skripts erscheint die Nachricht “Package PAKETNAME required but is not installed. Install Don’t Show Again”. Hier können wir nun auf Install klicken und das Paket direkt installieren.
TippFunktionen selbst schreiben
Sollten wir eine Funktion benötigen, die in R bisher nicht umgesetzt wurde und die auch in keinem Paket enthalten ist, ist es auch möglich, Funktionen selbst zu schreiben. Dadurch können wir einen bestimmten Code immer wieder ausführen, ohne den gesamten Code immer wieder zu schreiben (oder zu kopieren).
Auch Funktionen sind Objekte und können in Variablen gespeichert werden. Über diese Variablen rufen wir die Funktion dann auf. Eine Funktion ist wie folgt aufgebaut:
function_name <- function(<function parameters>) {
# Code
}Um eine Funktion aufzurufen, schreibt man () nach dem Funktionsnamen.
Jetzt können wir eine einfache Funktion schreiben, die oben beschriebene logistische Funktion ausführt, wenn man sie aufruft:
logistic_function <- function(zahl) {
1 / (1 + exp(-zahl))
}Dieser Code liefert uns noch keinen Output, da wir die Funktion zwar geschrieben, aber noch nicht aufgerufen haben. Die Ausführung des Befehls machen wir über den Namen der Funktion, hinter den wir mit () das Argument schreiben, mit dem die Funktion arbeiten soll (so wie bei den bisher bekannten Funktionen auch).
Beim Verfassen der Funktion haben wir in den () hinter function angegeben, dass die Funktion mit einem Objekt zahl arbeiten soll. In der nächsten Zeile innerhalb der {} haben wir dann mit diesem Objekt zahl die Operation vorgenommen (\(\frac{1}{1 + e^{-x}}\)), die unsere Funktion letztlich durchführen soll.
Ein kurzer Test zeigt, dass die Funktion das macht, was sie soll:
logistic_function(zahl = 0)[1] 0.5Die meisten Funktionen arbeiten mit mehreren Argumenten. Wir können uns also auch eine Funktion schreiben, die uns die Summe aus zwei Zahlen zurückgibt (Wir schreiben also die existierende Funktion sum() selber). Dabei verwenden wir als Argumente die beiden Platzhalter x und y, die wir dann beim späteren Funktionsaufruf durch die Zahlen ersetzen, die wir addieren möchten:
my_sum <- function(x, y) {
x + y
}
my_sum (x = 3, y = 5)[1] 8
VorsichtProbieren Sie es aus!
Schreiben Sie eine Funktion square(), die eine Zahl als Argument übernimmt und ihre Quadratzahl zurückgibt
Lösung
square <- function(x) { x * x } square(x = 3)[1] 9Schreiben Sie eine Funktion logit_function(), die die Umkehrfunktion der logistischen Funktion berechnet: \[ f(y) = ln(\frac{y}{1 - y}) \]
Lösung
logit_function <- function(zahl){ log(zahl / (1 - zahl)) } logit_function(zahl = 0.5)[1] 0
3.2 Datenstruktur
Einfache Datenstruktur: Vektoren
Bisher haben wir bei der Zuweisung eines Objekts immer nur einen einzelnen Wert gespeichert. Häufig wollen wir jedoch mit einer ganzen Reihe von Werten arbeiten. Um eine Reihe von Werten des gleichen Datentyps zu speichern, verwenden wir Vektoren. Der Begriff “Vektor” haben Sie vermutlich schon einmal im Matheunterricht gehört.
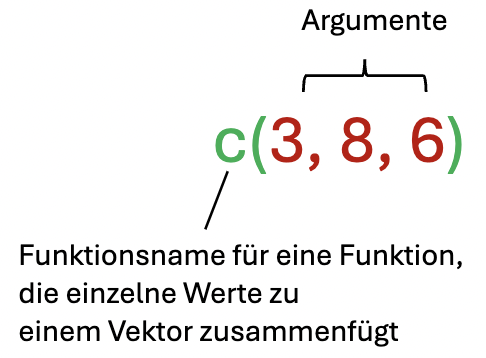
Wenn wir in R mehrere Komponenten (z.B. Zahlen) zu einem Vektor kombinieren wollen, verwenden wir die Funktion c(). Wie wir oben bei den Argumenten einer Funktion gelernt haben, werden die einzelnen Werte innerhalb der Funktion durch Kommas getrennt.
Wie wir es aus dem Matheunterricht kennen, können wir mit Vektoren auch rechnen. Wir können beispielsweise zwei Vektoren der gleichen Länge voneinander abziehen
\[ \vec{v} = \begin{pmatrix} 3 \\ 8 \\ 5 \end{pmatrix} - \begin{pmatrix} 1 \\ 5 \\ 2 \end{pmatrix} = \begin{pmatrix} 3 - 1 \\ 8 - 5\\ 5 - 2 \end{pmatrix} = \begin{pmatrix} 2 \\ 3 \\ 3 \end{pmatrix} \] oder von jedem Element eines Vektors eine bestimmte Zahl abziehen
\[ \vec{v} = \begin{pmatrix} 3 \\ 8 \\ 5 \end{pmatrix} - 2 = \begin{pmatrix} 3 - 2 \\ 8 - 2\\ 5 - 2 \end{pmatrix} = \begin{pmatrix} 1 \\ 6 \\ 3 \end{pmatrix} \]
In R müssen wir mit c() erstmal den gewünschten Vektor erstellen und können dann ganz normal damit rechnen:
c(3, 8, 5) - 2[1] 1 6 3Wie wir sehen, werden Vektoren in R immer als Zeilen dargestellt, das macht aber für unsere Anwendungen keinen Unterschied.
Bei längeren Vektoren kann es sinnvoll sein, den Vektor zunächst in einem Objekt zu speichern und danach die Operation mit dem Objekt auszuführen:
# Abspeichern eines Vektors in einem Objekt
mein_Vektor <- c(3, 8, 5)
mein_Vektor - 2[1] 1 6 3Beides führt zum selben Ergebnis - es ist also uns überlassen, welche Variante wir wählen.
Im Matheunterricht haben Sie vermutlich nur Vektoren mit Zahlen kennen gelernt, mit denen man dann auch rechnen kann. Die Struktur eines Vektors ist jedoch für uns an vielen Stellen nützlich. Ein Vektor ist – ganz allgemein formuliert – ein Objekt, das beliebig viele Elemente des gleichen Typs in fester Reihenfolge enthält. Wir werden im Folgenden noch sehen, dass es auch für andere Datentypen (logische Werte, character) viele Situationen gibt, in denen es sehr nützlich ist mehrere Elemente in einen Vektor zusammenzufassen.
Ein Vektor hat dabei aber immer genau einen Datentyp. Einen Vektor vom Typ logical können wir ganz ähnlich wie schon bei den Zahlen mit dem Befehl c() erstellen:
c(TRUE, FALSE, TRUE)[1] TRUE FALSE TRUE“Erkennungszeichen” für logische Werte ist hier, dass alle TRUE und FALSE-Werte richtig geschrieben (also alles groß und keine Schreibfehler) sind.
Die Erstellung eines Vektors vom Typ character funktioniert ganz genauso. Hier verwenden wir als “Erkennungszeichen” der character-Werte die "" vor und nach jedem Element:
c("Homer", "Marge", "Bart", "Lisa", "Maggie")[1] "Homer" "Marge" "Bart" "Lisa" "Maggie"
WarnungVorsicht
Verschiedene Datentypen können nicht gemischt werden. Geben wir verschiedene Datentypen in einen Vektor, so versucht R einen gemeinsamen Nenner zu finden, was üblicherweise den Typ character ergibt.
c(3, "wort", TRUE) [1] "3" "wort" "TRUE"Wenn wir diesen Code ausführen und damit den “gemischten” Vektor anzeigen, sehen wir, dass alle Elemente mit "" versehen und angegeben werden. Daran erkennen wir, dass auch die Zahl 3 und der logische Wert TRUE nun character-Werte sind und ihre eigentlichen Eigenschafen verloren haben.
Die Umwandlung von Datentypen erfolgt häufig ohne dass R eine Warnung ausgibt. Als Anwenderin können wir diesen Vorgang also leicht übersehen. Durch die Umwandlung in character gehen jedoch möglicherweise bestimmte Eigenschaften der Daten verloren. Wir können beispielsweise mit dem character-Wert "3" keine mathematischen Operationen wie Addition mehr vornehmen!
VorsichtProbieren Sie es aus!
Weisen Sie dem Vektor Geburtsjahr das Alter von drei (ausgedachten) Personen zu
Wie alt sind alle drei Personen 2023 geworden?
Weisen Sie dem Vektor Namen die Namen der Personen in (1) in gleicher Reihenfolge zu.
Lösung
Geburtsjahr <- c(1998, 2002, 1988) 2023 - Geburtsjahr[1] 25 21 35Namen <- c("Markus", "Philipp", "Moritz") Namen[1] "Markus" "Philipp" "Moritz"
Komplexere Datenstrukturen: Data Frames und Listen
data.frame
Bisher haben wir gesehen, dass wir Daten zu eindimensionalen Objekten zusammenfassen können, z.B. in Form von Vektoren. Wir können aber auch mehrdimensionale Strukturen erstellen, wie z.B. ein Objekt, das aus mehreren Vektoren besteht. Eine für uns besonders wichtigte Struktur heißt Data Frame (oder data.frame) und ähnelt einer Matrix (Matrizen gibt es in R auch, da wir diese aber so gut wie nie brauchen, werden wir sie nicht behandeln). Ein data.frame besteht aus Zeilen und Spalten. Die Spalten sind alle gleich lang, können aber Daten unterschiedlichen Typs beinhalten. Zum Beispiel eine Spalte Namen, die character-Werte beinhaltet und eine Spalte Alter, die Zahlen beinhaltet. Damit ist ein data.frame die für uns nützlichste und wichtigste Art von Datenstruktur. Hier können wir z.B. für mehrere Personen (Zeile entspricht einer Person) unterschiedliche Informationen (Name, Alter, Schulnote, Ausprägung psychischer Symptome etc.) in Spalten verschieden Typs zusammenfassen. Der data.frame sorgt dafür, dass die Zuordnung unterschiedlicher Informationen zu den Personen immer eindeutig ist. Der dritte Wert in der ersten Spalte (z.B. Name) gehört zur gleichen Person wie der dritte Wert in der dritten Spalte (z.B. Schulnote) usw.
Wir können nun selber mit dem Befehl data.frame() einen data.frame erstellen. Der Befehl hat für jede gewünschte Spalte im Datensatz ein Argument. Die Benennung der Argumente (z.B. Alter =) sorgt dafür, dass eine Spalte eine für uns inhaltlich sinnvolle Überschrift erhält:
df <- data.frame(
Name = c("Tom", "Paula", "Mia", "Jonas"),
Alter = c(21, 22, 21, 20) # Wichtig: Reihenfolge der Namen einhalten!
)
df # das Ausführen des Objekts zeigt den data.frame an Name Alter
1 Tom 21
2 Paula 22
3 Mia 21
4 Jonas 20Unserem data.frame können wir nun neue Variablen hinzufügen, indem wir das $-Symbol nutzen. Folgender Code fügt eine neue Spalte hinzu, die das Lieblingsessen unserer Personen beinhaltet. Dabei müssen wir darauf achten, dass der neue Vektor so viele Einträge enthält, wie wir Zeilen haben (in diesem Fall 4). Der erste Vektoreintrag beinhaltet den Wert der ersten Person, der zweite Eintrag den der zweiten Person usw.
df$Lieblingsessen <- c("Pizza", "Döner", "Eis", "Pizza")
df Name Alter Lieblingsessen
1 Tom 21 Pizza
2 Paula 22 Döner
3 Mia 21 Eis
4 Jonas 20 Pizza
HinweisDaten werden in der Praxis nicht direkt in R eingegeben!
Wir haben die Daten in df hier manuell eingetippt, um an einem einfachen Beispiel zeigen zu können, was ein data.frame ist. In der Praxis gibt niemand einen echten Datensatz direkt in R ein! Stattdessen werden Datensätze typischerweise entweder automatisiert erstellt (z.B. von einer Software für Onlineumfragen), oder manuell in einem Tabellenkalkulationsprogramm (z.B. Excel oder LibreOffice) eingegeben. Diese fertigen Datensätze (manchmal auch “Rohdaten” genannt) werden dann in R “eingelesen” und dort statistisch analysiert oder weiter verarbeitet. Das Einlesen von Datensätzen lernen wir später in Teil 2 des Tutorials.
list
Eine Liste (oder list) ist eine flexible Datenstruktur und kann Objekte unterschiedlichen Typs (z.B. Zahlen, Character) oder auch unterschiedlicher Struktur (z.B. Vektoren, data.frames) beinhalten. Einfache Benennungen der Listenelemente lassen sich wie beim data.frame auch gleich im list()-Befehl umsetzen.
my_list <- list(number = 1256, name = "Tomas", vector = c(1, 2, 5, 6))
my_list$number
[1] 1256
$name
[1] "Tomas"
$vector
[1] 1 2 5 6Ein wichtiger Unterschied zu data.frames ist, dass Listenelemente unterschiedlich “lang” sein können. Die Ergebnisse komplexerer Analysen sind häufig in Listen gespeichert, auf deren einzelne Elemente wir eventuell zugreifen wollen.
Indizierung: Zugriff auf Elemente eines Objekts
Indizierung von Vektoren
Bisher haben wir gesehen, wie wir bei der Vektorerstellung Daten zusammenfügen. Wir können aber auch auf einzelne Elemente des Vektors zugreifen (Fachbegriff: indizieren), falls uns z.B. nur der Eintrag interessiert, der an zweiter Stelle steht. Das erfolgt in R über die sogenannte Vektorindizierung. Dabei wird mit eckigen Klammern [] auf die Stelle zugegriffen, die uns interessiert. Dabei geben wir in den Klammern an, das wievielte Elemente des Vektors (also mit 1 das erste Element, mit 2 das zweite Element usw.) wir auswählen möchten.
# Beispielvektor erstellen
mein_Vektor <- c(3, 8, 5, 7)
# Zugriff auf die zweite Ziffer
mein_Vektor[2][1] 8
TippWie werden lange Vektoren im R-Output angezeigt?
Wenn wir uns von R einen langen Vektor anzeigen lassen, passt der Output nicht mehr in eine Zeile.
langer_Vektor <- 100:200 # 100:200 erzeugt alle ganze Zahlen von 100 bis 200
langer_Vektor [1] 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117
[19] 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135
[37] 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153
[55] 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171
[73] 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189
[91] 190 191 192 193 194 195 196 197 198 199 200Jetzt wo wir die [] Schreibweise kennengelernt haben, können wir zum ersten mal verstehen, was die Zahlen in eckigen Klammern (z.b. [1], [19], …) im Output bedeuten. Diese Zahlen zeigen an, das wievielte Element des Vektors zu Beginn einer Zeile des Outputs angezeigt wird. Das ist sehr hilfreich, um sich in langen Outputs schneller zurecht zu finden.
Bei unserem Beispiel langer_Vektor ist das 1. Element die Zahl 100 ([1] 100), das 19. Element die Zahl 118 ([19] 118) und so weiter. Wir können das mit der gerade gelernten Indizierung überprüfen:
langer_Vektor[19][1] 118Eine einzelne Zahl wird von R intern wie ein Vektor mit nur einem Element behandelt. Daher wird auch bei der Ausgabe einer einzelnen Zahl immer [1] angezeigt, obwohl das nicht besonders hilfreich ist…
Um auf mehrere Einträge eines Vektors zuzugreifen, erstellen wir in den eckigen Klammern [] einen Vektor und übergeben als Elemente des Vektors die Stellen der Einträge, die wir auswählen wollen.
mein_Vektor <- c(3, 8, 5, 7)
# Zugriff auf die zweite und vierte Ziffer
mein_Vektor[c(2, 4)][1] 8 7
WarnungVorsicht
Wenn wir auf mehrere Argumente des Vektors zugreifen wollen, dürfen wir den Vektor in der eckigen Klammer [c(x, y)] nicht vergessen. Es ist nicht möglich, innerhalb der eckigen Klammern ohne den Zwischenschritt des mit c() erstellten Vektors auf mehrere Argumente zuzugreifen: [2,3,4]. Später werden wir sehen, warum.
Wir können mit den eckigen Klammern nicht nur einzelne Werte anschauen sondern diese auch ändern. Der folgende Code weist unserem Vektor an zweiter Stelle den Wert 4 zu und überschreibt dabei den Wert 8.
mein_Vektor <- c(3, 8, 5, 7)
mein_Vektor[2] <- 4
mein_Vektor[1] 3 4 5 7Indizierung von Data Frames
Bei den Vektoren haben wir bereits gesehen, wie man mit eckigen Klammern [] auf einzelne Werte zugreift. Auch bei data.frames können wir auf einzelne Werte zugreifen. Dabei können wir eine einzelne Zeile auswählen, eine einzelne Spalte oder einen einzelnen Wert (= Kombination aus Spalte und Zeile). Natürlich können wir auch hier wieder mehrere Zeilen/Spalten/Werte auswählen.
Die eckigen Klammern bekommen dabei zwei Argumente, da wir zwei Dimensionen haben. Die Argumente werden (wie wir bereits bei den anderen Befehlen gesehen haben) durch ein Komma getrennt. Mit dem ersten Argument wählen wir die Zeile aus, mit dem zweiten Argument die Spalte:
df[Zeile, Spalte]
HinweisHinweis
Eine Eselsbrücke um sich zu merken, dass das erste Argument die Zeilen auswählt und das zweite Argument die Spalten:
Zeilen Zuerst, Spalten Später
Zur Erinnerung: Wir haben in Abschnitt 3.2.2.1 bereits folgenden data.frame erstellt:
df Name Alter Lieblingsessen
1 Tom 21 Pizza
2 Paula 22 Döner
3 Mia 21 Eis
4 Jonas 20 PizzaHier können wir nun z.B. alle Spalten der ersten Person (also die erste Zeile) auswählen, indem wir in eckigen Klammern als erstes Argument die Zeile 1 übergeben und das zweite Argument hinter dem Komma leer lassen. Das Leerlassen bedeutet, dass alle Spalten ausgewählt werden:
df[1, ] Name Alter Lieblingsessen
1 Tom 21 PizzaOder wir interessieren uns nur für das Alter aller Personen und wählen die zweite Spalte aus. Dabei lassen wir das erste Argument frei (wir wollen alle Zeilen auswählen) und übergeben als zweites Argument die Spalte 2:
df[ , 2][1] 21 22 21 20Wenn wir uns speziell für das Alter der ersten Person in unserem data.frame interessieren, können wir diesen einzelnen Wert auswählen, indem wir als erstes Argument die Zeile 1 übergeben und als zweites Argument die Spalte 2:
df[1, 2][1] 21Ähnlich wie bei Vektoren können wir auch hier mehrere Zeilen oder Spalten auswählen, indem wir diese in einem Vektor zusammenfassen:
df[c(1, 2), c(1, 2)] Name Alter
1 Tom 21
2 Paula 22Vor dem Komma und nach dem Komma [ , ] darf jeweils nur eine Information stehen. Wir müssen also alle Infos bezüglich der Zeilen und der Spalten jeweils in ein Objekt (hier einen Vektor) zusammenfassen.
Für den Fall, dass wir zwar den Namen der Spalten kennen, aber nicht wissen, an welcher Stelle sich diese befinden, können wir auch über den Namen der Spalte auf diese zugreifen:
df[ , c("Alter", "Lieblingsessen")] Alter Lieblingsessen
1 21 Pizza
2 22 Döner
3 21 Eis
4 20 Pizza
HinweisHinweis
Wenn wir uns zurückerinnern, haben wir gesehen, dass es nicht möglich ist auf die Weise mein_Vektor[1, 2, 3] auf die ersten drei Einträge eines Vektors zuzugreifen. Nachdem wir uns nun die Indizierung von data.frames angeschaut haben, verstehen wir, dass sich die Argumente in eckigen Klammern auf die Dimensionen beziehen.
Indizierung von Data Frames und Listen mit $
Neben der Indizierung über eckige Klammern [ , ] können wir auch die Spaltennamen nutzen, um ganze Spalten herauszugreifen. Hierfür nutzen wir das Dollar-Zeichen $:
df$Name[1] "Tom" "Paula" "Mia" "Jonas"Sobald wir das $ Zeichen eingeben, schlägt uns die Autovervollständigung von RStudio alle Spaltennamen des Datensatzes zur Auswahl vor.
