# Sie müssen das Paket ggplot2 installiert haben
install.packages("ggplot2")R Tutorial (Teil 2): Workflows bei der Arbeit mit Datensätzen
1 Workflow bisher
In Teil 1 unseres R Tutorials haben wir nicht nur die Grundlagen gelernt wie R funktioniert, sondern wir haben im Kapitel 2 Reproduzierbares Arbeiten mit RStudio auch schon ein paar Abläufe gelernt, wie man mit R und RStudio effizient arbeitet. Wenn Sie sich an die folgenden Themen nicht mehr erinnern können, empfehlen wir sehr diese nochmal zu wiederholen:
Wir haben gelernt…
- was ein R Skript ist und warum es nicht sinnvoll ist, alle Befehle direkt in die Console einzugeben.
- was der Workspace ist und haben RStudio so eingestellt, dass dieser beim Schließen des Programms nicht automatisch gespeichert wird.
- wie man R regelmäßig im Hintergrund neu startet und warum das wichtig ist um sicherzustellen, dass mein R Skript tatsächlich reproduzierbar ist.
Hier in Teil 2 wollen wir darauf aufbauend lernen, was ein RStudio Projekt ist und wie uns das dabei hilft, wenn wir mit R empirische Datensätze einlesen und analysieren wollen.
TippFür Interessierte: Weiterführende Literatur zu R
Für ausführlichere Informationen zu den hier behandelten und vielen weiteren Themen, empfehlen wir das frei verfügbare Onlinebuch R for Data Science (2e) von Hadley Wickham, Mine Çetinkaya-Rundel und Garrett Grolemund.
Wenn Sie schon viel Erfahrung mit anderen Programmiersprachen haben, oder Spaß daran haben, die Funktionsweise von R im größtmöglichen Detailgrad nachzuvollziehen, empfehlen wir das frei verfügbare Onlinebuch Advanced R von Hadley Wickham.
2 Workflow mit Projekten
2.1 Was ist ein RStudio Projekt?
Wenn wir in der Praxis mit R arbeiten, beinhaltet das eigentlich immer, einen Datensatz in R einzulesen um dann mit den Daten verschiedene Analysen durchzuführen. Solche Datensätze liegen typischerweise als Datei auf der Festplatte, z.B. eine Datei mit dem Namen Pounds.csv. Wenn wir den Datensatz einlesen wollen, müssen wir R sagen, wo diese Datei liegt. Das ist in der Praxis sehr umständlich und macht die Analyse fehleranfällig, wenn man z.B. das R Skript an eine Kollegin schicken möchte und diese Person natürlich eine andere Ordnerstruktur auf ihrem Computer hat. Es ist daher gute Praxis von Beginn an mit sogenannten Projekten zu arbeiten, die die Arbeit mit mehreren Dateien (was in der Praxis bei fast jeder Analyse relevant ist), enorm erleichtern.
Ein RStudio Projekt ist zunächst einfach ein neuer Ordner auf meiner Festplatte, der alle Dateien (R Skripte, Datensätze, Abbildungen, etc.) eines bestimmen Analyseprojekts (z.B. meine Abschlussarbeit) enthalten soll. Der RStudio Projektordner enthält dann zusätzlich noch eine Verknüpfung, mit der ich das Projekt in RStudio öffnen kann.
HinweisWie häufig erstelle ich ein neues Projekt?
Was genau inhaltlich ein neues “Projekt” ausmacht und wann es sich lohnt, für eine neue Analyse ein neues RStudio Projekt zu erstellen, kann man allgemein schwer sagen. Ziemlich sicher wäre ein einziges RStudio Projekt, dass alle statistischen Auswertung in Ihrem Studium enthält “zu groß”, aber ein RStudio Projekt, das nur das Material zu einem einzelnen Übungsblatt im Statistik Seminar enthält vermutlich “zu klein”.
Erfahrungsgemäß tendiert man am Anfang eher dazu, “zu große” RStudio Projekte zu erstellen. Um die Arbeit mit RStudio Projekten zu üben, empfehlen wir, dass Sie zumindest für jeden Themenbereich des Statistik Seminars ein eigenes RStudio Projekt erstellen.