Autovervollständigung
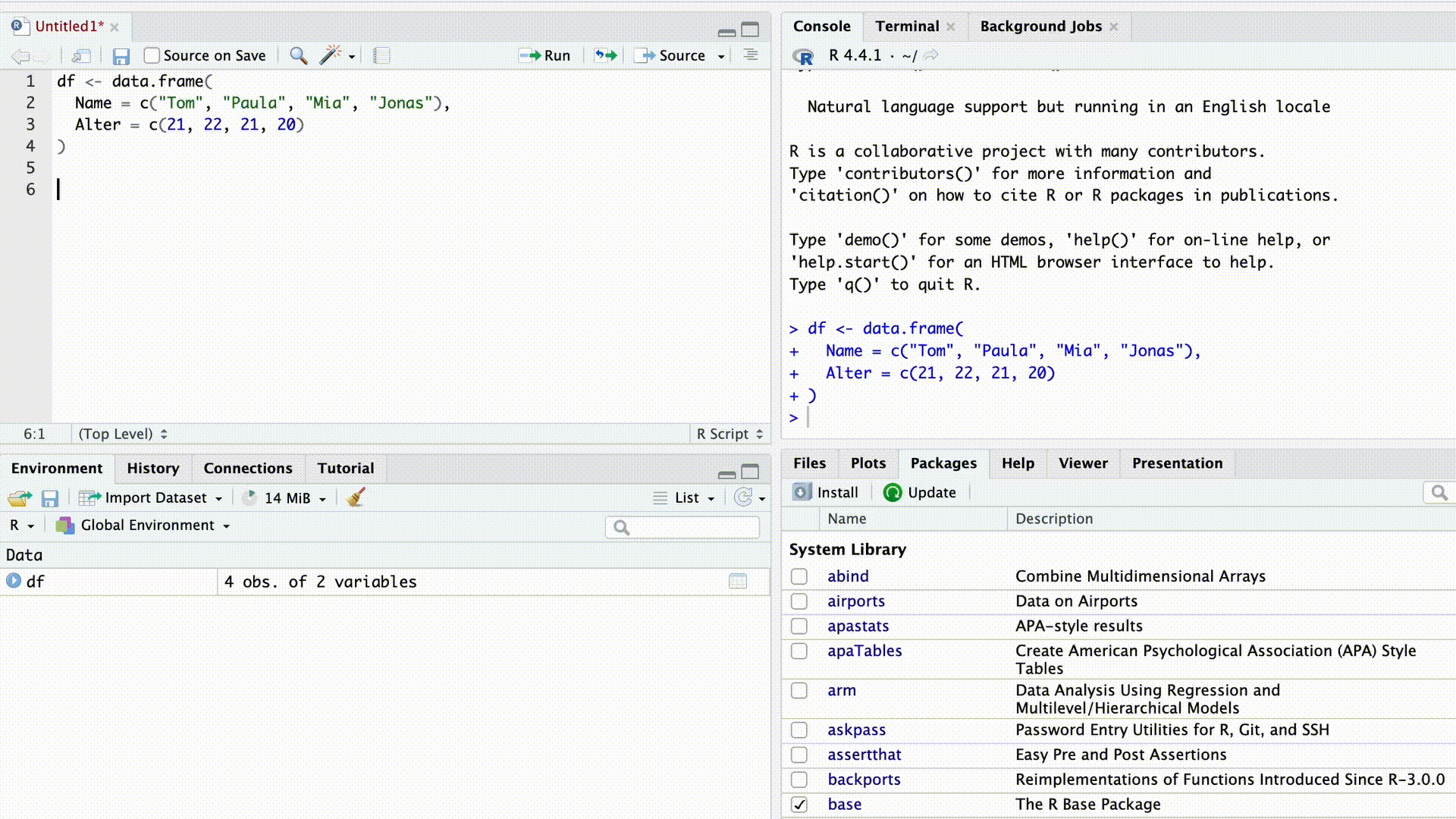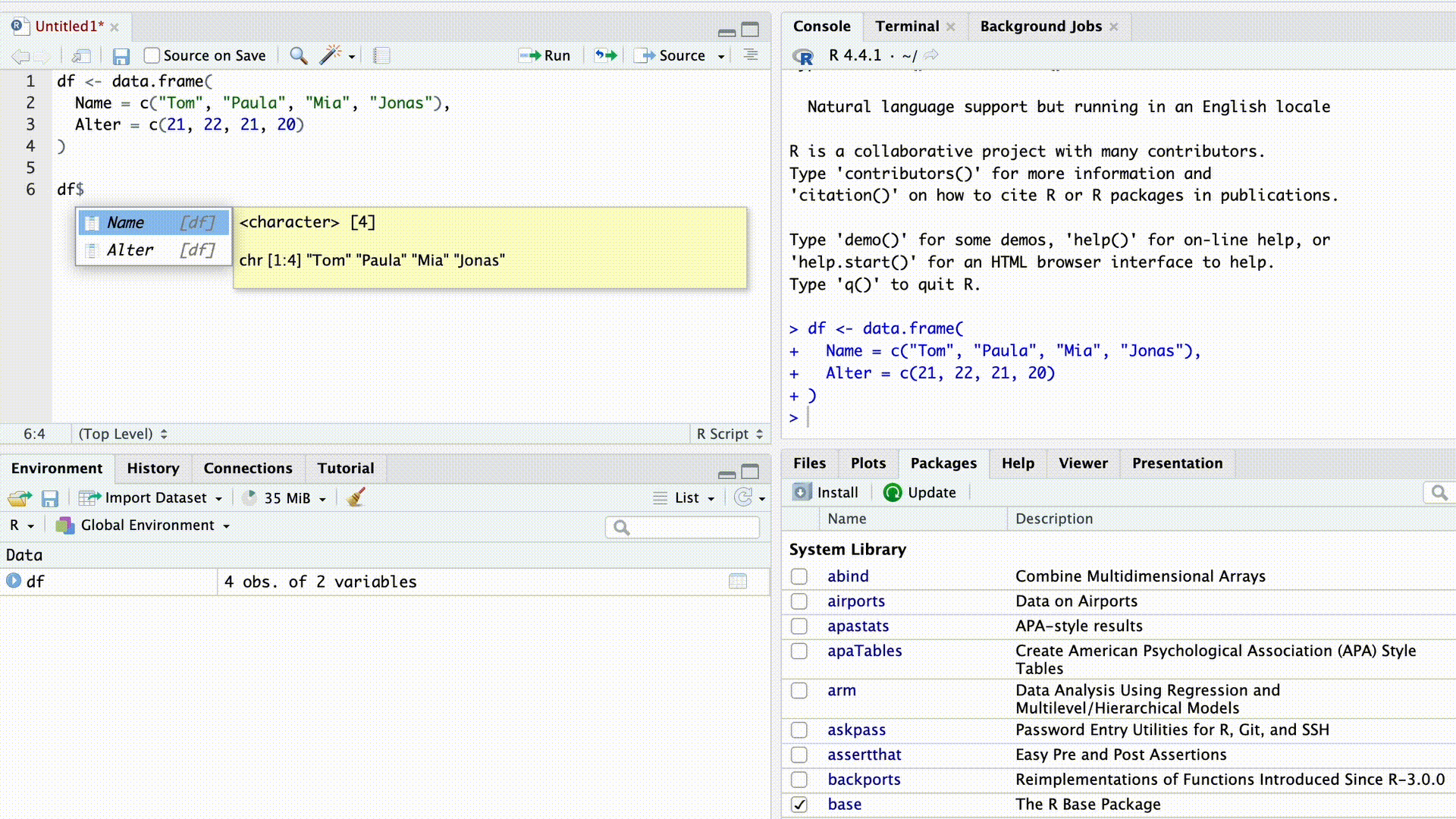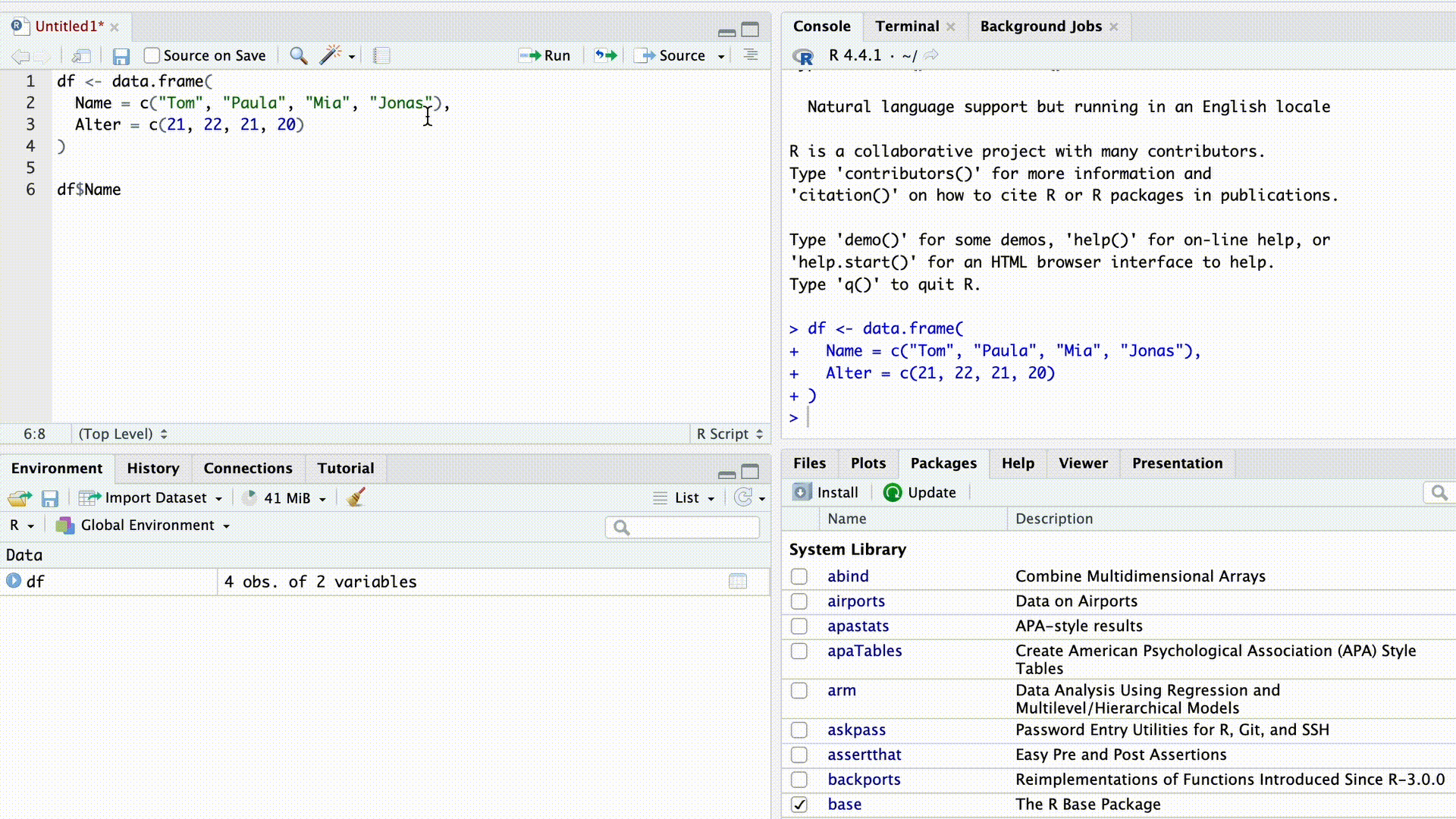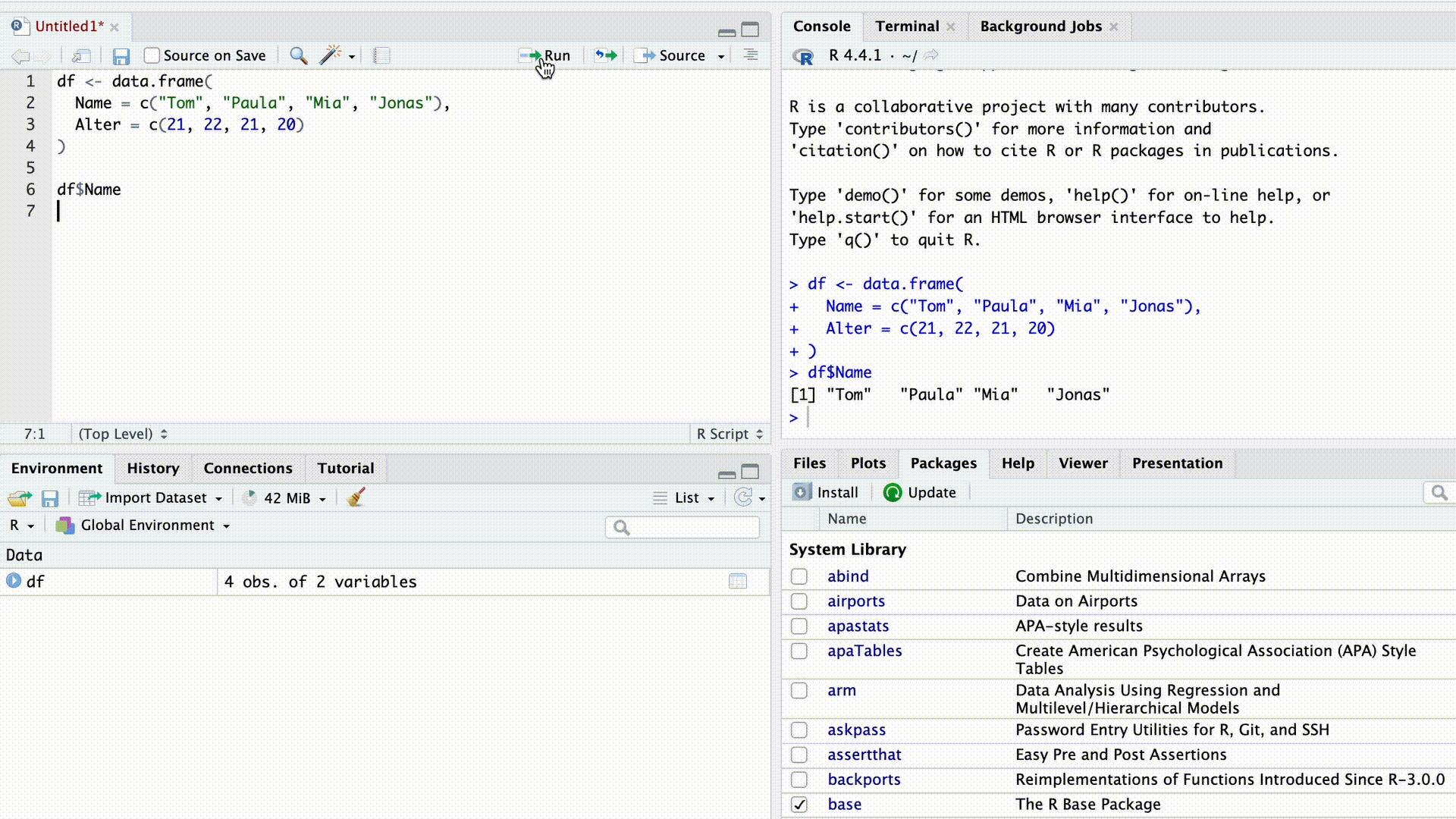
Die $-Indizierung funktioniert auch mit Listen. Zum Beispiel können wir aus unserer weiter oben erstellten Liste…
my_list$number
[1] 1256
$name
[1] "Tomas"
$vector
[1] 1 2 5 6… das Element mit dem Namen vector folgendermaßen herausgreifen:
my_list$vector[1] 1 2 5 6Bedingte Indizierung von Data Frames
Bisher haben wir uns vor allem angeschaut, wie wir bestimmte Spalten auswählen. Nun wollen wir uns ansehen, wie wir Personen aus unserem data.frame auswählen, die bestimmte Bedingungen erfüllen.
Im folgenden Beispiel wollen wir alle Personen aus unserem data.frame auswählen, deren Lieblingsessen Pizza ist. Bei einem großen Datensatz währe es sehr aufwendig, herauszufinden an welchen Stellen diese Personen stehen und die entsprechenden Stellen in einen Vektor zu schreiben.
Wir können die Stellen der Personen mit Pizza als Lieblingsessen über einen logischen Vergleich ermitteln:
df$Lieblingsessen == "Pizza"[1] TRUE FALSE FALSE TRUEDabei fragen wir für jede Zeile ab, ob im data.frame df die Spalte Lieblingsessen den Eintrag “Pizza” enthält. Der Rückgabewert eines logischen Vergleich ist wie in Abschnitt 1.3 beschrieben TRUE oder FALSE. Wir erhalten also für jede Zeile des data.frame die Information, ob die dort angegebene Person als Lieblingsessen “Pizza” angegeben hat. Die Zeilen, für die ein TRUE als Antwort kommt, möchten wir auswählen, alle mit der Information FALSE nicht.
Die nun gewonnene Information, an welcher Stelle TRUE steht können wir nun direkt nutzen und in unsere Indizierung einbauen. Wir fügen dafür den Code der den logischen Vergleich vornimmt direkt in den Code ein, der für die Auswahl bestimmter Zeilen zuständig ist. Also innerhalb der Auswahl df[ , ] vor dem Komma:
df[df$Lieblingsessen == "Pizza", ] Name Alter Lieblingsessen
1 Tom 21 Pizza
4 Jonas 20 Pizza
VorsichtProbieren Sie es aus!
Durch welchen Code erhalte ich die Daten der Spalte Lieblingsessen nur bei den 21-Jährigen?
Lösung
df[df$Alter == 21, "Lieblingsessen"][1] "Pizza" "Eis"
TippIndizierung mit logischem UND bzw. logischem ODER
Die bedingte Indizierung wird noch nützlicher, wenn wir berücksichtigen, dass wir mehrere logische Vergleiche mit dem logischen UND (in R das Symbol &) bzw. logischen ODER (in R das Symbol |) kombinieren können.
Hier nochmal unser Beispiel data.frame zur Erinnerung:
df Name Alter Lieblingsessen
1 Tom 21 Pizza
2 Paula 22 Döner
3 Mia 21 Eis
4 Jonas 20 PizzaBeispiel 1:
Zeige die Namen aller Personen an, deren Alter größer als 20 UND gleichzeitig kleiner als 22 ist.
df[df$Alter > 20 & df$Alter < 22, "Name"][1] "Tom" "Mia"Beispiel 2:
Zeige die Namen aller Personen an, deren Lieblingsessen Pizza ODER deren Alter 21 Jahre ist (oder beides).
df[df$Lieblingsessen == "Pizza" | df$Alter == 21, "Name"][1] "Tom" "Mia" "Jonas"3.3 Praktische Funktionen für Data Frames
Wir haben bereits gesehen, was Funktionen und Argumente sind. Dabei haben wir mathematischen Funktionen wie exp() kennengelernt, sowie die Funktion round() oder die Funktion c() zur Erstellung von Vektoren.
In unserer praktischen Arbeit werden wir fast immer mit Daten arbeiten, die in R als data.frame vorliegen. Da data.frames uns also sehr häufig begegnen, wollen wir dazu einige praktische Funktionen kennenlernen. Später sind unsere Datensätze oft sehr umfangreich mit hunderten Zeilen und Spalten, so dass wir nicht mehr einfach so “per Hand” feststellen können, was in einem data.frame enthalten ist oder ob es irgendwelche Auffälligkeiten gibt. Deshalb gibt es einige Funktionen, die wir direkt mit einem data.frame als Argument anwenden können, um allgemeine Informationen darüber zu erhalten.
str()beschreibt die Struktur eines Objekts, also z.B. welchen Datentyp es hat und wie viele Elemente darin enthalten sind. Diese Funktion ist bei der Arbeit mit allen Objekten extrem nützlich (nicht nur bei data.frames)nrow()gibt uns die Anzahl an Zeilen in einem data.frame aus undncol()die Anzahl an Spaltenhead()zeigt die ersten sechs Zeilen eines data.frames an (natürlich nur sinnvoll, wenn es mehr als sechs Zeilen gibt) undtail()die letzten sechs Zeilensummaryfasst die Information die ein Objekt enthält zusammen (nicht nur bei data.frames).