2.2 Ein neues RStudio Projekt erstellen
Um in RStudio ein neues Projekt zu erstellen…
- klicken wir auf File > New Project,
- geben einen Namen für unseren Projektordner ein,
- wählen aus, wo wir den Projektordner auf unserem Computer speichern wollen und
- klicken auf Create Project.
Dieser Ablauf wird in Abbildung 1 dargestellt.
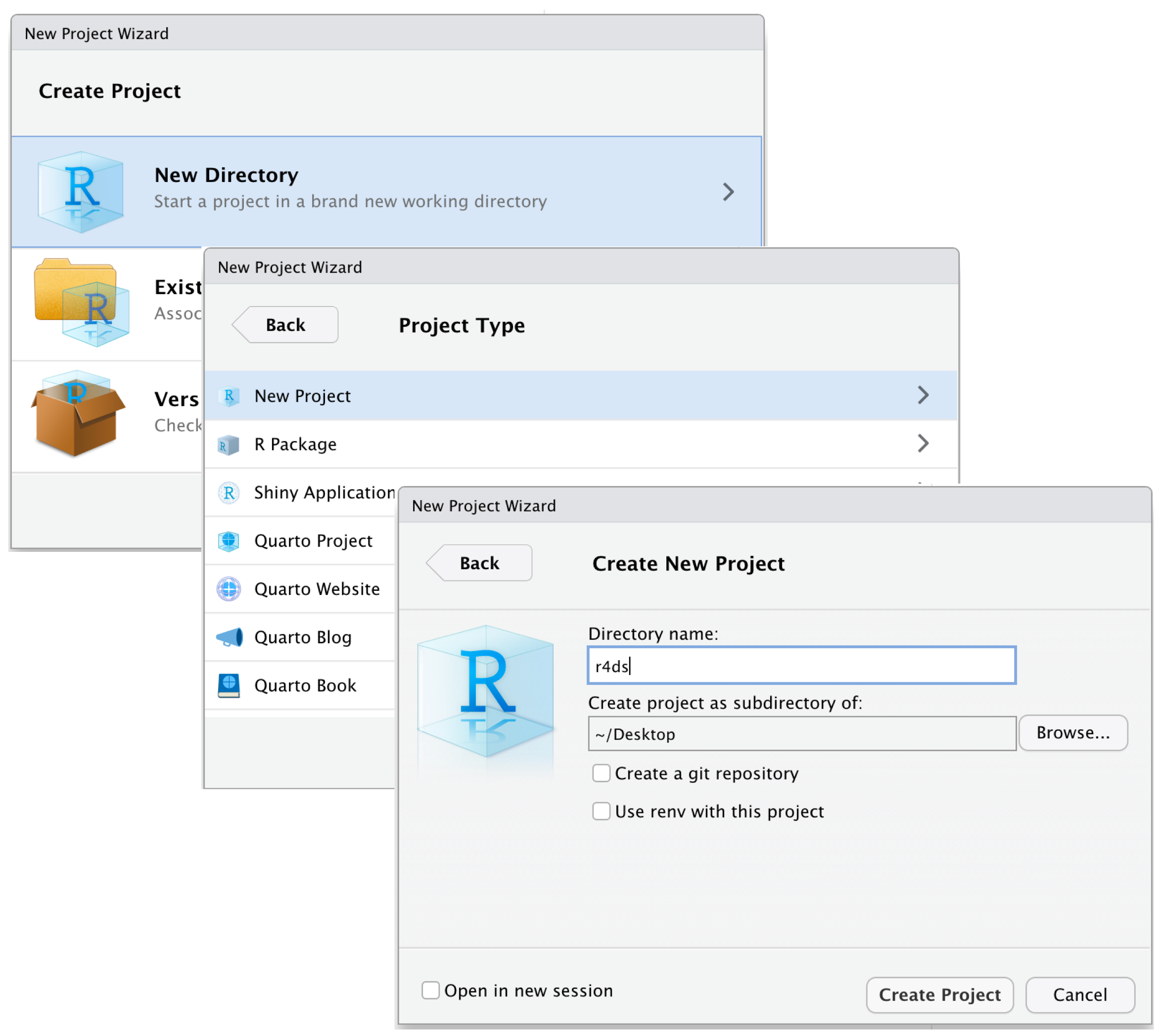
Nachdem wir das neue Projekt erstellt haben, sehen wir in RStudio im Files Fenster den Projektordner. Zu Beginn enthält der Ordner nur eine Verknüpfung, das heißt eine Datei mit der Dateiendung .Rproj die genauso heißt wie der Projektordner. Wenn wir RStudio schließen, können wir das Projekt wieder öffnen, indem wir auf unserem Computer die .Rproj Datei des Projekts doppelklicken.