Bei data.frames versucht der Befehl die einzelnen Spalten auf sinnvolle Weise zu beschreiben.
WarnungBefehle und Funktionen nicht krampfhaft auswendig lernen!
Am Anfang bekommt man eventuell den Eindruck, “R lernen” bedeute ganz viele Befehle und Funktionsnamen auswendig zu lernen. So sieht programmieren in der Praxis aber nicht aus. Tatsächlich ist es das Wichtigste, die Funktionsweise von R zu lernen (z.B. was sind data.frames und wie funktioniert die [ , ] Syntax). Auch erfahrene R-Nutzerinnen kennen nicht die Namen aller verfügbaren Funktionen und es ist ganz normal, beim programmieren immer wieder die notwendigen Informationen nachzuschlagen (wie man das effizient macht, siehe z.B. Abschnitt 3.1.2). Befehle und Funktionen, die man häufig benötigt, prägen sich dann mit der Zeit ganz automatisch ein.
In den folgenden Beispielen wenden wir die oben aufgelisteten Funktionen auf den vorhin erstellten data.frame df an, um uns allgemeine Informationen über dessen Struktur ausgeben zu lassen:
str(df)'data.frame': 4 obs. of 3 variables:
$ Name : chr "Tom" "Paula" "Mia" "Jonas"
$ Alter : num 21 22 21 20
$ Lieblingsessen: chr "Pizza" "Döner" "Eis" "Pizza"Wir sehen im Output von str(), dass unser data.frame 4 Zeilen (obs. steht für observations) und 3 Spalten (variables). Die erste Spalte heißt Name und besteht aus character-Werten (chr). Die zweite Spalte heißt Alter und besteht aus Zahlen (num für numeric). Die dritte Spalte heißt Lieblingsessen und besteht wieder aus character-Werten.
nrow(df)[1] 4ncol(df)[1] 3Wenn wir einen größeren Datensatz haben als unser Beispiel und nur die ersten oder letzten sechs Zeilen ansehen wollen, können wir das mit head() oder tail(). Da df in unserem Beispiel nur vier Zeilen hat, ist das in diesem Fall sinnfrei.
head(df) Name Alter Lieblingsessen
1 Tom 21 Pizza
2 Paula 22 Döner
3 Mia 21 Eis
4 Jonas 20 Pizzatail(df) Name Alter Lieblingsessen
1 Tom 21 Pizza
2 Paula 22 Döner
3 Mia 21 Eis
4 Jonas 20 PizzaEine Zusammenfassung für jede Spalte im Datensatz bekommen wir mit dem Befehl summary(). Dieser Befehl kann auch auf andere Objekte als data.frames angewandt werden und wird uns in Statistik noch häufig begegnen.
summary(df) Name Alter Lieblingsessen
Length:4 Min. :20.00 Length:4
Class :character 1st Qu.:20.75 Class :character
Mode :character Median :21.00 Mode :character
Mean :21.00
3rd Qu.:21.25
Max. :22.00 Je nachdem, welchen Datentyp eine Spalte hat, sieht die Zusammenfassung unterschiedlich aus. Für numerische Spalten wie Alter bekommen wir eine Reihe von Lagemaßen wie z.B. den Mittelwert (Mean). Für Textspalten wie Name und Lieblingsessen ist die Zusammenfassung erst einmal nicht besonders hilfreich, da summary() mit character-Werten nicht so gut umgehen kann. Sinnvoller wäre es, wenn die beiden Spalten als factor gespeichert wäre.
3.4 Datentypen Teil 2
Faktoren
Wir haben oben in Abschnitt 1.4 die drei Datentypen numeric, logical und character kennen gelernt. Der Typ logical mit den TRUE und FALSE-Werten ist dann für uns ganz praktisch, wenn Daten nur zwei Ausprägungen annehmen können (z.B. “ist das Alter einer Person > 18 oder nicht?” oder “hat eine Person eine bestimmte Erkrankung oder nicht?”). Sind mehr als zwei Ausprägungen möglich, benötigen wir eine andere Lösung: Den Datentyp factor.
Ein Faktor kann eine festgelegte Anzahl von Ausprägungen (Levels) haben, die die möglichen Datenkategorien darstellen. Dabei kann es auch vorkommen, dass eine Ausprägung des Faktors zwar definiert wird, in unserem Datensatz tatsächlich jedoch gar nicht vorkommt.
Ein Beispiel
Angenommen wir haben eine Umfrage durchgeführt, in der Teilnehmer gefragt wurden, welchen Psychologie-Studiengang sie studieren. Wir wissen, dass es an der LMU nur eine begrenze Auswahl an Psychologie-Studiengängen gibt (z.B. “Bachelor Hauptfach”, “Bachelor Nebenfach”, “Master”) ohne dass alle diese Ausprägungen auch tatsächlich in unserer Umfrage als Daten auftauchen.