Wenn wir mit RStudio ein Projekt geöffnet haben und eine Datei speichern, z.B. ein R Skript oder eine Abbildung, werden diese Dateien standardmäßig im Projektordner gespeichert. Dadurch ist es sehr einfach alle Dateien, die zu dem Projekt gehören, zusammen zu halten.
VorsichtProbieren Sie es aus!
Erstellen Sie ein neues RStudio Projekt mit Namen
R_Intro(oder einem anderen Namen, der Ihnen besser gefällt). Überlegen Sie sich, wo genau Sie das Projekt sinnvollerweise auf Ihrem Rechner speichern, damit Sie den Ordner leicht wieder finden, wenn Sie das Projekt das nächste mal öffnen wollen.Schließen Sie RStudio.
Laden Sie sich hier die Datei
msleep.Rherunter und verschieben Sie die Datei in den neu erstellten Projektordner. (Hinweis: Wenn sich beim herunterladen die Datei stattdessen in Ihrem Browser öffnet, gehen Sie zurück zum Link und machen Rechtsklick > Ziel speichern unter)Öffnen Sie das Projekt, indem Sie auf die
R_Intro.RprojDatei doppelklicken.Überprüfen Sie, dass Sie die heruntergeladene Datei im Files Fenster in RStudio sehen.
Klicken Sie im Files Fenster auf das R Skript
msleep.R.Führen Sie die Befehle im Skript
msleep.Raus. Es ist egal, dass Sie nicht verstehen was alle Befehle genau bedeuten. Wenn ein Fehler auftaucht, liegt es daran, dass Ihnen ein bestimmtes R Paket fehlt. Finden Sie mithilfe der Informationen im R Skript heraus, welches Paket Ihnen fehlt, installieren Sie es und führen Sie die Befehle im Skript erneut aus.Lösung
Betrachten Sie das Files Fenster in RStudio und stellen Sie fest, was sich in Ihrem Projektordner verändert hat.
Lösung
Das Skript hat zwei neue Dateien erstellt und abgespeichert: Den Datensatz
msleep.csvund die Abbildungmsleep.png. Als Speicherort wurde automatisch der Projektordner gewählt.
Lösung als GIF
3 Workflow zum Einlesen von Datensätzen
3.1 Datensatz im .csv Format einlesen
Datensätze liegen häufig in Dateien der Formate .csv, .xlsx oder .sav vor. Für jedes dieser Formate (und viele weitere) gibt es in R Funktionen um solche Dateien einzulesen. Wir werden uns hier zunächst nur mit .csv Dateien beschäftigen.
Das csv-Format benutzt in der englischen Standardvariante das Komma (,) um Einträge unterschiedlicher Zellen einer Tabelle voneinander zu trennen. Entsprechend müssen Kommastellen von Dezimalzahlen mit einem Punkt (.) beginnen. Häufig verwenden Programme in der deutschen Spracheinstellung ein leicht anderes Format, das Zellen mit einem Strichpunkt (;) und Dezimalstellen mit einem Komma (,) voneinander trennt.
Beide Arten von csv-Dateien können in R problemlos eingelesen werden. Die unterschiedliche Konfiguration der Trennzeichen muss jedoch berücksichtigt werden. Für die englische Variante gibt es die Funktion read.csv() und für die deutsche Variante die Funktion read.csv2(). Wird die falsche Funktion zum Einlesen verwendet, liegen die Daten in R in keinem sinnvollen Format vor.