Nehmen wir an, von unseren drei befragten Personen studieren zwei im Bachelor Hauptfach und eine Person im Master:
studienfach <- factor(c("Bachelor Hauptfach", "Bachelor Hauptfach", "Master"), # Vorsicht, das c() nicht vergessen!
levels = c("Bachelor Hauptfach", "Bachelor Nebenfach", "Master"))
studienfach[1] Bachelor Hauptfach Bachelor Hauptfach Master
Levels: Bachelor Hauptfach Bachelor Nebenfach MasterDas erstellte Objekt studienfach ist durch den Befehl factor() nun vom Typ factor. Als erstes Argument dieses Befehls haben wir die Antworten unserer drei Personen als Vektor vom Typ character angegeben. Als zweites Argument levels = haben wir angegeben, welche Ausprägungen es theoretisch geben kann.
Welchen Nutzen hat es nun, Ausprägungen anzugeben, obwohl sie nicht beobachtet wurden? Dadurch, dass die Ausprägung “Bachelor Nebenfach” zwar als level angegeben wurde, jedoch in den Daten gar nicht auftaucht “weiß” R nun, dass es eine Ausprägung gibt, die nicht in den Daten beobachtet wurde. Bei einem Befehl wie dem Erstellen einer Häufigkeitstabelle wird R uns nun die Information geben, dass die erste Ausprägung “Bachelor Hauptfach” zwei Mal, die dritte Ausprägung “Master” ein Mal, und die zweite Ausprägung “Bachelor Nebenfach” überhaupt nicht beobachtet wurde:
table(studienfach) # So kann eine einfache Häufigkeitstabelle angezeigt werdenstudienfach
Bachelor Hauptfach Bachelor Nebenfach Master
2 0 1 Wenn wir später statistische Analysen mit Daten durchführen wollen, die in Form von Text vorliegen, müssen wir manchmal überlegen, ob der Datentyp character ausreichend ist, oder ob wir die Textdaten als factor speichern müssen.
TippManche R Funktionen erwarten factor statt character
Später wird es für einige Funktionen in R notwendig sein, dass Spalten in unseren data.frames die Textinformation enthalten als Faktor gespeichert sind. Wir wollen dies hier schon einmal an einem kleinen Beispiel demonstrieren:
Mit der häufig verwendeten Funktion summary() kann für viele verschiedene Arten von Objekten hilfreiche Zusammenfassungen anzeigen. Wenn wir jedoch die Funktion auf unseren zuvor erstellten data.frame df anwenden, haben wir oben gesehen, dass die Zusammenfassung der beiden character-Spalten Name und Lieblingsessen für uns nicht besonders nützlich ist…
summary(df) Name Alter Lieblingsessen
Length:4 Min. :20.00 Length:4
Class :character 1st Qu.:20.75 Class :character
Mode :character Median :21.00 Mode :character
Mean :21.00
3rd Qu.:21.25
Max. :22.00 Nützlicher wird die Zusammenfassung, wenn wir die beiden Spalten mit dem factor() Befehl in einen Faktor umwandeln und neu abspeichern:
df$Name <- factor(df$Name)
df$Lieblingsessen <- factor(df$Lieblingsessen)
summary(df) Name Alter Lieblingsessen
Jonas:1 Min. :20.00 Döner:1
Mia :1 1st Qu.:20.75 Eis :1
Paula:1 Median :21.00 Pizza:2
Tom :1 Mean :21.00
3rd Qu.:21.25
Max. :22.00 Wie wir sehen, zeigt der summary() Befehl für Faktorspalten in einem data.frame eine nützliche Häufigkeitstabelle an.
Fehlende Werte
Bisher sind wir in unseren Beispielen immer davon ausgegangen, dass uns alle Personen die wir in einer Datenerhebung befragen, auch vollständige Antworten geben. Im Beispiel oben haben wir von allen drei befragten Personen beispielsweise auch eine Antwort bekommen, in welchen Studiengang sie eingeschrieben sind. In Abschnitt 3.2.2.1 haben alle vier Personen in unserem Beispiel ihren Namen, ihr Alter und ihr Lieblingsgericht verraten. Das ist jedoch häufig nicht realistisch, denn Befragte geben oft nur unvollständige Antworten.
Ein Beispiel
Nehmen wir an, dass wir für die Erstellung unseres data.frames df oben zwar von Tom, Paula und Mia ihr Alter erfahren haben, Jonas uns jedoch sein Alter nicht verraten möchte? Wir können Jonas Alter ja nicht einfach weglassen, da sonst nur noch drei Werte vorhanden sind, die dann auch möglicherweise in den Zeilen den falschen Personen zugeordet werden. Wir müssten also bei der Erstellung des data.frames irgendwie die Information geben, dass hier eine Zahl stehen sollte, diese jedoch unbekannt ist.
Das geht mit einem so genannten Fehlenden Wert, der in R durch die Buchstabenkombination NA gekennzeichnet ist. Ein solches NA könnten wir jetzt an der Stelle von Jonas in unserer Spalte Alter einfügen:
df <- data.frame(
Name = c("Tom", "Paula", "Mia", "Jonas"),
Alter = c(21, 20, 21, NA) # Wichtig: Reihenfolge der Namen einhalten!
)
df # das Ausführen des Objekts zeigt den data.frame an Name Alter
1 Tom 21
2 Paula 20
3 Mia 21
4 Jonas NA
WarnungVorsicht
Sind NAs in Daten vorhanden, kann es vorkommen, dass Befehle nicht mehr so funktionieren, wie von uns erwartet. Oft gibt es aber bestimmte Argumente, die dem Befehl sagen wie er mit NAs umgehen soll.
Ein Beispiel
Mit dem Befehl sum() könnten wir mehrere Werte addieren. Übergeben wir die Spalte Alter df$Alter diesem Befehl, würde der Befehl versuchen, alle Werte dieser Spalte zu addieren:
sum(df$Alter)[1] NAAls Ergebnis kommt nun auch ein NA heraus?! Das liegt daran, dass der Befehl nicht weiß wie eine Summe von drei Zahlen und einer unbekannten Zahl gebildet werden soll.
Möchten wir jedoch, dass der Befehl den NA einfach ignoriert und die drei verbleibenden Werte addiert, können wir dies mit dem Argument na.rm = TRUE erreichen:
sum(df$Alter, na.rm = TRUE)[1] 62Wie das Argument heißt, dass bei einem Befehl den Umgang mit fehlenden Werten definiert, können Sie in der Hilfeseite zum jeweiligen Befehl (z.B. hier ?sum, siehe Abschnitt 3.1.2) herausfinden.
TippAlle Zeilen mit fehlenden Werten entfernen
Manchmal möchte man in einem Datensatz alle Zeilen entfernen, die nicht vollständig sind (d.h. mindestens einen mit NA kodierten fehlenden Wert enthalten). Dafür kann die Funktion na.omit() verwendet werden. Wenn die Funktion einen data.frame als Input bekommt, gibt sie einen data.frame aus, der nur noch die vollständigen Zeilen enthält, z.B.:
df_ohneNA <- na.omit(df)
df_ohneNA Name Alter
1 Tom 21
2 Paula 20
3 Mia 21df Name Alter
1 Tom 21
2 Paula 20
3 Mia 21
4 Jonas NAVorsicht: In der Praxis müssen Sie sich immer genau überlegen, ob es wirklich sinvoll ist, die Zeilen mit fehlenden Werten für alle Analysen pauschal zu entfernen! Der richtige Umgang mit fehlenden Werten ist in der Statistik ein kompliziertes Problem, auf das wir hier nicht im Detail eingehen können.
4 Häufige Flüchtigkeitsfehler
Im Folgenden möchten wir die häufigsten Flüchtigkeitsfehler auflisten, die uns allen bei der Arbeit mit R ständig passieren (das ist ganz normal!). Versuchen Sie sich an diese Fehler zu erinnern, wenn mal etwas in R nicht so funktioniert wie erwartet.
Verschreiben
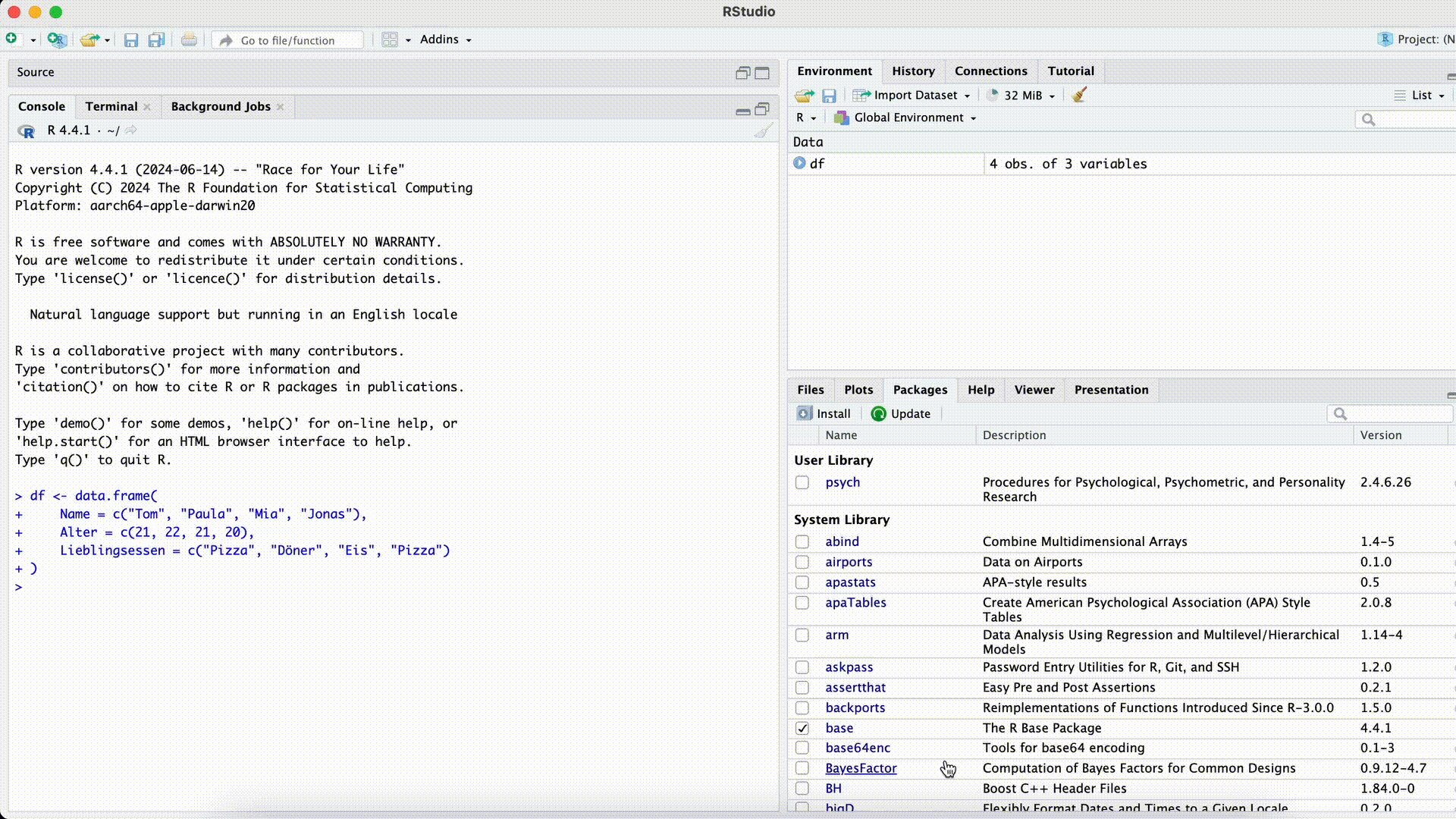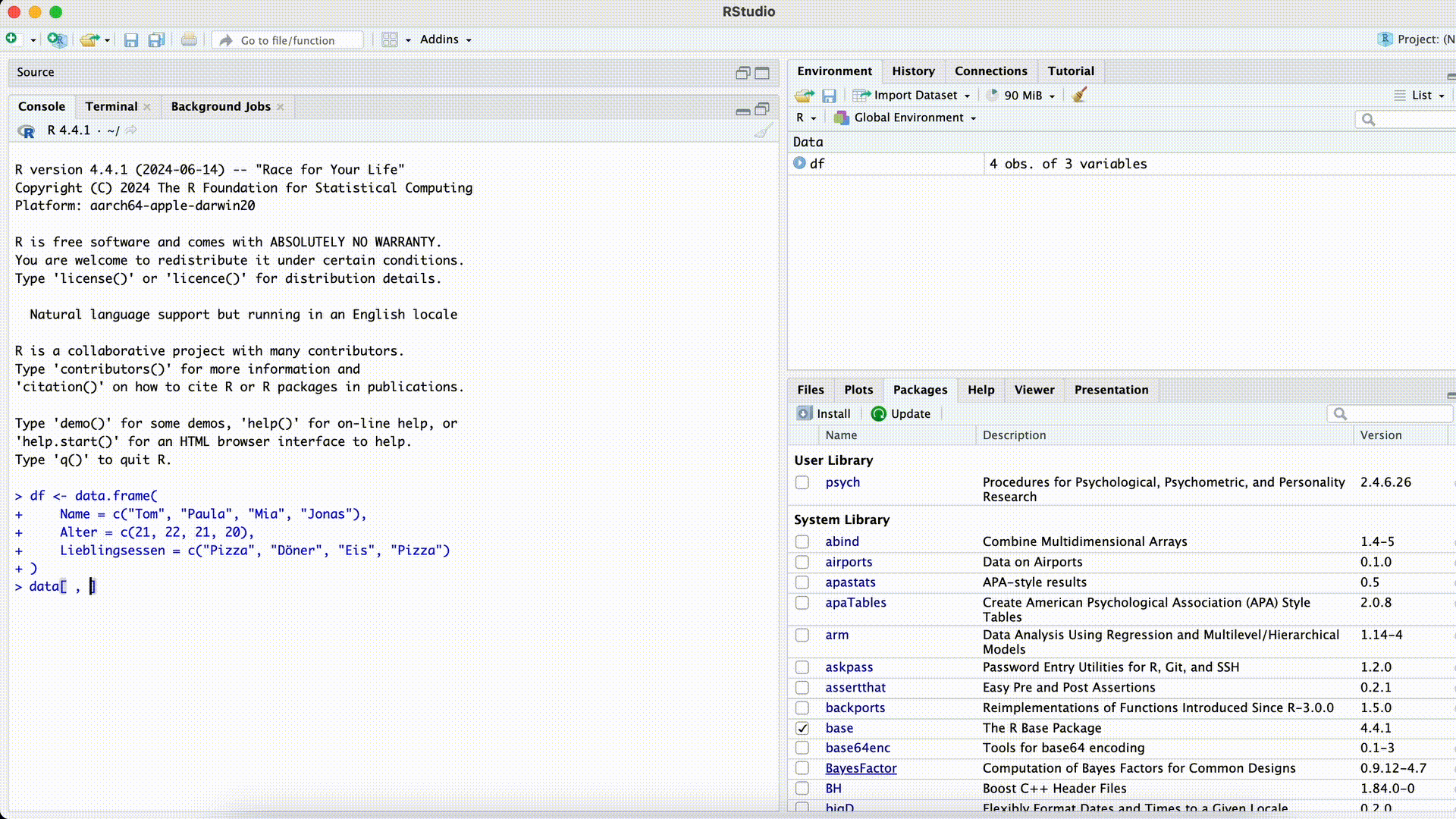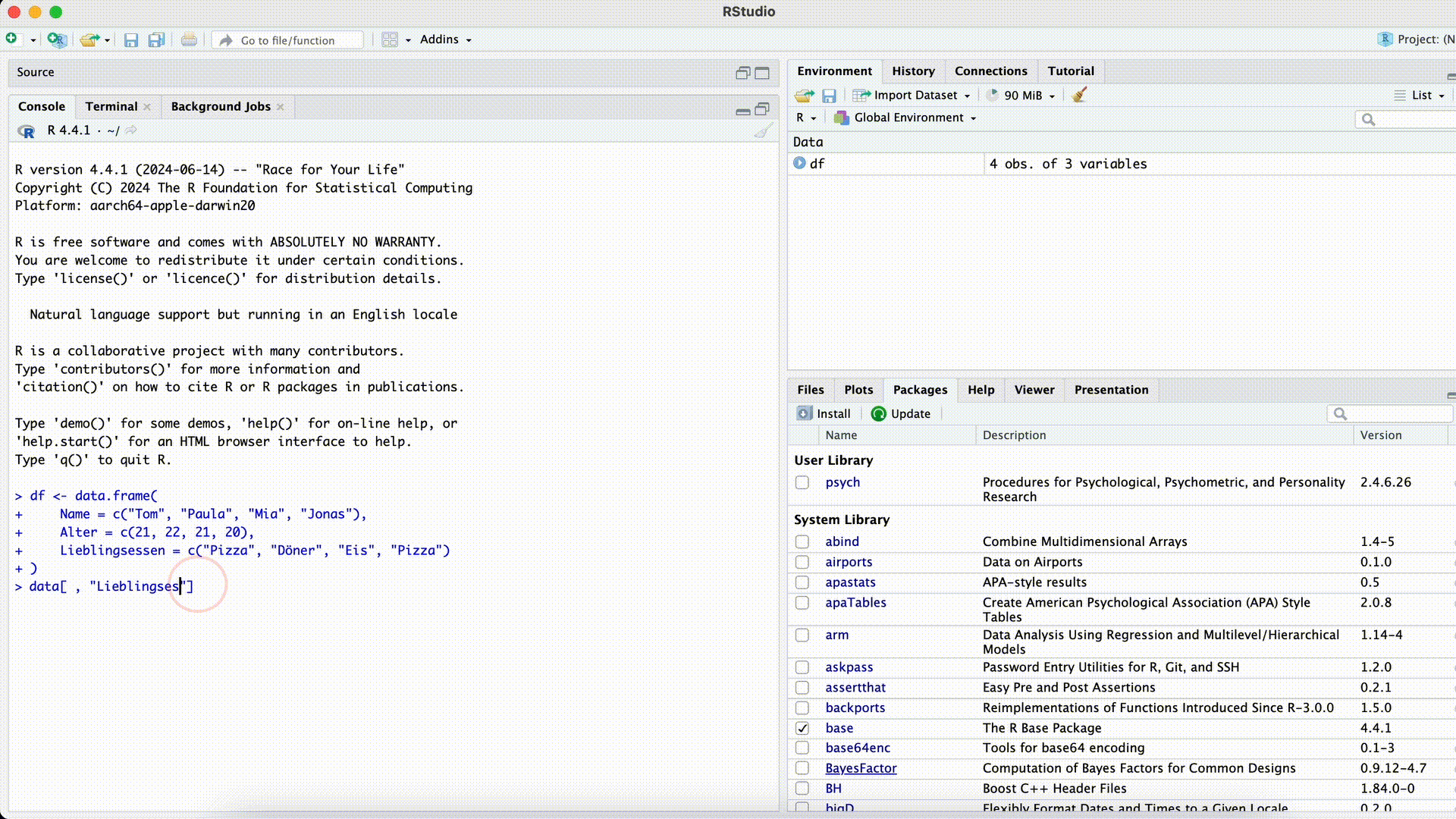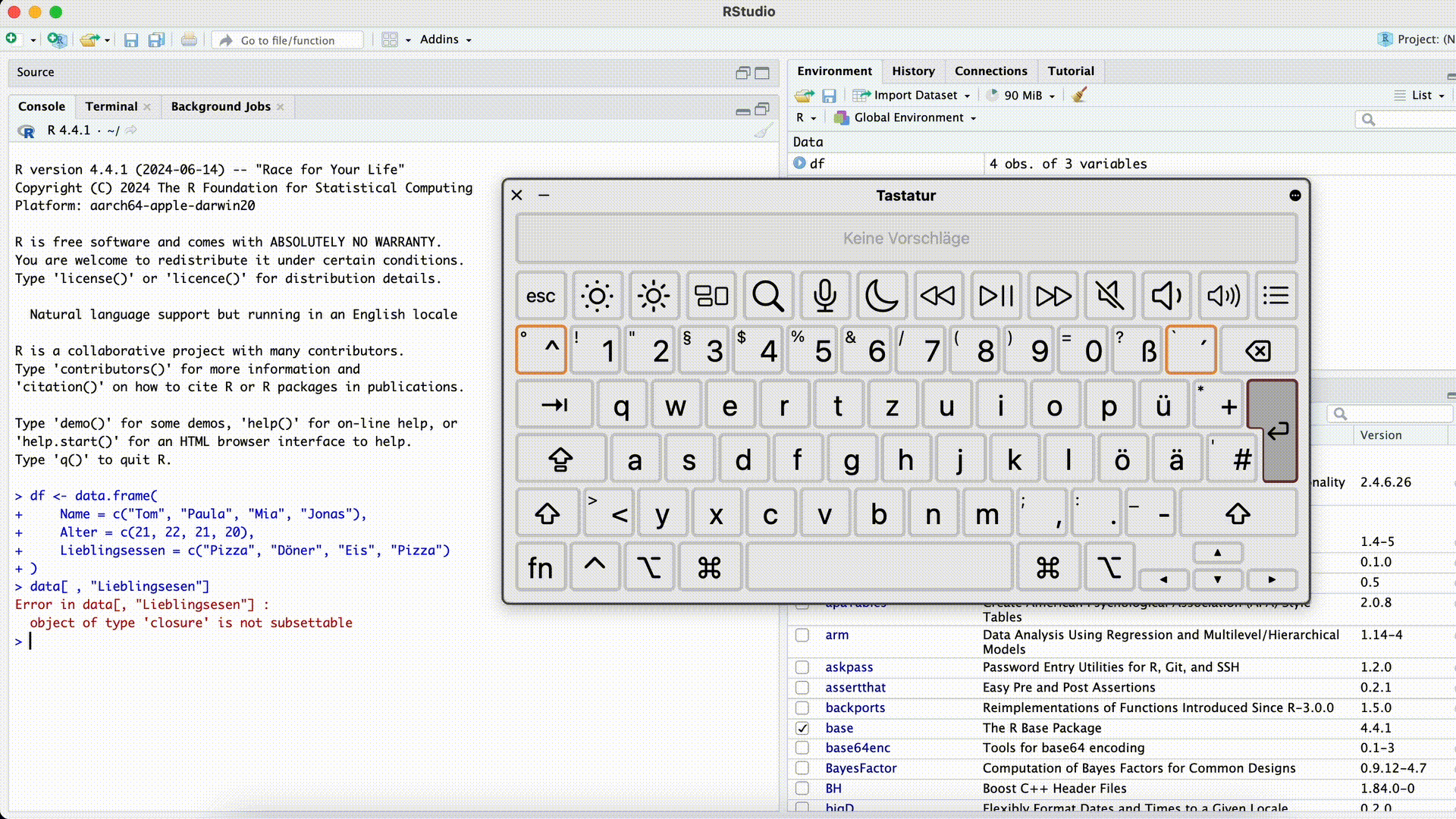
df[ , c("Lieblingsesen")]Error in `[.data.frame`(df, , c("Lieblingsesen")): undefined columns selectedSpaltenname falsch geschrieben
Wenn wir uns bei der Spaltenauswahl verschreiben, findet R die Spalte nicht.
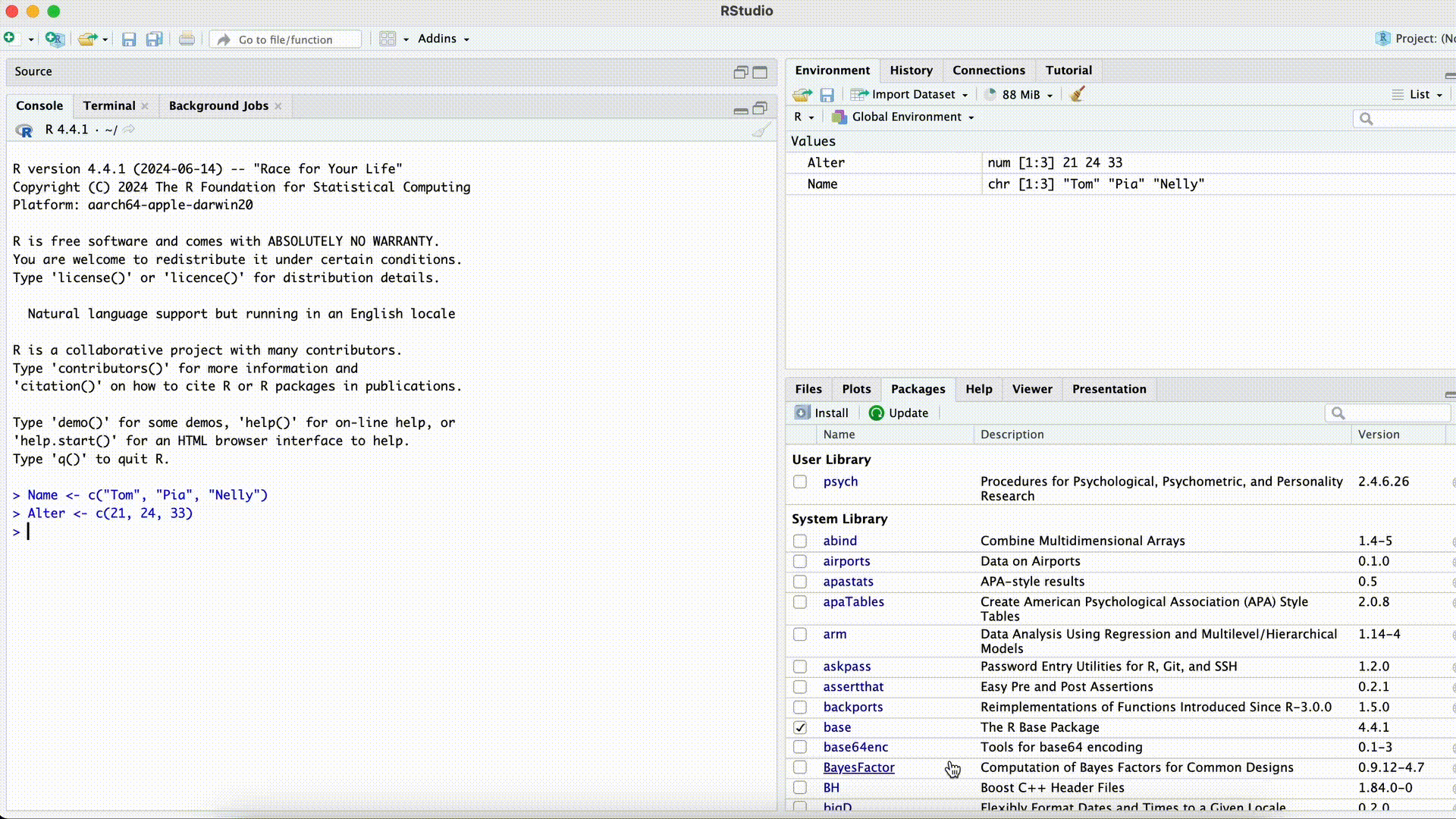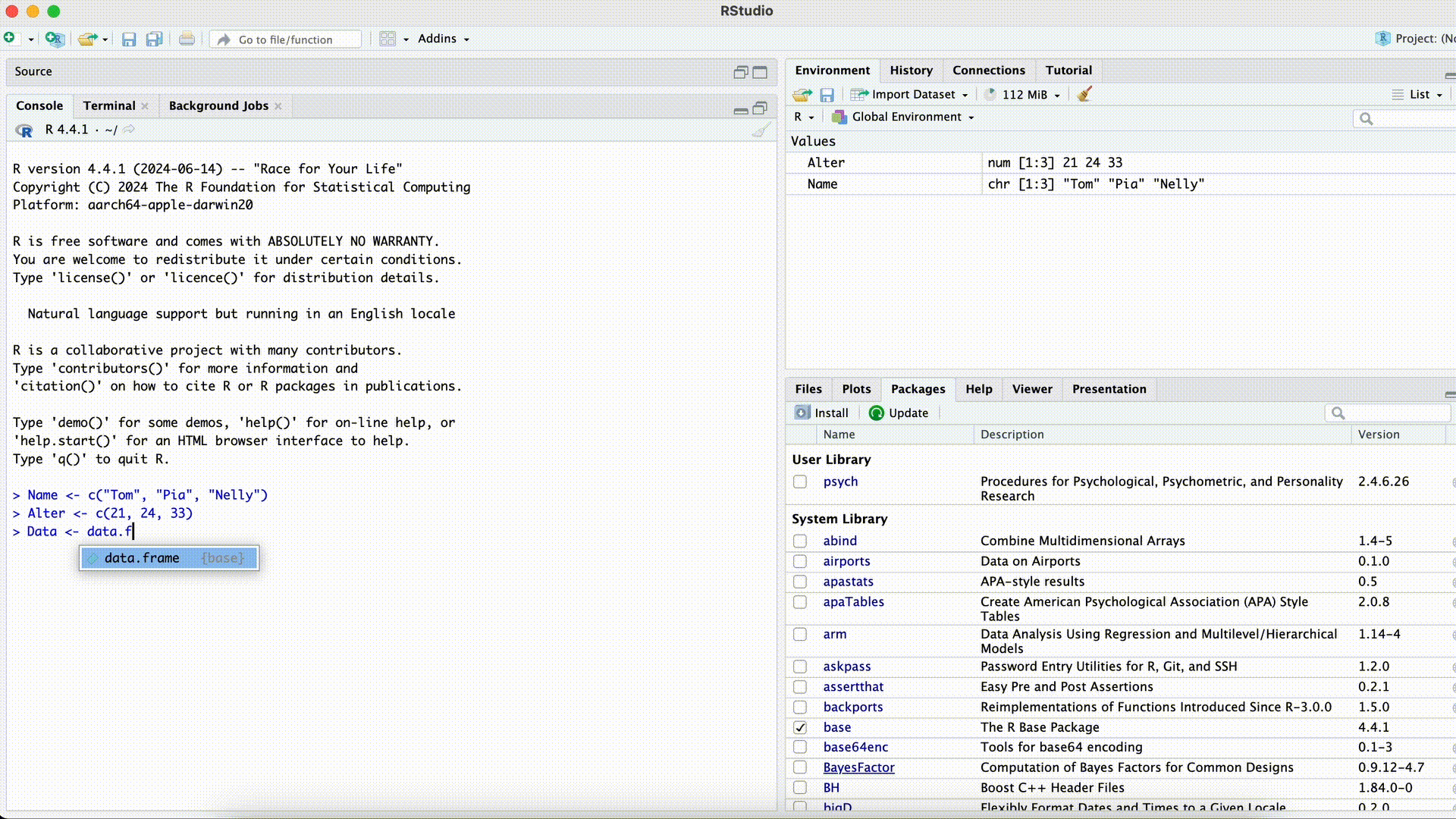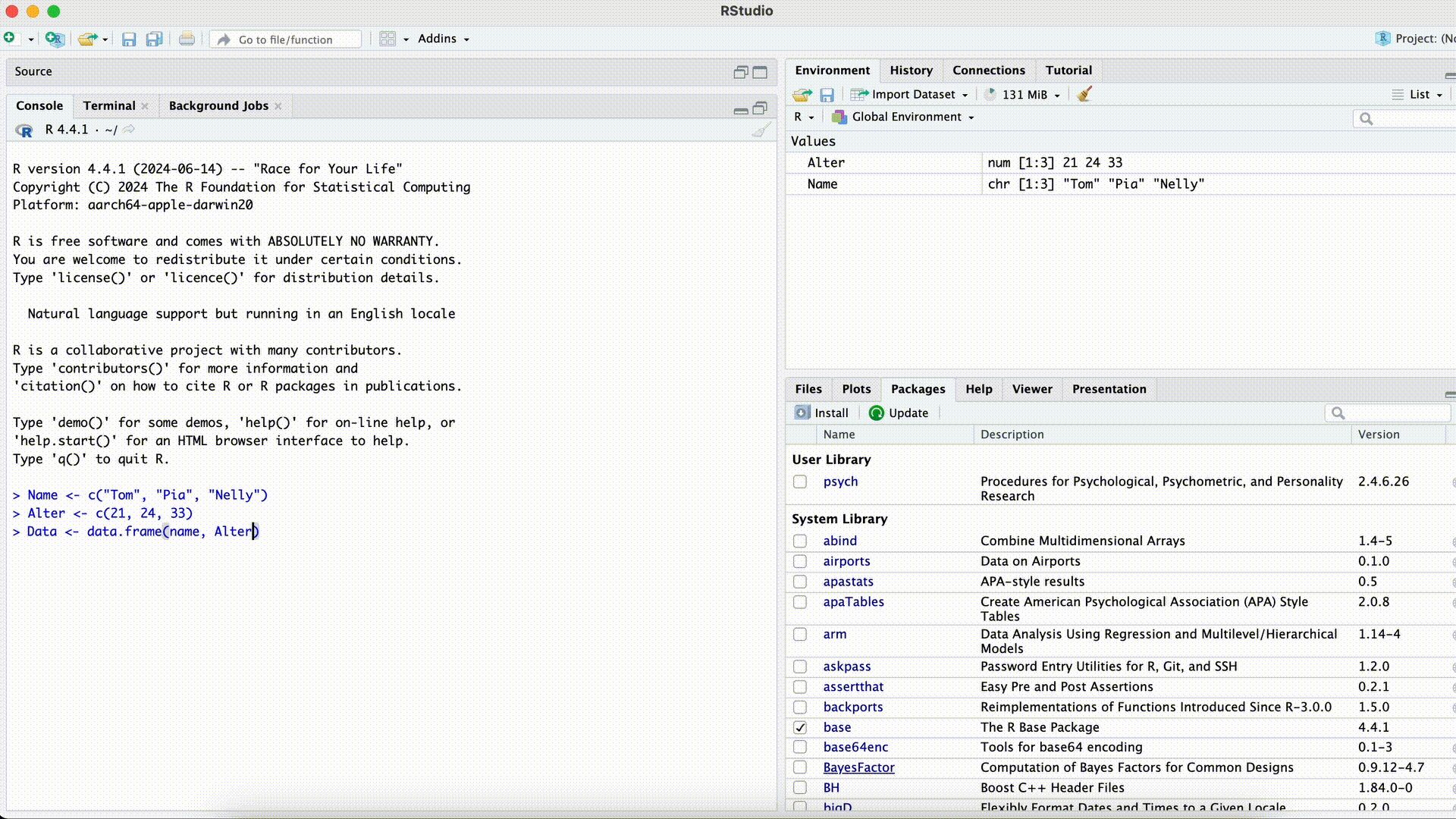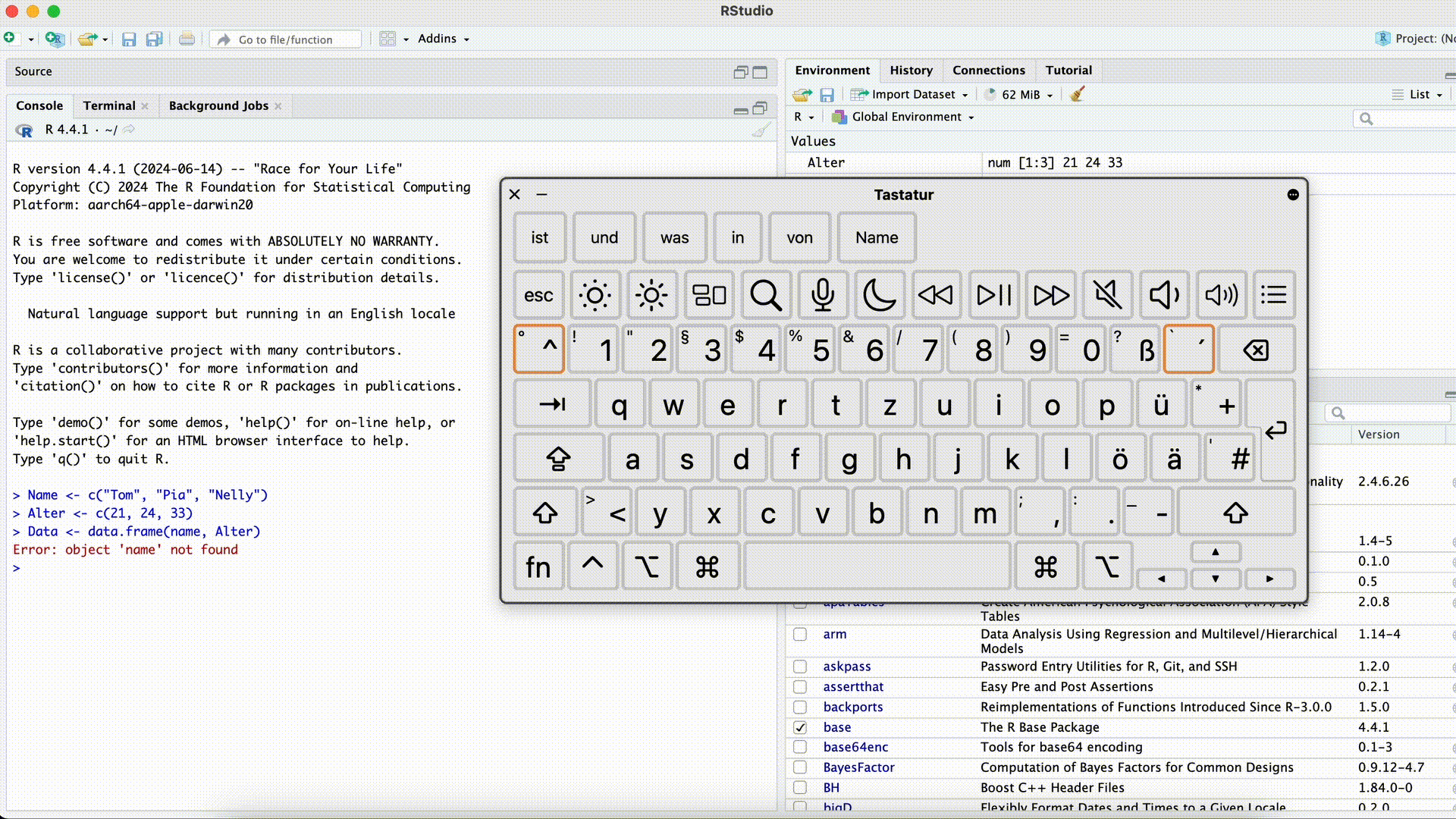
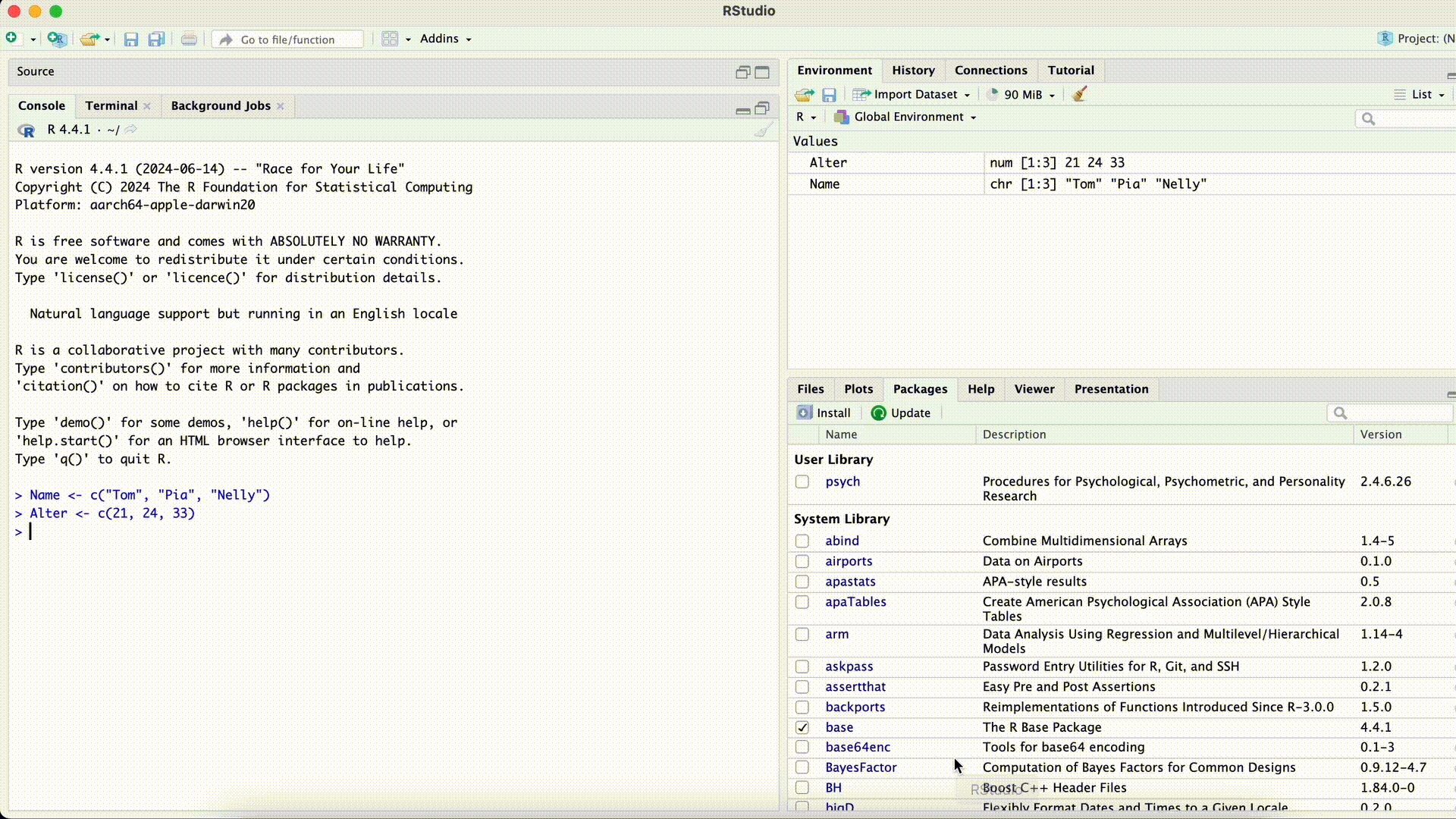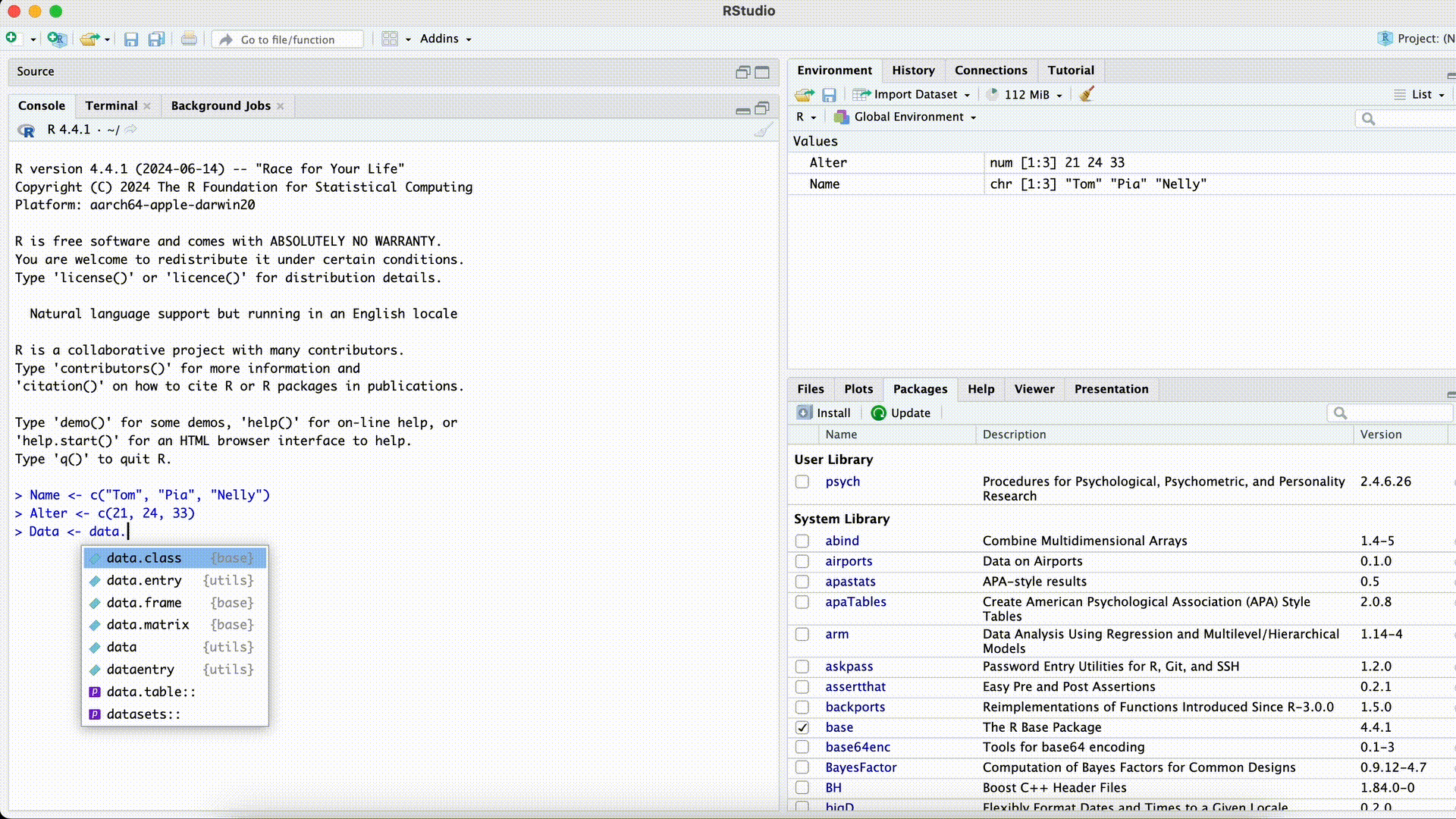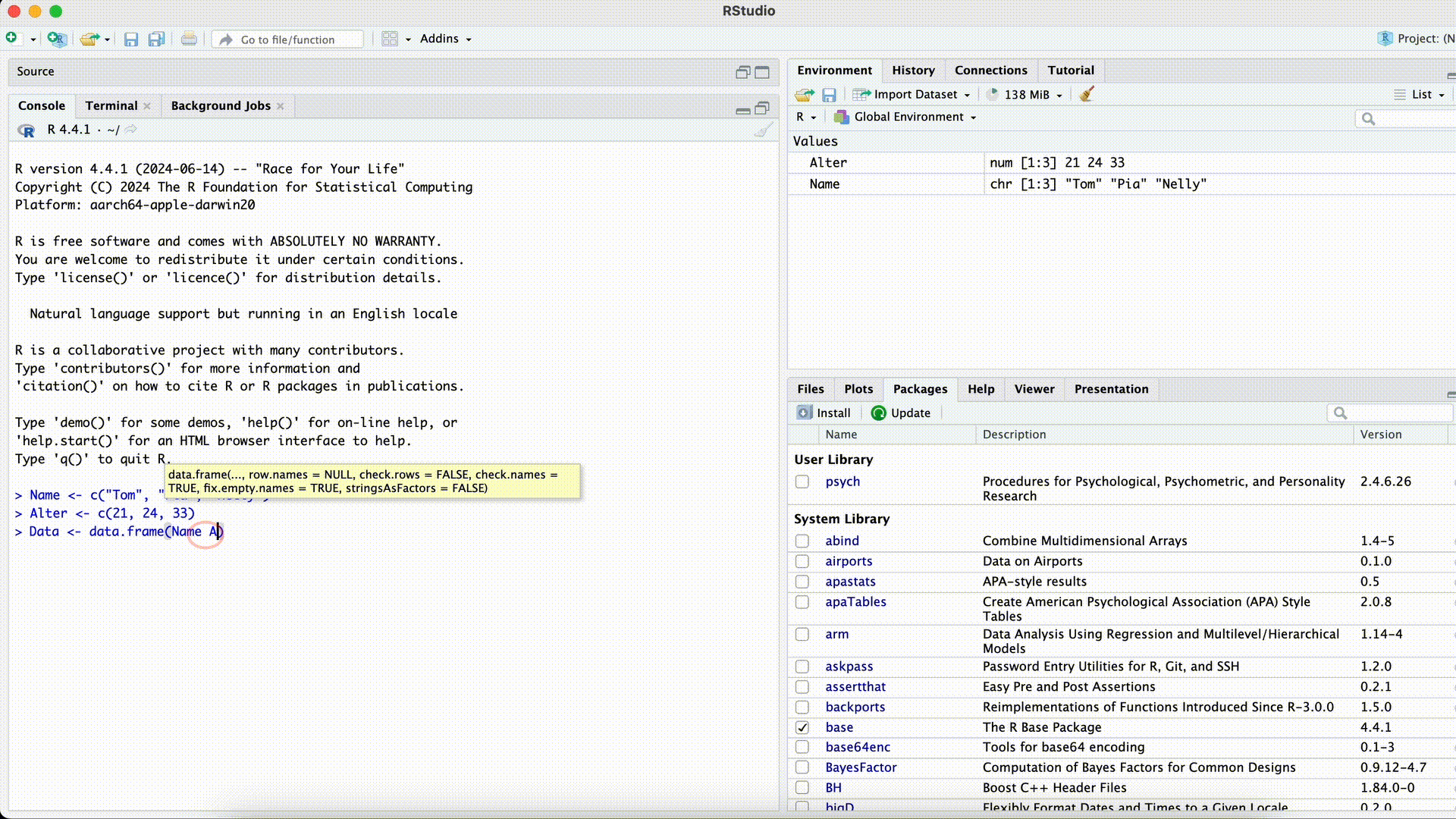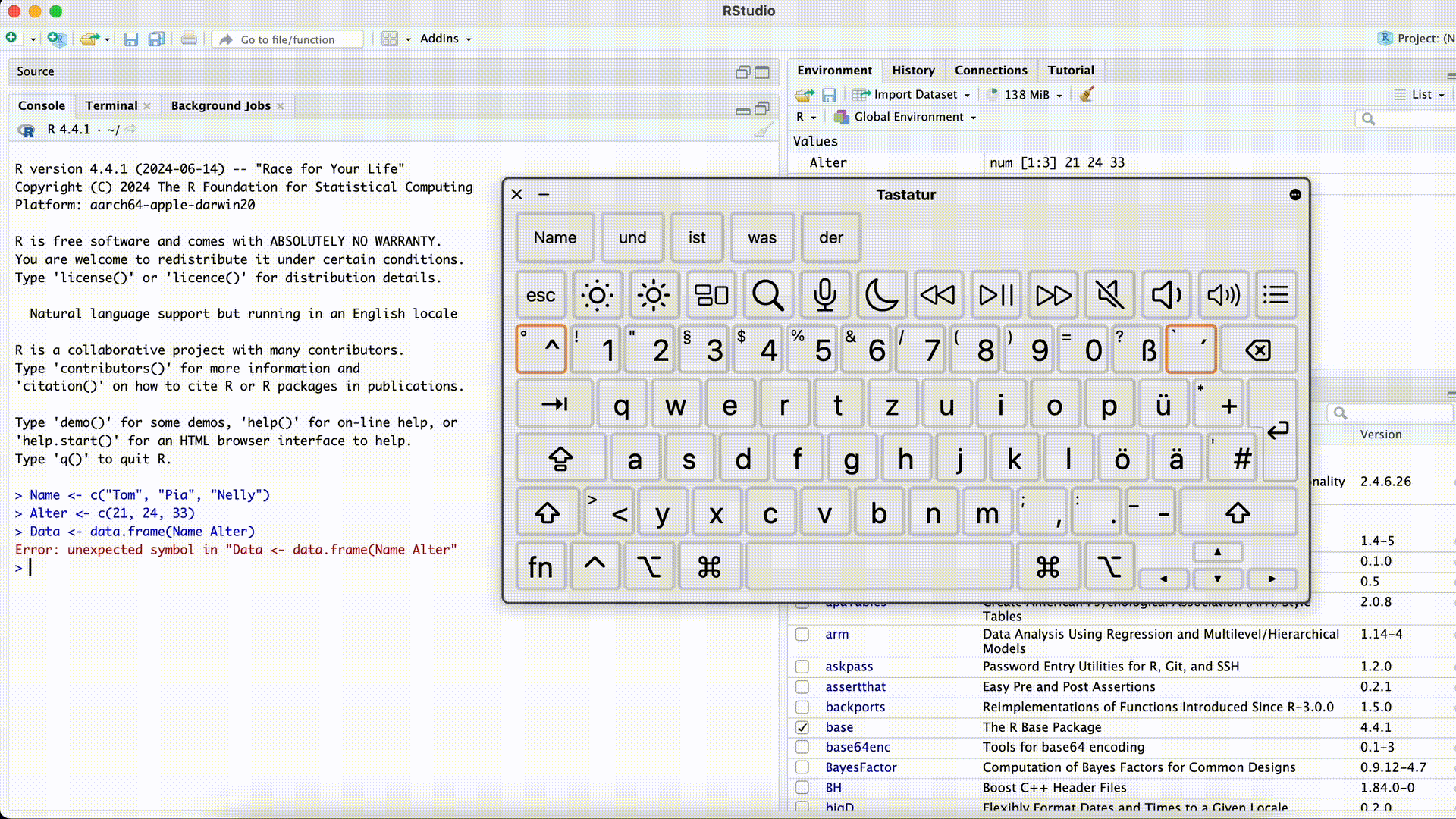
Name <- c("Tom", "Pia", "Nelly") Alter <- c(21, 24, 33) Data <- data.frame(name, Alter)Error in eval(expr, envir, enclos): object 'name' not foundSpaltenname bei der Auswahl falsch geschrieben
Komma vergessen
Data <- data.frame(Name Alter)Error: <text>:1:25: unexpected symbol 1: Data <- data.frame(Name Alter ^Ein unerwartetes Symbol heißt oft, dass innerhalb einer Funktion ein Komma zwischen Argumenten vergessen wurde.