Um einen Datensatz einzulesen, müssen wir im R Befehl den Dateipfad angeben, das heißt wie die Datei heißt und wo die Datei auf dem Computer genau liegt. Wenn wir uns aber 1. in einem RStudio Projekt befinden und 2. die Datei direkt im Projektordner liegt, dann reicht es beim Einlesen aus, nur den Namen der Datei (inklusive Dateiendung) anzugeben.
Als Beispiel können wir uns hier den Datensatz Pounds.csv herunterladen, in den Projektordner verschieben und mit der Funktion read.csv2() in R einlesen. Die so eingelesenen Daten können wir dann mit <- einem Objekt pounds zuweisen, um dann in R mit den Daten weiterarbeiten zu können. Zum Beispiel können wir uns mit der Funktion head() die ersten 6 Zeilen des Datensatzes ansehen:
pounds <- read.csv2("Pounds.csv")
head(pounds) group treat motivat pounds
1 1 0 4 15
2 1 0 4 17
3 1 0 4 15
4 1 0 4 17
5 1 0 4 16
6 1 0 6 18Falls wir uns nicht sicher sind, in welchem csv-Format die Daten abgespeichert sind, können wir einfach beide Funktionen (read.csv() und read.csv2()) ausprobieren und sehen, welche die Daten im gewünschten Format einliest.
WarnungDie Numbers App auf dem Mac zerstört .csv Dateien!
Bei vielen Macs ist die App Numbers das Standardprogramm, wenn Sie versuchen außerhalb von RStudio eine .csv-Datei zu öffnen, z.B. indem Sie im Finder auf eine csv-Datei doppelklicken. Aus Gründen, die niemand versteht, verändert die Numbers App jede geöffnete csv-Datei so, dass die Datei mit R nicht mehr normal eingelesen werden kann. Die Veränderung der Datei passiert bereits durch das Öffnen, also sogar wenn Sie die Datei nach dem Öffnen gar nicht neu abspeichern.
Aus diesem ärgerlichen Grund müssen Sie leider verhindern, eine csv-Datei mit Numbers zu öffnen. Sollte Ihnen das in unserem Seminar doch mal aus Versehen passieren, empfehlen wir Ihnen die Datei einfach nochmal neu herunterzuladen. Sollte Numbers auf Ihrem Mac das Standardprogramm zum Öffnen von csv-Dateien sein, empfehlen wir Ihnen, stattdessen ein anderes Standardprogramm festzulegen. Eine Anleitung zur Änderung der Standardprogramme auf dem Mac finden Sie hier.
3.2 Das Working Directory…
…oder: “Warum reicht es in einem RStudio Projekt, beim Einlesen von Dateien nur den Namen der Datei anzugeben?”
Wenn wir in R arbeiten, gibt es immer einen Ordner auf unserem Computer, in dem R nach Dateien sucht (z.B. wenn diese eingelesen werden sollen) oder Dateien abspeichert (z.B. wenn eine mit R erstellte Grafik gespeichert werden soll). Dieser Ort heißt Working Directory (oder auf Deutsch Arbeitsverzeichnis).
In einem RStudio Projekt ist automatisch der Projektordner als Working Directory eingestellt. Wenn wir eine Datei einlesen wollen, müssen wir den Dateipfad immer nur ausgehend vom Working Directory angeben. Das bedeutet:
- Wenn die Datei direkt im Projektordner liegt, reicht es also aus, beim Einlesen nur den Namen der Datei (inklusive Dateiendung) anzugeben, z.B.
pounds <- read.csv2("Pounds.csv"). - Wenn die Datei im Projektordner nochmal in einem Unterordner liegt (z.B. ein Ordner Namens
data), muss man den Unterordner in den Dateipfad mit aufnehmen, alsopounds <- read.csv2("data/Pounds.csv").
Hier wird der große Vorteil von RStudio Projekten deutlich:
Wenn alle Dateien im Projektordner liegen, funktionieren unsere Analysen unabhängig davon, wo auf dem Computer der Projektordner genau liegt. Das bedeutet, wir können den Projektordner auf unserem Computer beliebig verschieben oder auch als Email an unsere Kolleginnen versenden.
HinweisWorking Directory überprüfen
Wo das Working Directory zu einem bestimmten Zeitpunkt genau liegt, sehen wir entweder wie in Abbildung 2 dargestellt am Kopf des Fensters Console oder indem wir den R Befehl getwd() ausführen.

VorsichtProbieren Sie es aus!
Laden Sie sich hier die Datei
HSB.csvherunter und verschieben Sie die Datei in den Projektordner.Lesen Sie die Datei
HSB.csvmit der Funktionread.csv2()ein und weisen Sie die Daten dem Objekthsbzu.Erstellen Sie eine Zusammenfassung aller Variablen im HSB Datensatz mit dem Befehl
summary(hsb).Lösung
hsb <- read.csv2("HSB.csv") summary(hsb)School Minority Sex SES Min. :1224 Length:7185 Length:7185 Min. :-3.760000 1st Qu.:3020 Class :character Class :character 1st Qu.:-0.540000 Median :5192 Mode :character Mode :character Median : 0.000000 Mean :5278 Mean :-0.001857 3rd Qu.:7342 3rd Qu.: 0.600000 Max. :9586 Max. : 2.690000 MathAch Size Sector PRACAD Min. :-2.83 Min. : 100 Length:7185 Min. :0.0000 1st Qu.: 7.28 1st Qu.: 565 Class :character 1st Qu.:0.3200 Median :13.13 Median :1016 Mode :character Median :0.5300 Mean :12.75 Mean :1057 Mean :0.5345 3rd Qu.:18.32 3rd Qu.:1436 3rd Qu.:0.7000 Max. :24.99 Max. :2713 Max. :1.0000 DISCLIM MeanSES Min. :-2.4200 Min. :-1.190000 1st Qu.:-0.8200 1st Qu.:-0.320000 Median :-0.2300 Median : 0.040000 Mean :-0.1319 Mean : 0.006224 3rd Qu.: 0.4600 3rd Qu.: 0.330000 Max. : 2.7600 Max. : 0.830000In der 7. Übung im Abschnitt 2.2 wurde in Ihrem Projektordner die Datei
msleep.csverstellt. Wenn sie diese Datei nicht haben, können Sie die Datei stattdessen hier herunterladen. Lesen Sie die Dateimsleep.csvein und weisen Sie die Daten dem Objektmsleep_datazu. Probieren Sie aus, welche der beiden read.csv Funktionen geeignet ist, um den Datensatz einzulesen.Lösung
msleep_data <- read.csv("msleep.csv") head(msleep_data)name genus vore order conservation 1 Cheetah Acinonyx carni Carnivora lc 2 Owl monkey Aotus omni Primates <NA> 3 Mountain beaver Aplodontia herbi Rodentia nt 4 Greater short-tailed shrew Blarina omni Soricomorpha lc 5 Cow Bos herbi Artiodactyla domesticated 6 Three-toed sloth Bradypus herbi Pilosa <NA> sleep_total sleep_rem sleep_cycle awake brainwt bodywt 1 12.1 NA NA 11.9 NA 50.000 2 17.0 1.8 NA 7.0 0.01550 0.480 3 14.4 2.4 NA 9.6 NA 1.350 4 14.9 2.3 0.1333333 9.1 0.00029 0.019 5 4.0 0.7 0.6666667 20.0 0.42300 600.000 6 14.4 2.2 0.7666667 9.6 NA 3.850Berechnen Sie den Mittelwert der Spalte
sleep_total.Lösung
mean(msleep_data$sleep_total)[1] 10.43373Bonus: Berechnen Sie den Mittelwert der Spalte
sleep_totalnur für die Zeilen des Datensatzes, bei denen in der Spalteorderder Wert"Primates"steht.Lösung
mean(msleep_data[msleep_data$order == "Primates", "sleep_total"])[1] 10.5Bonus - Open End: Der Online-Speicherdienst Zenodo wird von vielen Wissenschaftlerinnen genutzt, um Forschungsdaten öffentlich zur Verfügung zu stellen. Falls Sie das Einlesen von Datensätze an noch mehr Beispielen üben wollen, finden Sie unter diesem Link viele aktuelle psychologische Datensätze im .csv Format.