Komma vergessen
Anführungszeichen bei Strings vergessen
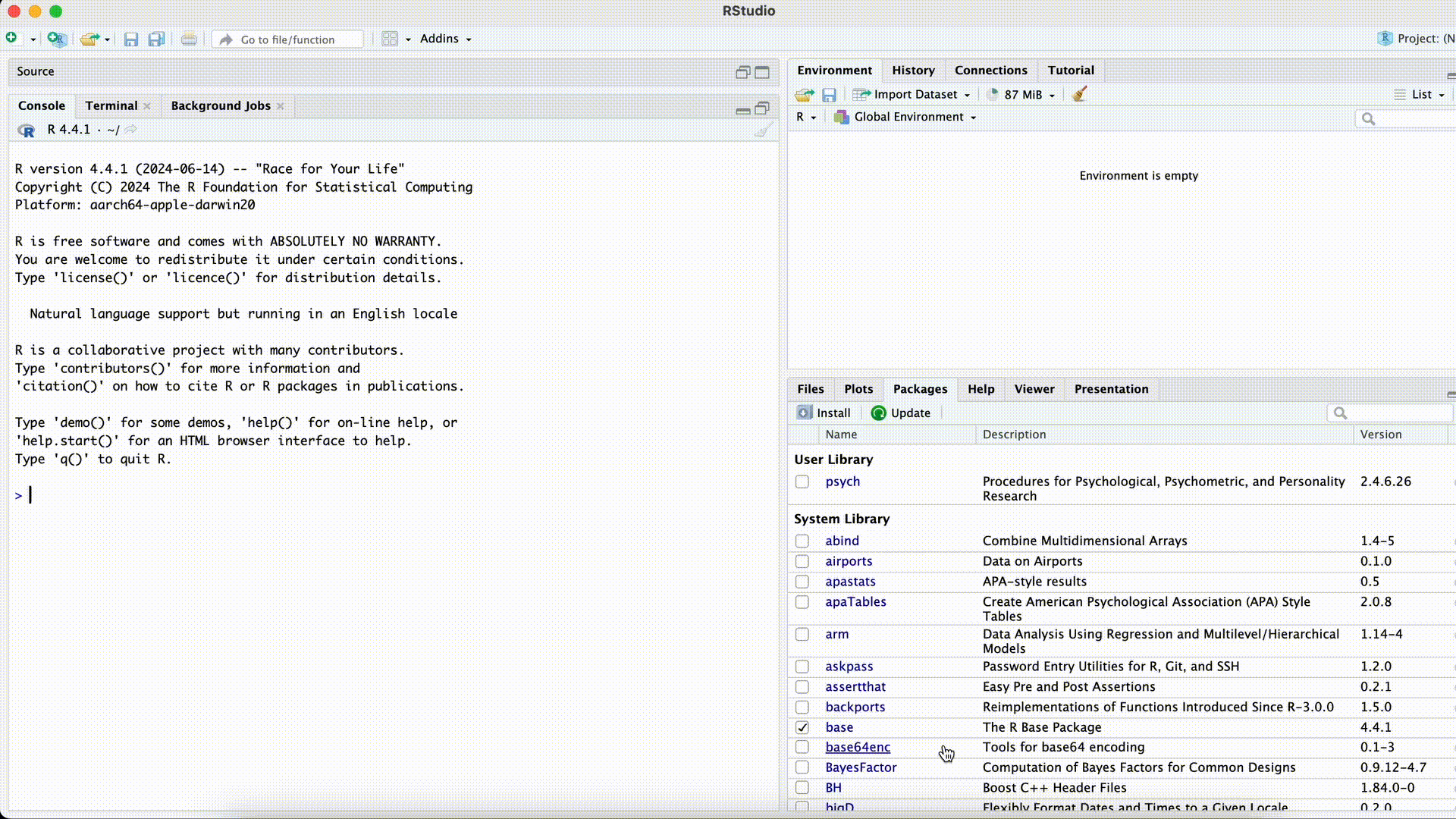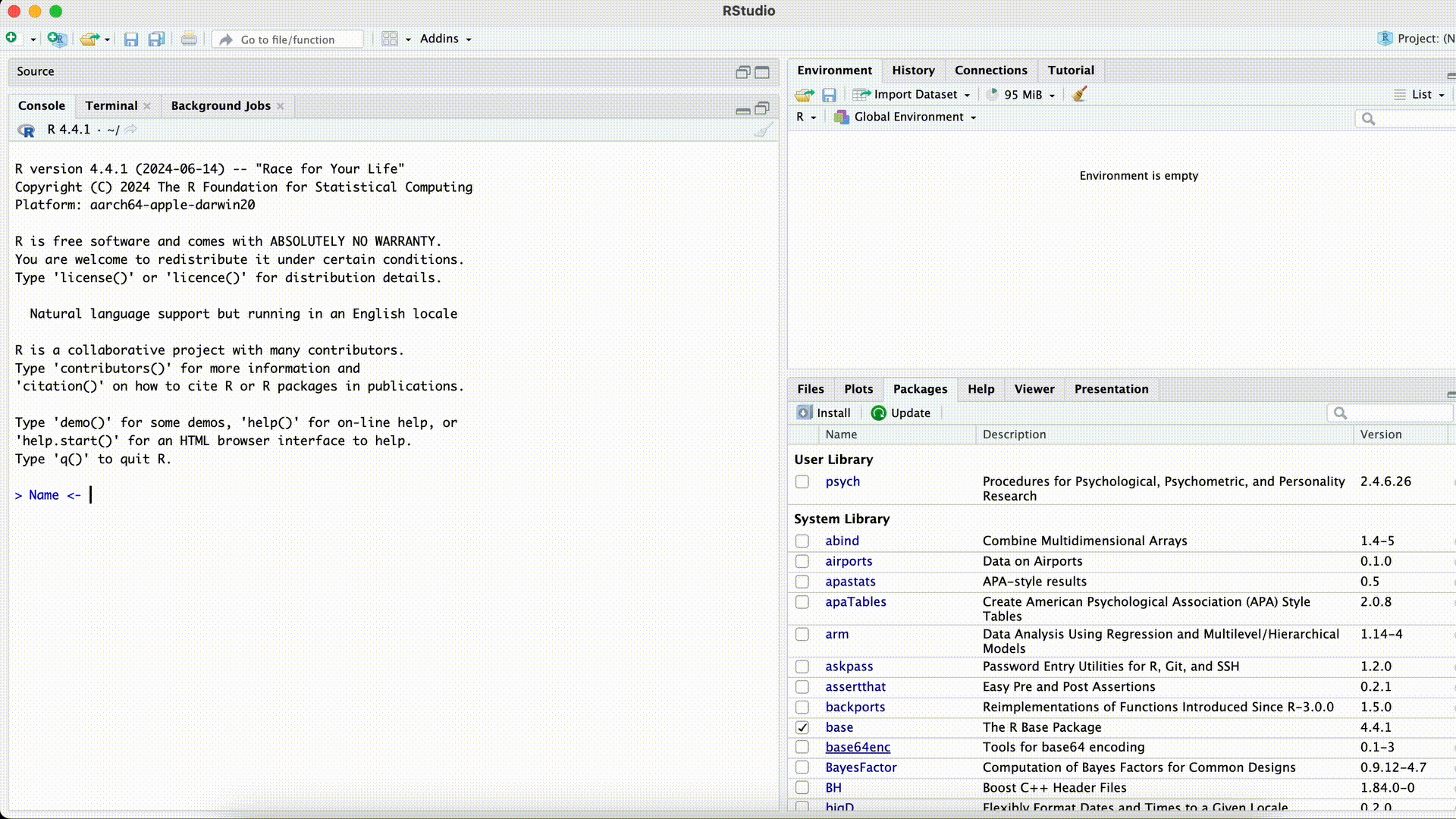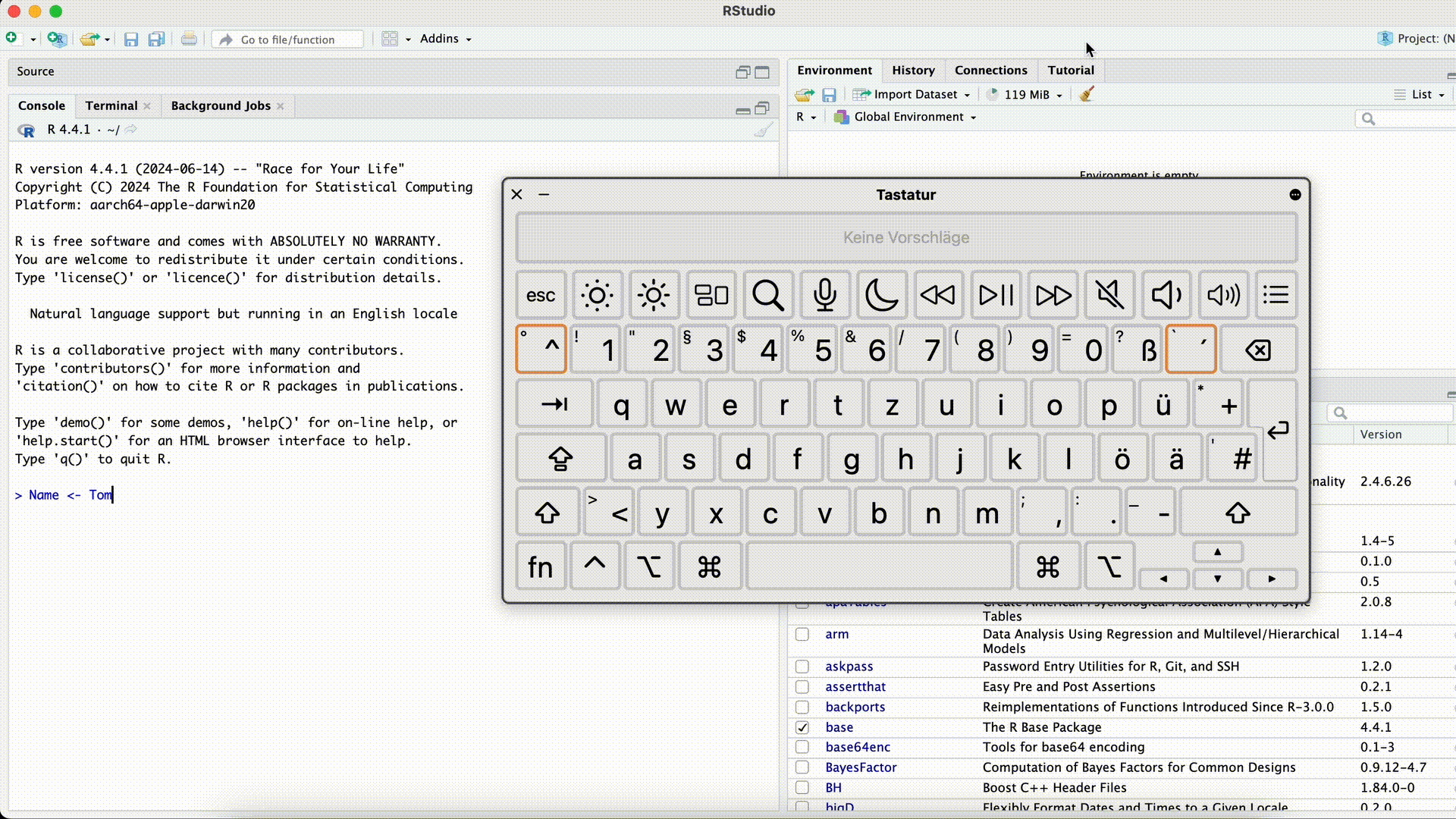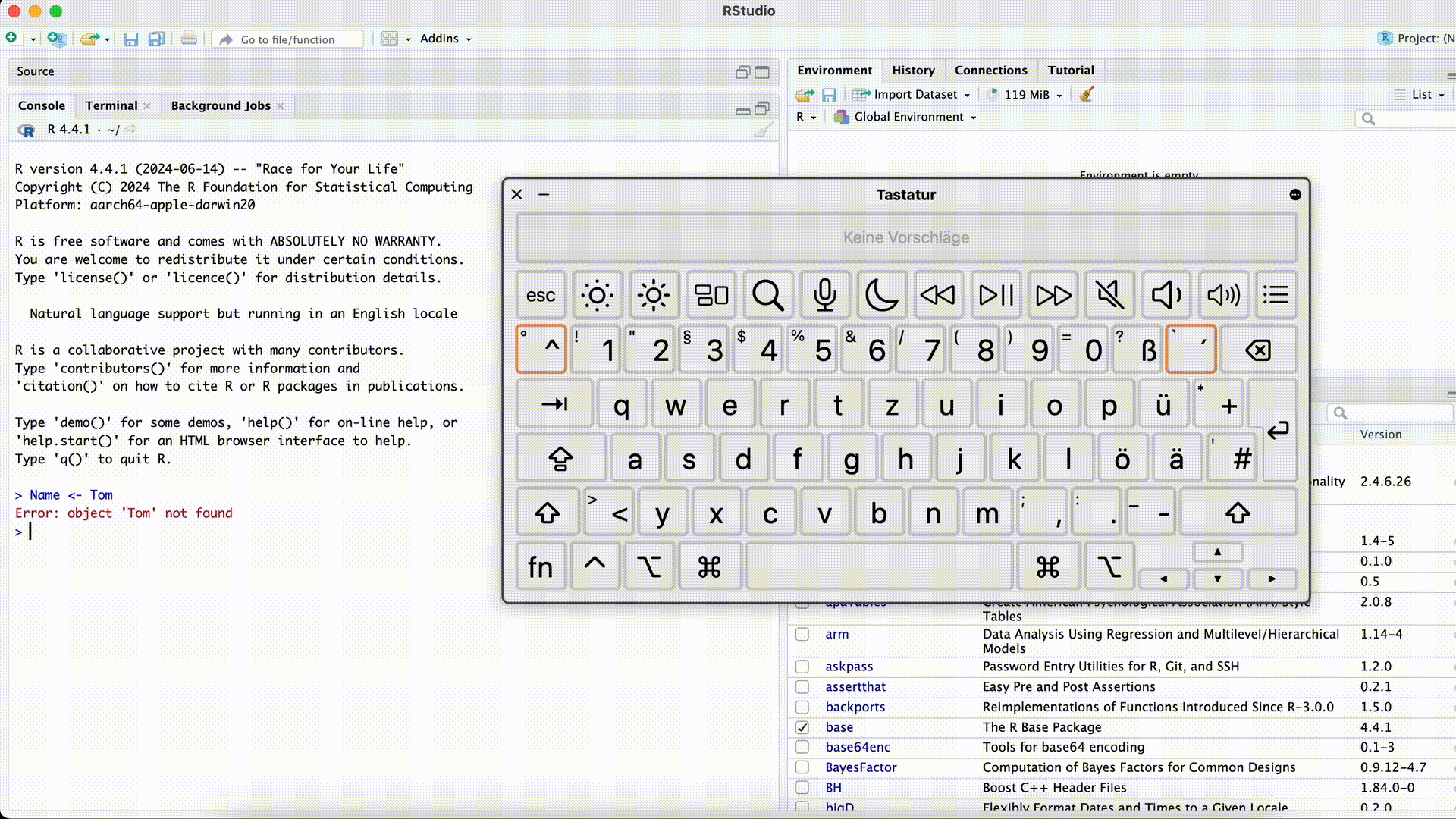
Name <- TomError in eval(expr, envir, enclos): object 'Tom' not foundstatt
Name <- "Tom"Anführungszeichen bei Strings vergessen
Schließendes Anführungszeichen vergessen
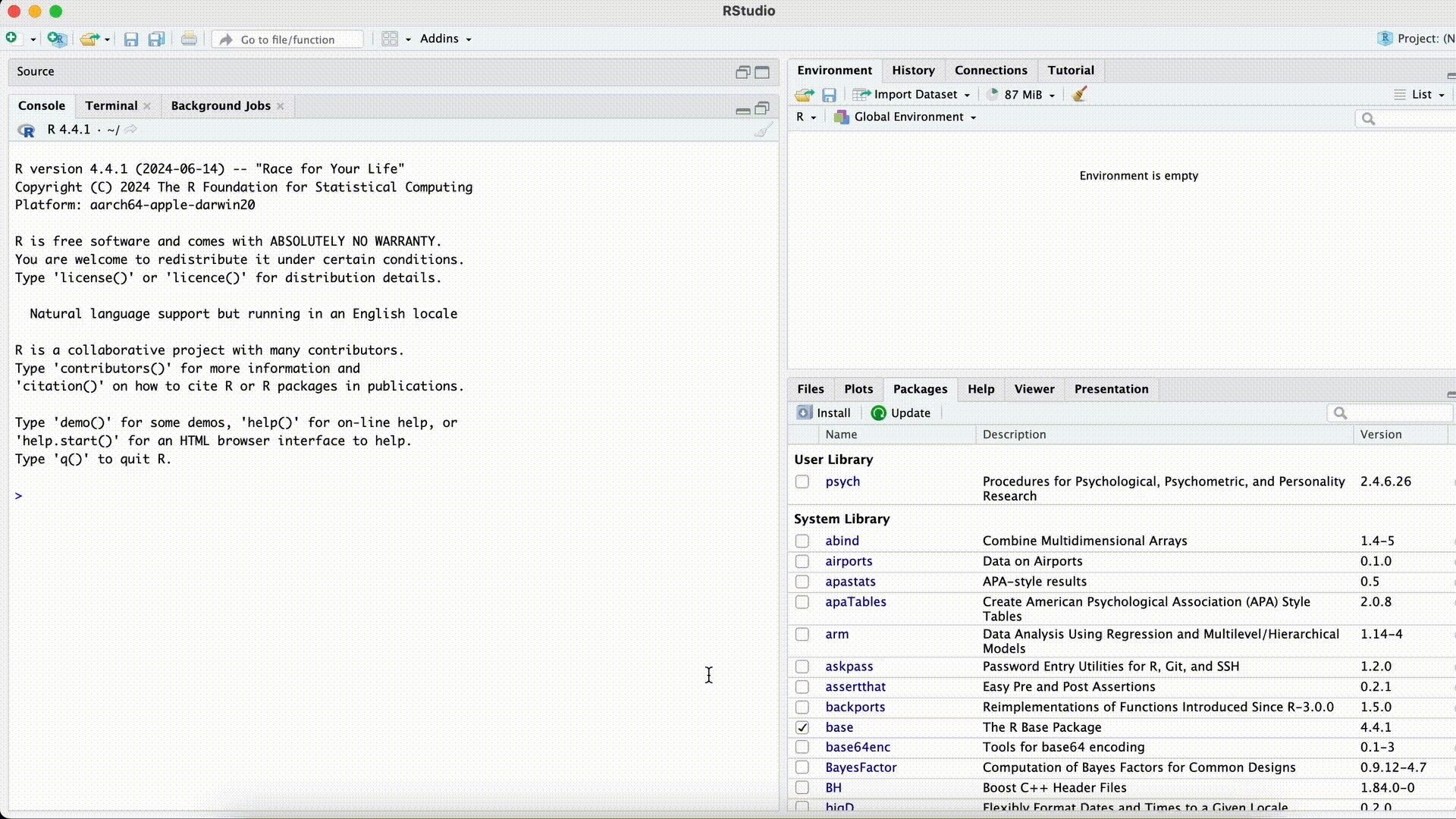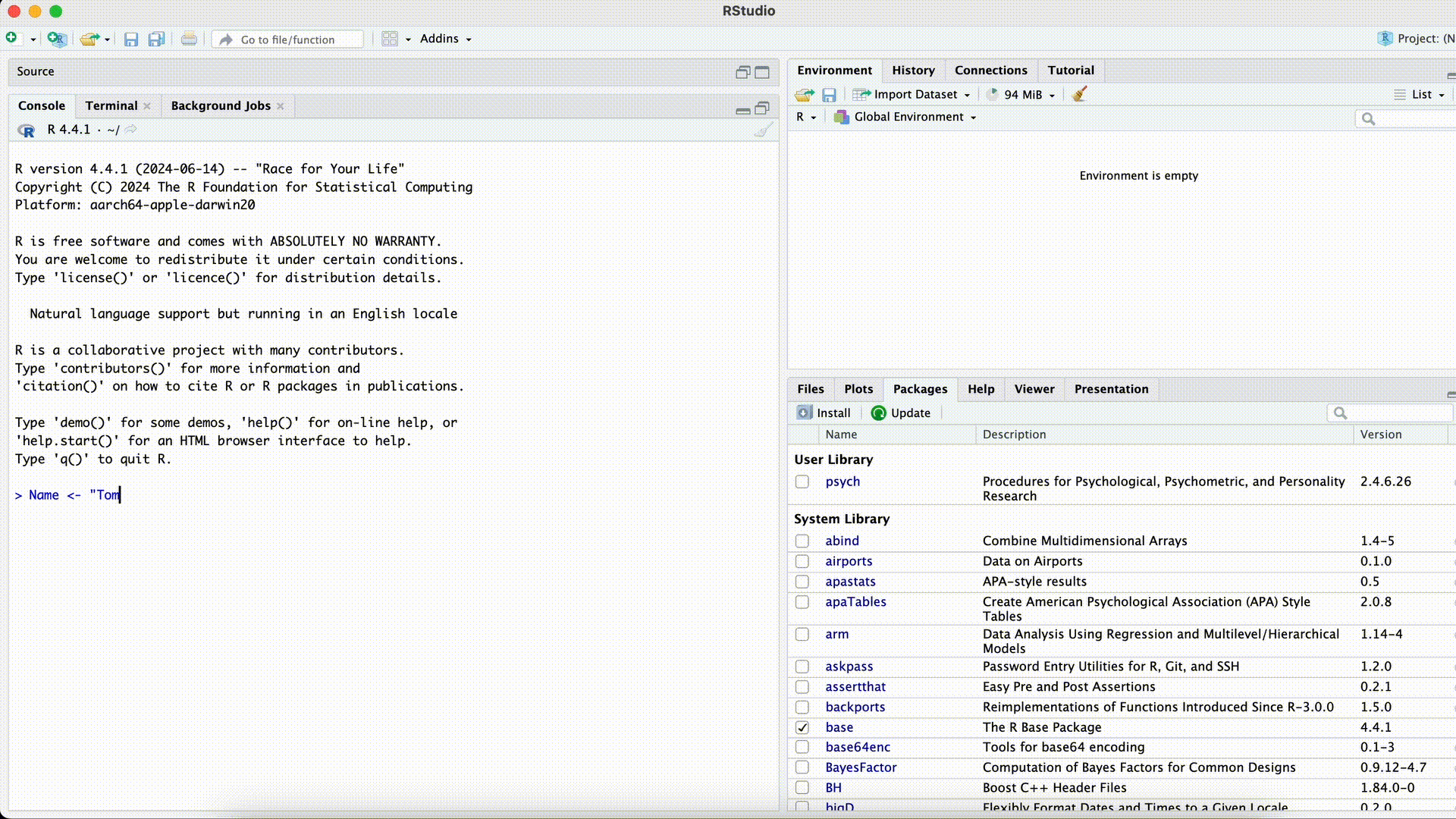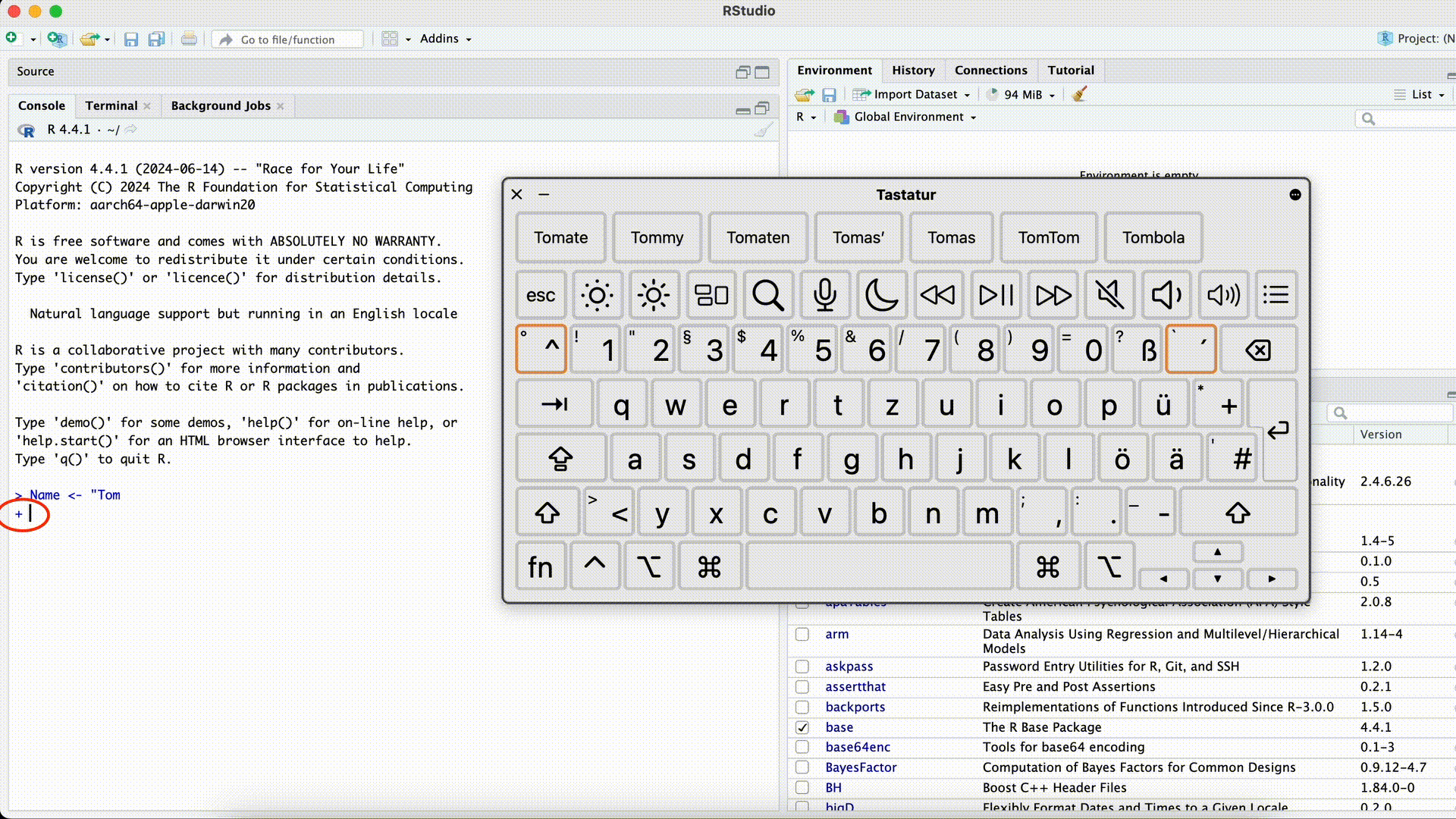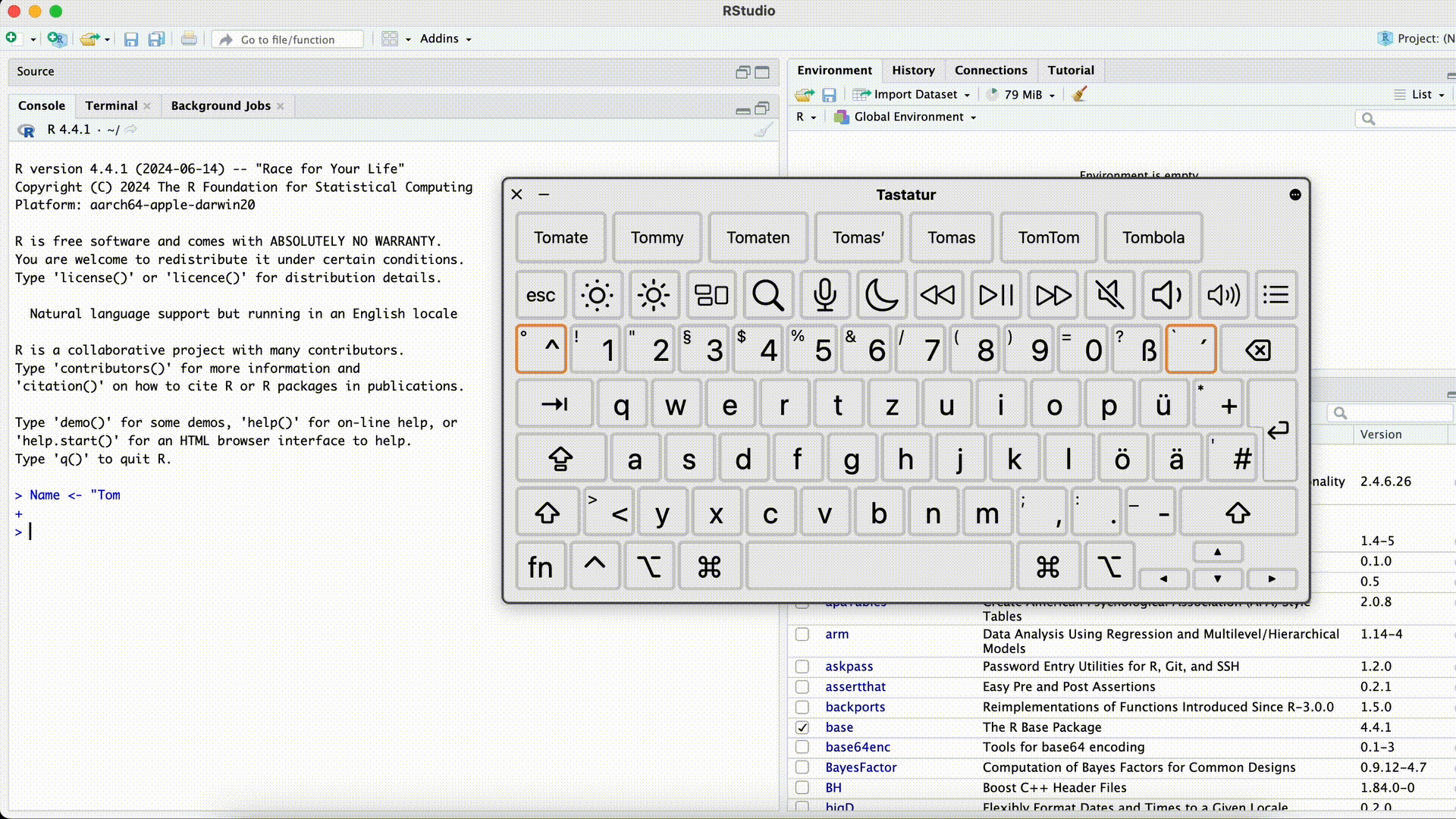
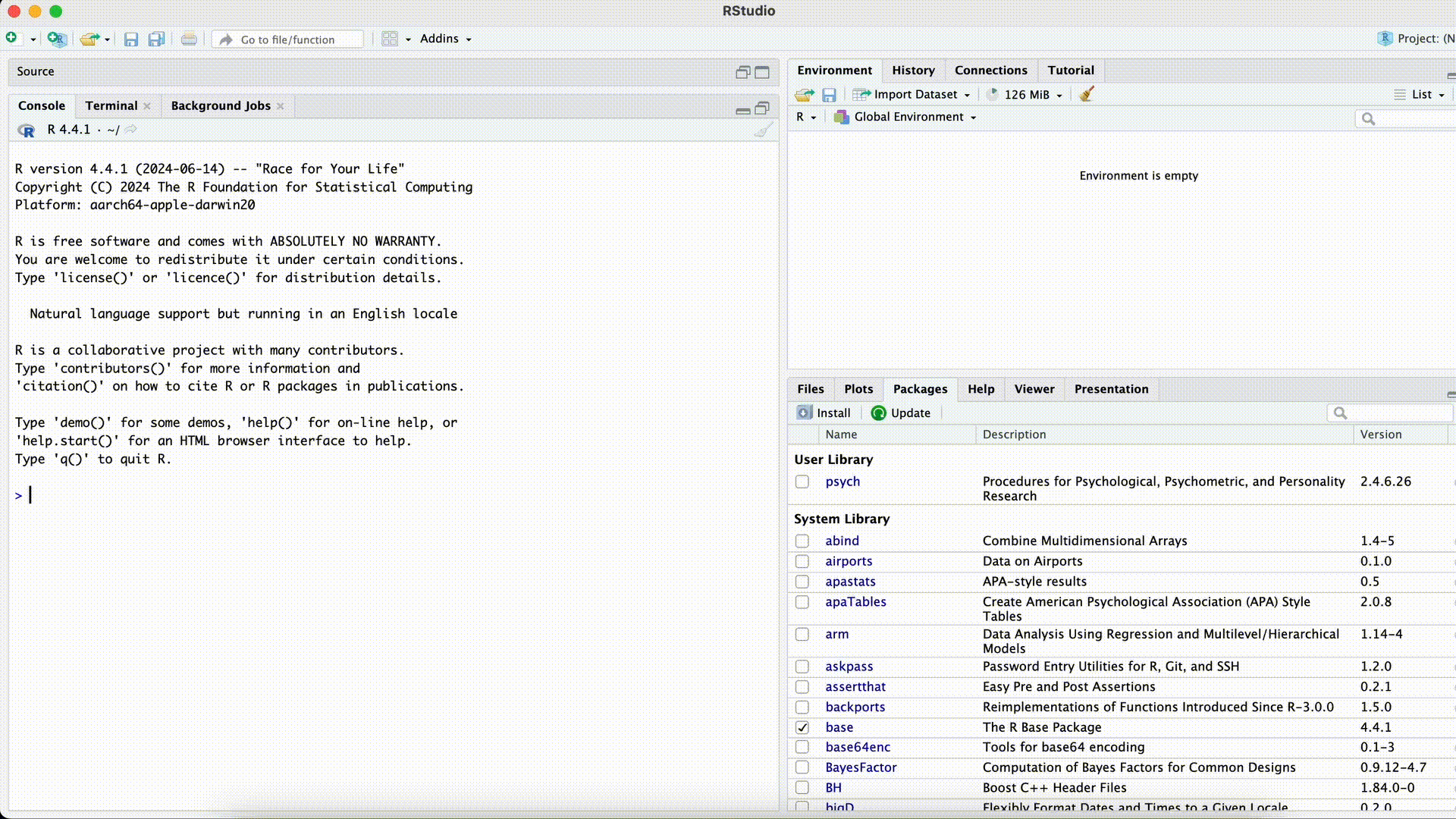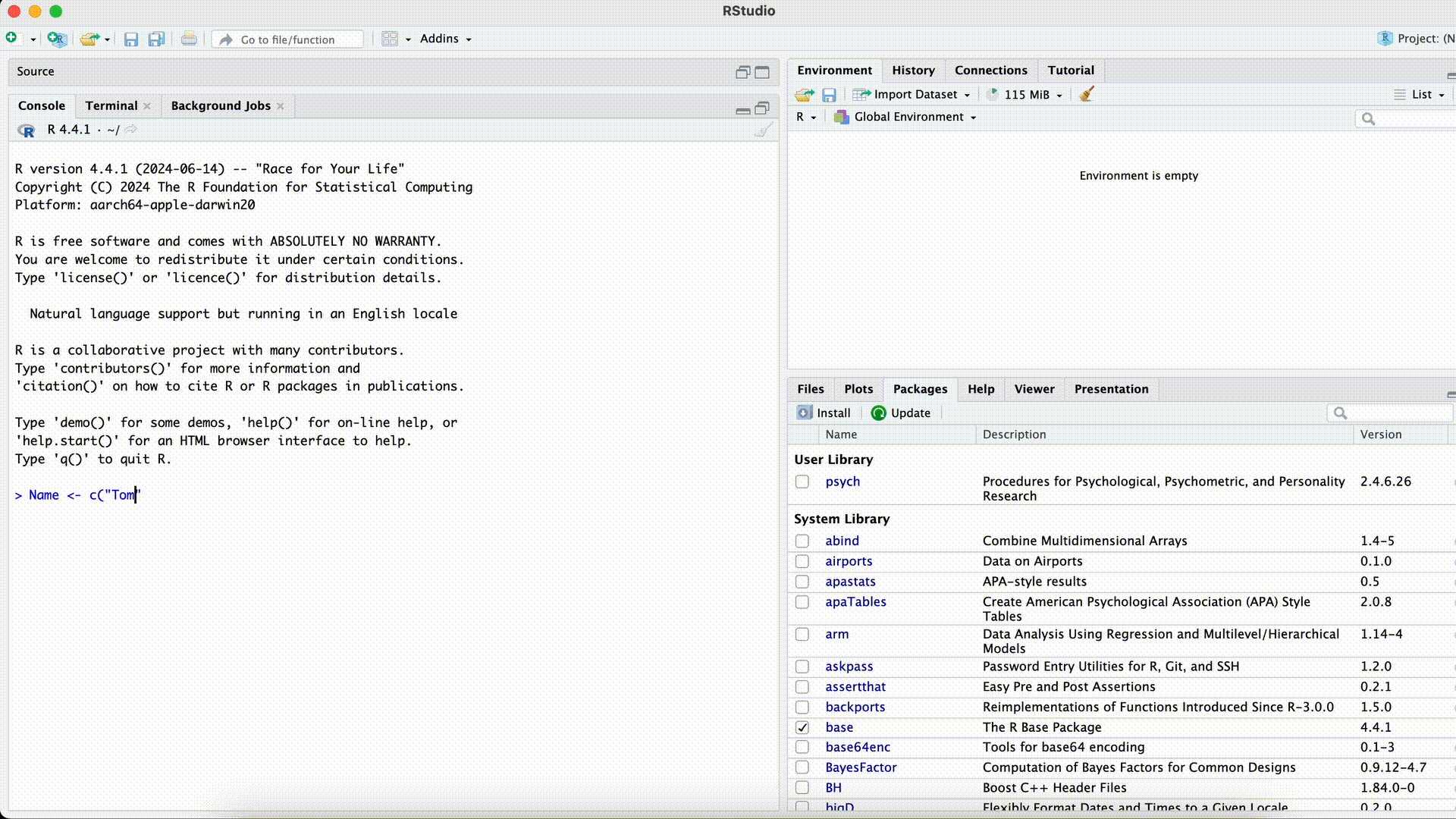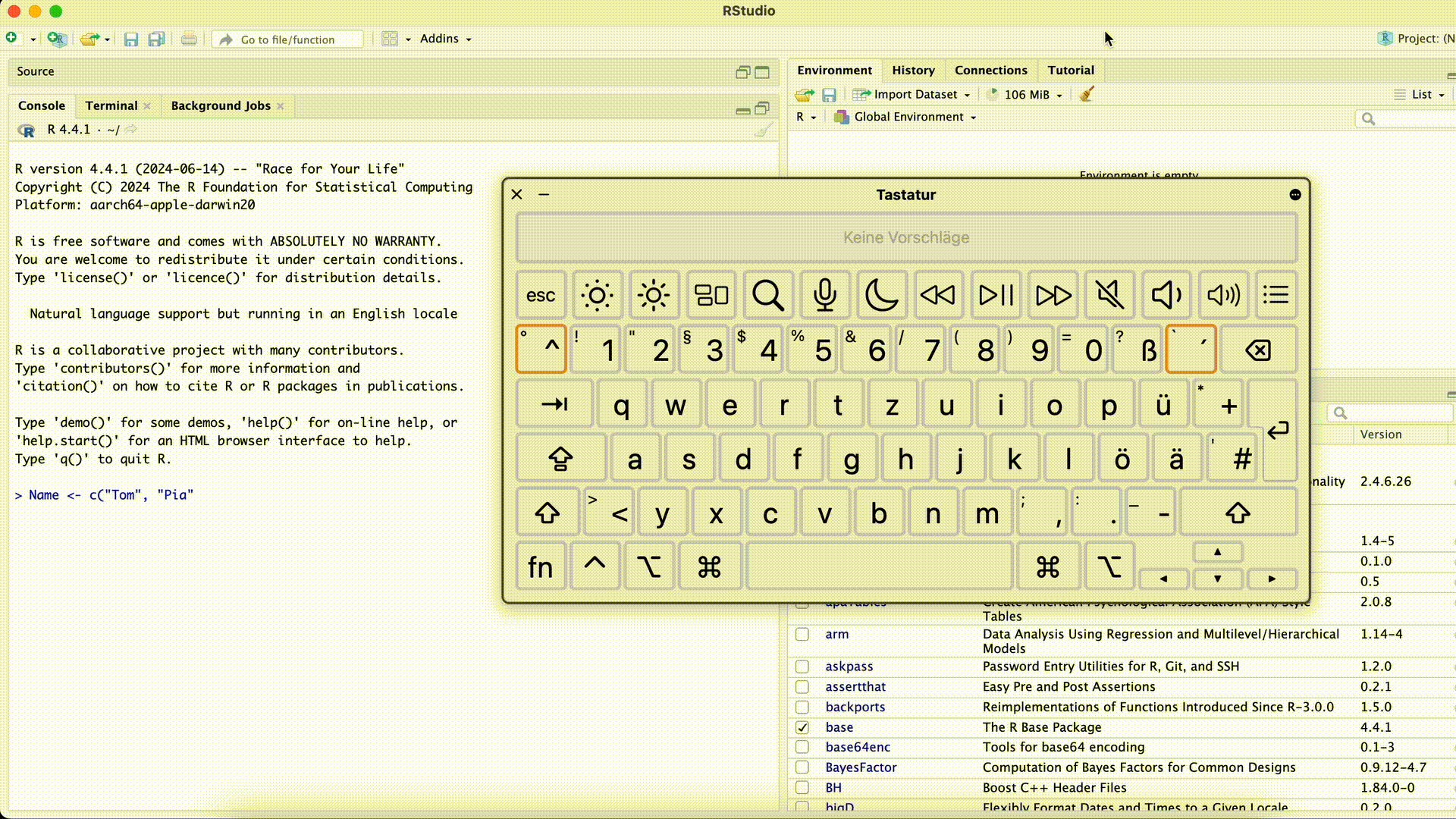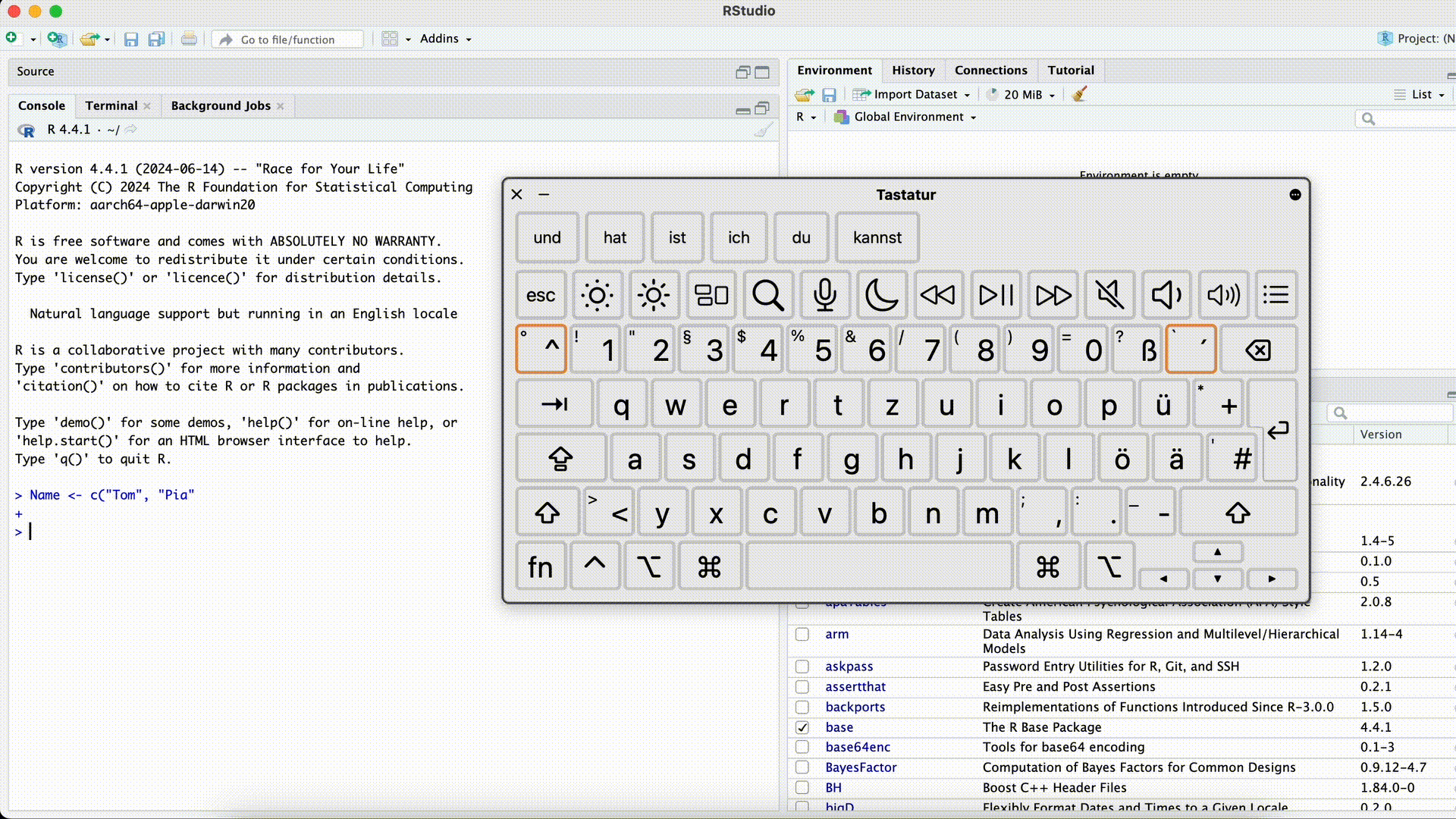
Name <- "Tom> Name <- "Tom +Dieser Fehler ist besonders verwirrend, da R den Befehl erst dann ausführt, wenn die Anführungszeichen wieder geschlossen wurden (R denkt es fehlt noch etwas und “wartet”). Die Console zeigt dann statt
>immer+an, und reagiert nicht mehr normal auf neue Befehle. In diesem Fall ist es am einfachsten, mit der Maus in die Console zu klicken und die Esc-Taste zu drücken. Danach können Sie den Befehl nochmal korrekt eingeben.Anführungszeichen vergessen
Klammer vergessen
Name <- c("Tom", "Pia"> Name <- c("Tom", "Pia" +Auch bei diesem Fehler zeigt die Console solange
+an, bis Sie die Klammer geschlossen haben. In diesem Fall ist es wieder am einfachsten, mit der Maus in die Console zu klicken und die Esc-Taste zu drücken.schließende Klammer vergessen
Funktion falsch geschrieben
Data <- dataframe(Name, Alter)Error in dataframe(Name, Alter): could not find function "dataframe"Funktion falsch geschrieben
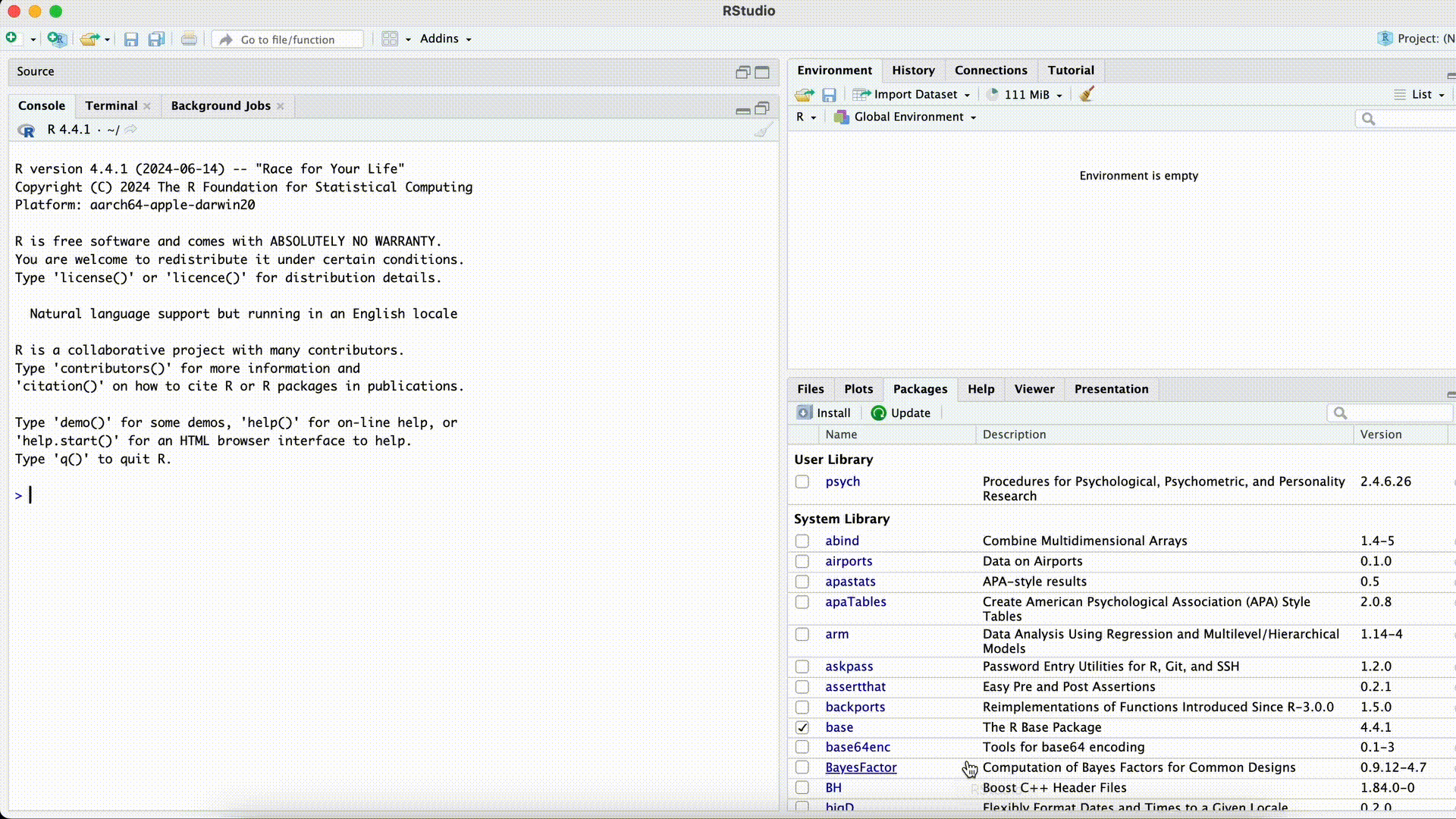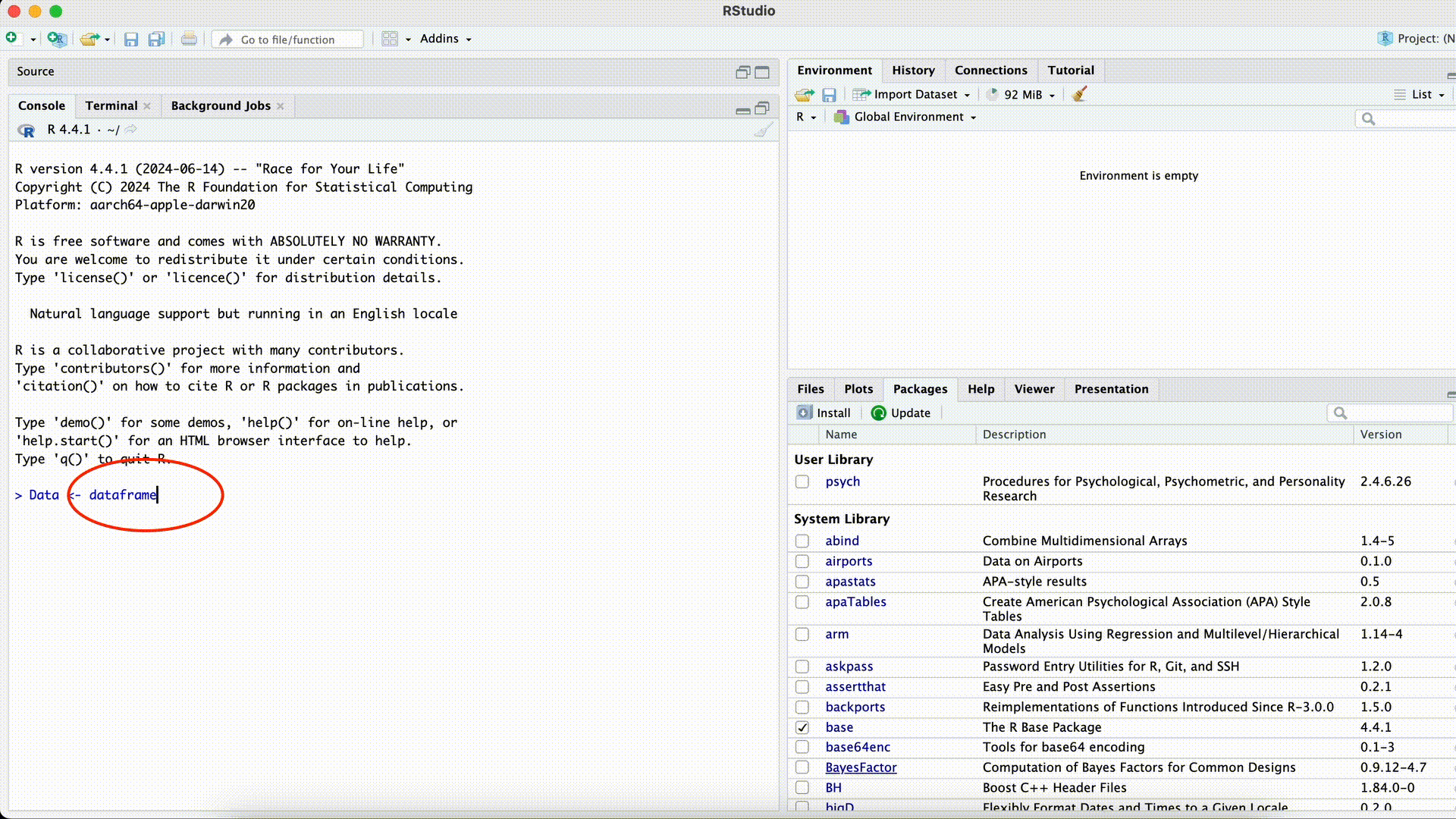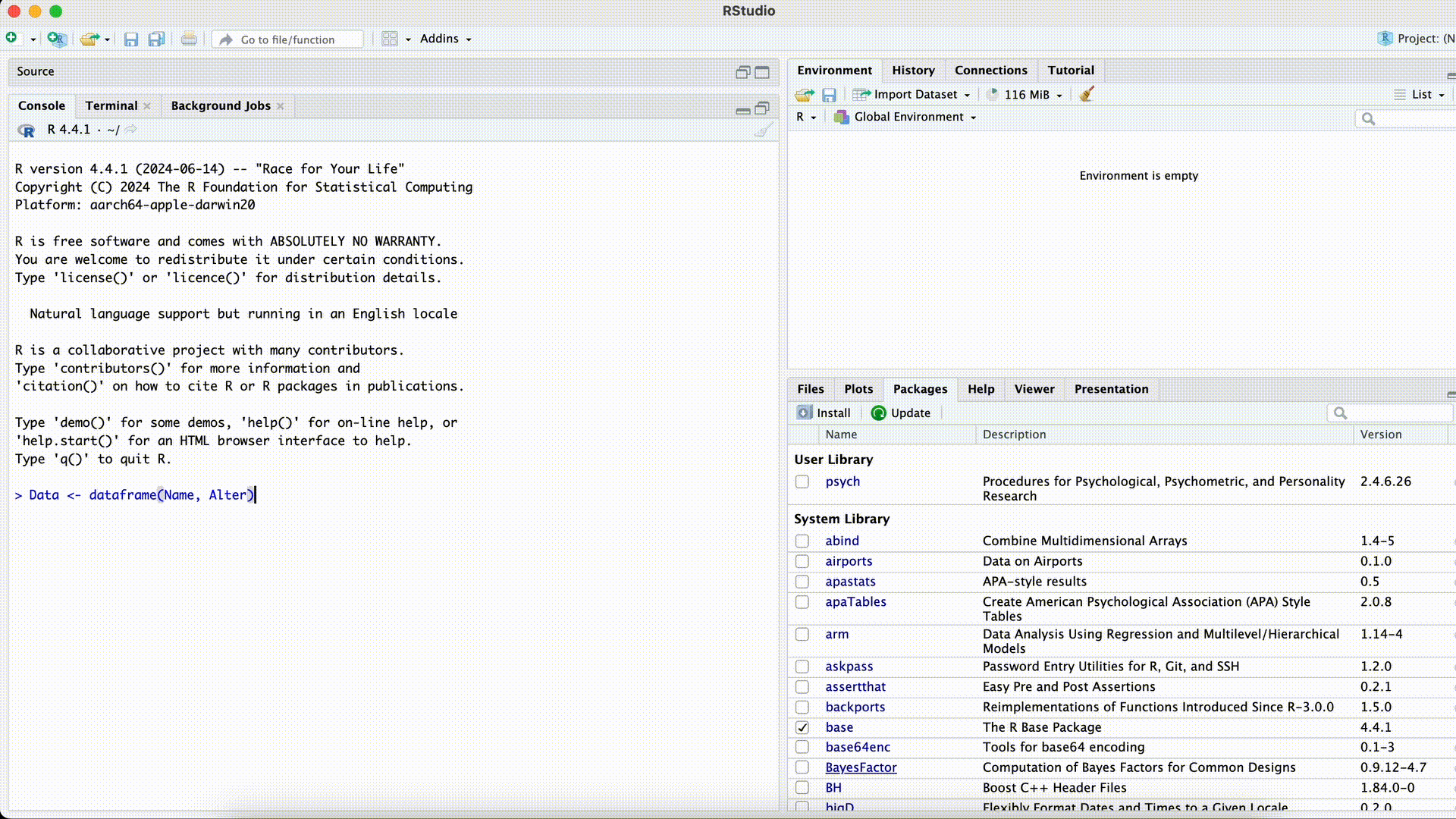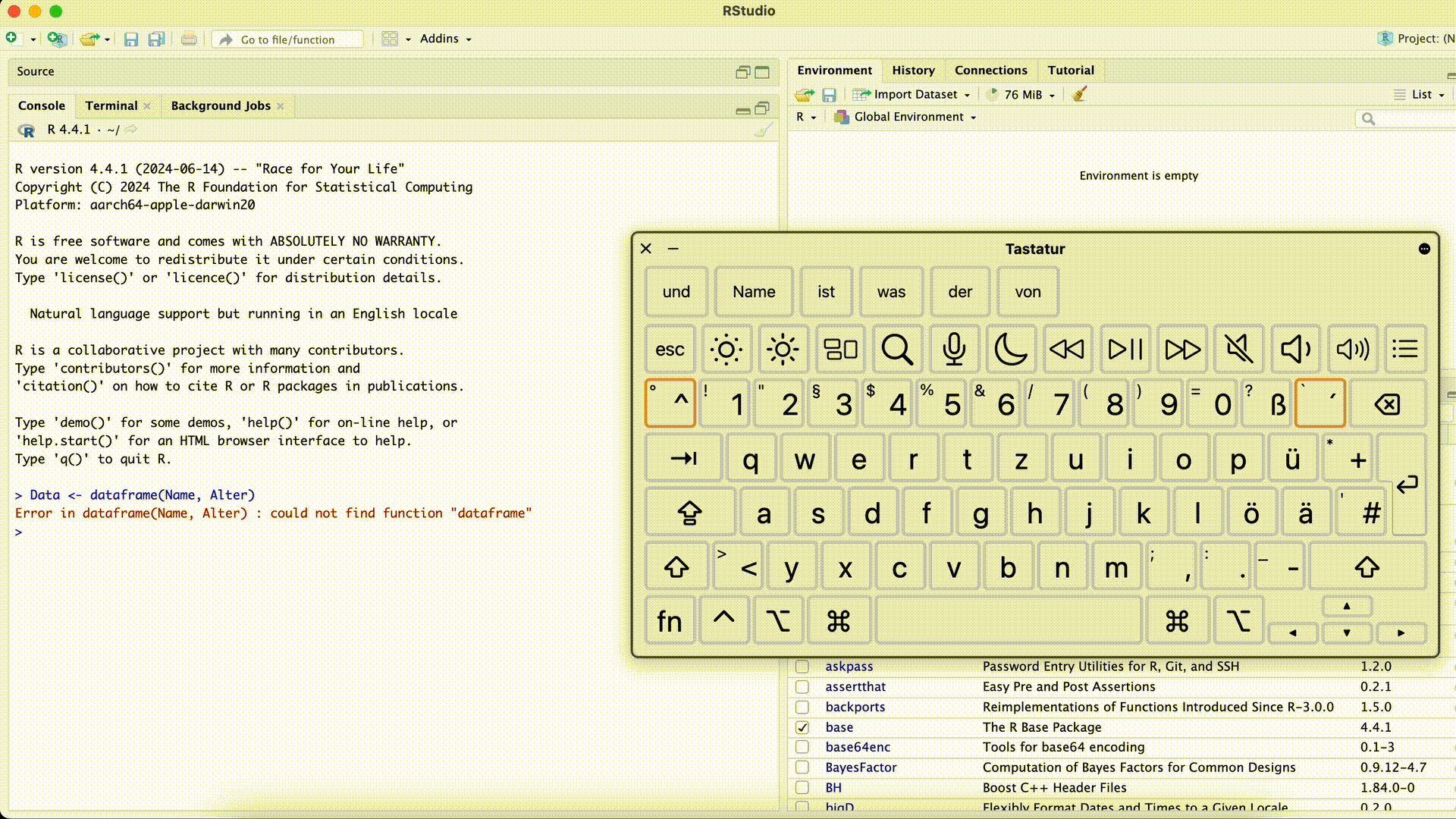
Hier könnte jetzt zweierlei passiert sein:
- Die Funktion ist falsch geschrieben (so wie in diesem Fall).
- Die Funktion ist richtig geschrieben, das Paket in dem sich die Funktion befindet, wurde aber noch nicht mittels library(PAKETNAME) geladen.